 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Relationship Forecasting in Videos
Jul 02, 2021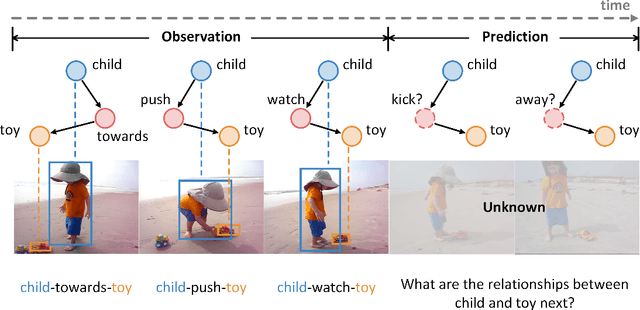

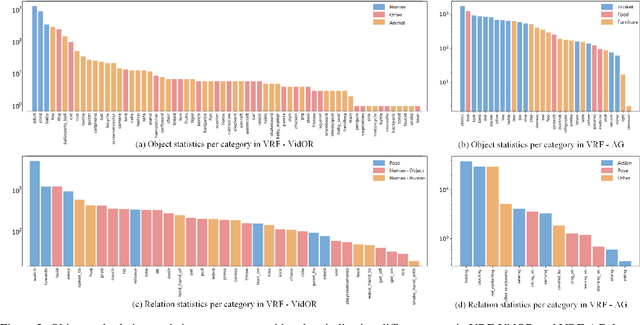
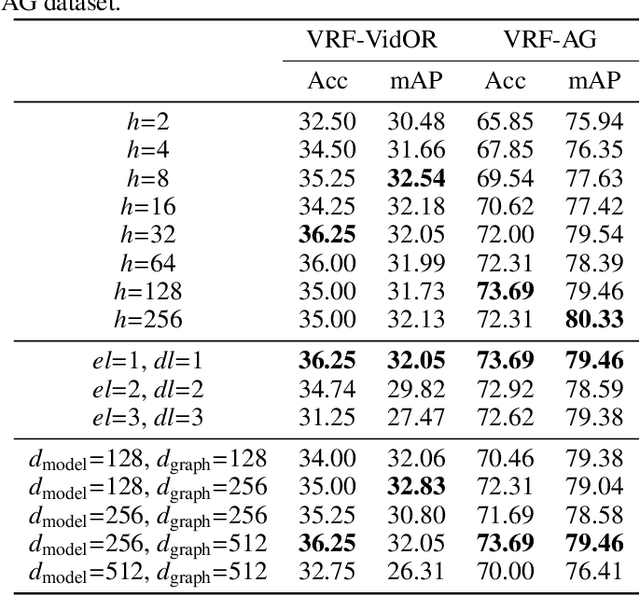
Real-world scenarios often require the anticipation of object interactions in unknown future, which would assist the decision-making process of both humans and agents. To meet this challenge, we present a new task named Visual Relationship Forecasting (VRF) in videos to explore the prediction of visual relationships in a reasoning manner. Specifically, given a subject-object pair with H existing frames, VRF aims to predict their future interactions for the next T frames without visual evidence. To evaluate the VRF task, we introduce two video datasets named VRF-AG and VRF-VidOR, with a series of spatio-temporally localized visual relation annotations in a video. These two datasets densely annotate 13 and 35 visual relationships in 1923 and 13447 video clips, respectively. In addition, we present a novel Graph Convolutional Transformer (GCT) framework, which captures both object-level and frame-level dependencies by spatio-temporal Graph Convolution Network and Transformer. Experimental results on both VRF-AG and VRF-VidOR datasets demonstrate that GCT outperforms the state-of-the-art sequence modelling methods on visual relationship forecasting.