 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Object Detection with Single Point Supervision
Dec 08, 2024



Tiny objects, with their limited spatial resolution, often resemble point-like distributions. As a result, bounding box prediction using point-level supervision emerges as a natural and cost-effective alternative to traditional box-level supervision. However, the small scale and lack of distinctive features of tiny objects make point annotations prone to noise, posing significant hurdles for model robustness. To tackle these challenges, we propose Point Teacher--the first end-to-end point-supervised method for robust tiny object detection in aerial images. To handle label noise from scale ambiguity and location shifts in point annotations, Point Teacher employs the teacher-student architecture and decouples the learning into a two-phase denoising process. In this framework, the teacher network progressively denoises the pseudo boxes derived from noisy point annotations, guiding the student network's learning. Specifically, in the first phase, random masking of image regions facilitates regression learning, enabling the teacher to transform noisy point annotations into coarse pseudo boxes. In the second phase, these coarse pseudo boxes are refined using dynamic multiple instance learning, which adaptively selects the most reliable instance from dynamically constructed proposal bags around the coarse pseudo boxes. Extensive experiments on three tiny object datasets (i.e., AI-TOD-v2, SODA-A, and TinyPerson) validate the proposed method's effectiveness and robustness against point location shifts. Notably, relying solely on point supervision, our Point Teacher already shows comparable performance with box-supervised learning methods. Codes and models will be made publicly available.
Unsupervised Multi-view UAV Image Geo-localization via Iterative Rendering
Nov 22, 2024



Unmanned Aerial Vehicle (UAV) Cross-View Geo-Localization (CVGL) presents significant challenges due to the view discrepancy between oblique UAV images and overhead satellite images. Existing methods heavily rely on the supervision of labeled datasets to extract viewpoint-invariant features for cross-view retrieval. However, these methods have expensive training costs and tend to overfit the region-specific cues, showing limited generalizability to new regions. To overcome this issue, we propose an unsupervised solution that lifts the scene representation to 3d space from UAV observations for satellite image generation, providing robust representation against view distortion. By generating orthogonal images that closely resemble satellite views, our method reduces view discrepancies in feature representation and mitigates shortcuts in region-specific image pairing. To further align the rendered image's perspective with the real one, we design an iterative camera pose updating mechanism that progressively modulates the rendered query image with potential satellite targets, eliminating spatial offsets relative to the reference images. Additionally, this iterative refinement strategy enhances cross-view feature invariance through view-consistent fusion across iterations. As such, our unsupervised paradigm naturally avoids the problem of region-specific overfitting, enabling generic CVGL for UAV images without feature fine-tuning or data-driven training. Experiments on the University-1652 and SUES-200 datasets demonstrate that our approach significantly improves geo-localization accuracy while maintaining robustness across diverse regions. Notably, without model fine-tuning or paired training, our method achieves competitive performance with recent supervised methods.
Video Frame Interpolation with Stereo Event and Intensity Camera
Jul 17, 2023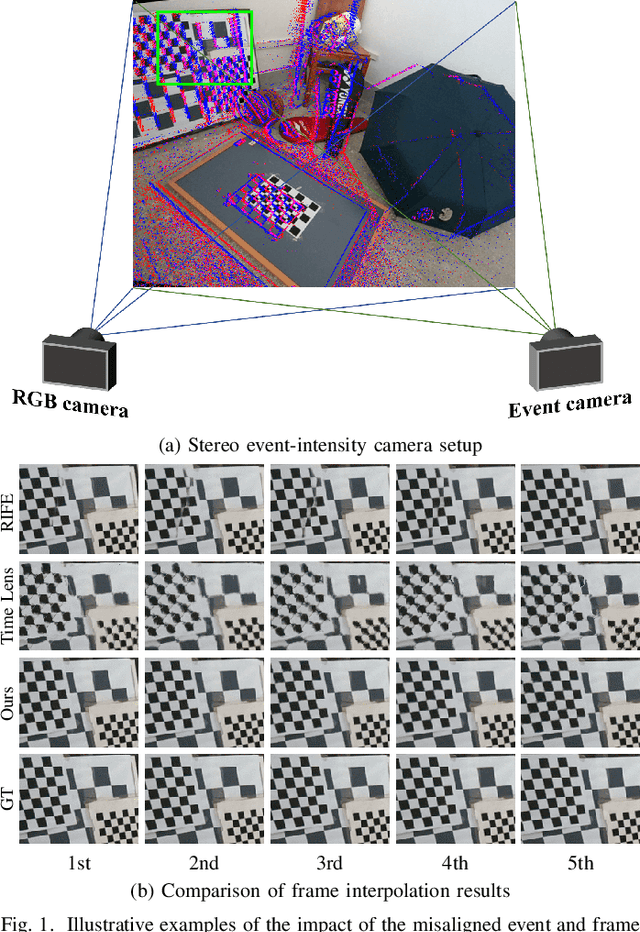



The stereo event-intensity camera setup is widely applied to leverage the advantages of both event cameras with low latency and intensity cameras that capture accurate brightness and texture information. However, such a setup commonly encounters cross-modality parallax that is difficult to be eliminated solely with stereo rectification especially for real-world scenes with complex motions and varying depths, posing artifacts and distortion for existing Event-based Video Frame Interpolation (E-VFI) approaches. To tackle this problem, we propose a novel Stereo Event-based VFI (SE-VFI) network (SEVFI-Net) to generate high-quality intermediate frames and corresponding disparities from misaligned inputs consisting of two consecutive keyframes and event streams emitted between them. Specifically, we propose a Feature Aggregation Module (FAM) to alleviate the parallax and achieve spatial alignment in the feature domain. We then exploit the fused features accomplishing accurate optical flow and disparity estimation, and achieving better interpolated results through flow-based and synthesis-based ways. We also build a stereo visual acquisition system composed of an event camera and an RGB-D camera to collect a new Stereo Event-Intensity Dataset (SEID) containing diverse scenes with complex motions and varying depths. Experiments on public real-world stereo datasets, i.e., DSEC and MVSEC, and our SEID dataset demonstrate that our proposed SEVFI-Net outperforms state-of-the-art methods by a large margin.
"Seeing'' Electric Network Frequency from Events
May 04, 2023Most of the artificial lights fluctuate in response to the grid's alternating current and exhibit subtle variations in terms of both intensity and spectrum, providing the potential to estimate the Electric Network Frequency (ENF) from conventional frame-based videos. Nevertheless, the performance of Video-based ENF (V-ENF) estimation largely relies on the imaging quality and thus may suffer from significant interference caused by non-ideal sampling, motion, and extreme lighting conditions. In this paper, we show that the ENF can be extracted without the above limitations from a new modality provided by the so-called event camera, a neuromorphic sensor that encodes the light intensity variations and asynchronously emits events with extremely high temporal resolution and high dynamic range. Specifically, we first formulate and validate the physical mechanism for the ENF captured in events, and then propose a simple yet robust Event-based ENF (E-ENF) estimation method through mode filtering and harmonic enhancement. Furthermore, we build an Event-Video ENF Dataset (EV-ENFD) that records both events and videos in diverse scenes. Extensive experiments on EV-ENFD demonstrate that our proposed E-ENF method can extract more accurate ENF traces, outperforming the conventional V-ENF by a large margin, especially in challenging environments with object motions and extreme lighting conditions. The code and dataset are available at https://xlx-creater.github.io/E-ENF.
Learning to Super-Resolve Blurry Images with Events
Feb 27, 2023



Super-Resolution from a single motion Blurred image (SRB) is a severely ill-posed problem due to the joint degradation of motion blurs and low spatial resolution. In this paper, we employ events to alleviate the burden of SRB and propose an Event-enhanced SRB (E-SRB) algorithm, which can generate a sequence of sharp and clear images with High Resolution (HR) from a single blurry image with Low Resolution (LR). To achieve this end, we formulate an event-enhanced degeneration model to consider the low spatial resolution, motion blurs, and event noises simultaneously. We then build an event-enhanced Sparse Learning Network (eSL-Net++) upon a dual sparse learning scheme where both events and intensity frames are modeled with sparse representations. Furthermore, we propose an event shuffle-and-merge scheme to extend the single-frame SRB to the sequence-frame SRB without any additional training process. Experimental results on synthetic and real-world datasets show that the proposed eSL-Net++ outperforms state-of-the-art methods by a large margin. Datasets, codes, and more results are available at https://github.com/ShinyWang33/eSL-Net-Plusplus.
Towards End-to-End Synthetic Speech Detection
Jun 11, 2021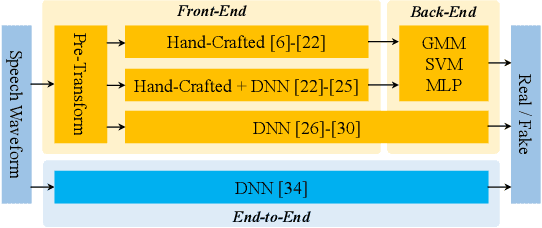
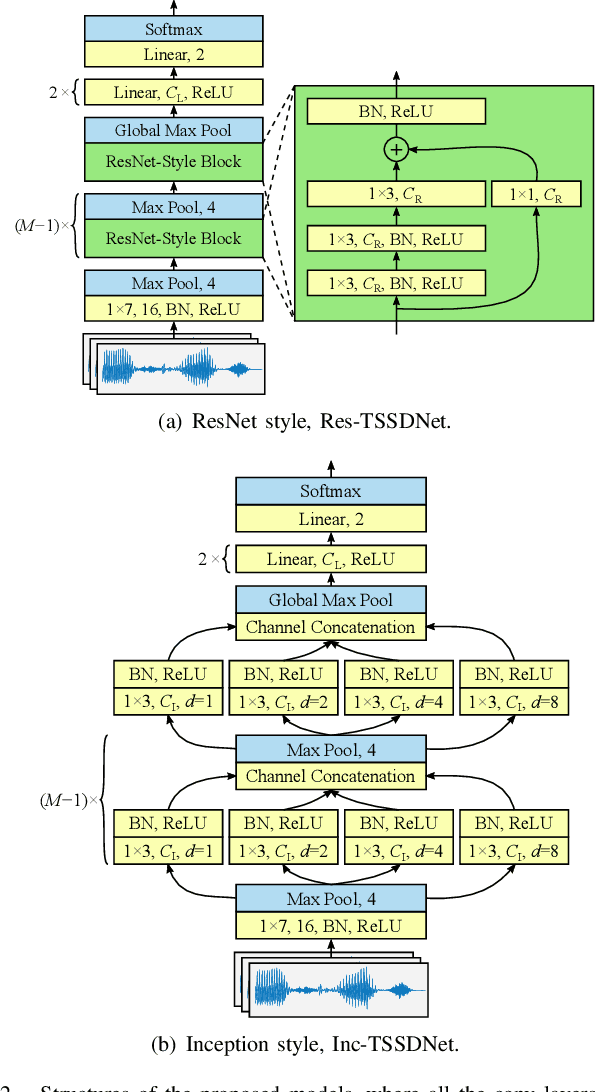
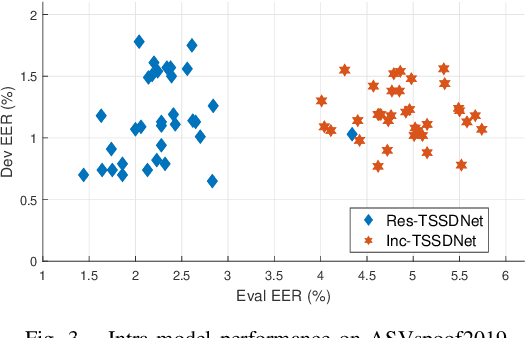
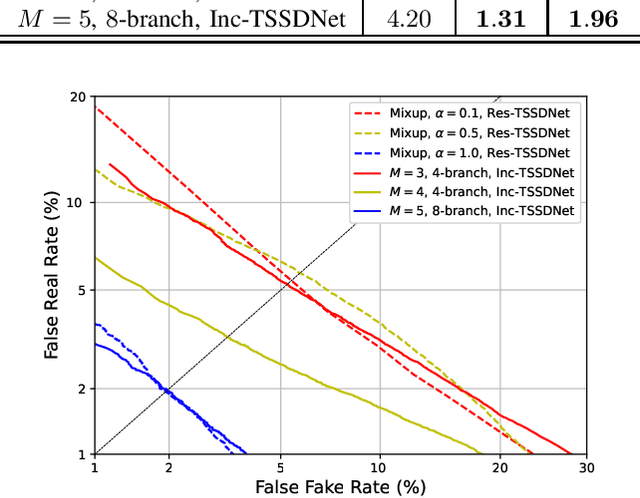
The constant Q transform (CQT) has been shown to be one of the most effective speech signal pre-transforms to facilitate synthetic speech detection, followed by either hand-crafted (subband) constant Q cepstral coefficient (CQCC) feature extraction and a back-end binary classifier, or a deep neural network (DNN) directly for further feature extraction and classification. Despite the rich literature on such a pipeline, we show in this paper that the pre-transform and hand-crafted features could simply be replaced by end-to-end DNNs. Specifically, we experimentally verify that by only using standard components, a light-weight neural network could outperform the state-of-the-art methods for the ASVspoof2019 challenge. The proposed model is termed Time-domain Synthetic Speech Detection Net (TSSDNet), having ResNet- or Inception-style structures. We further demonstrate that the proposed models also have attractive generalization capability. Trained on ASVspoof2019, they could achieve promising detection performance when tested on disjoint ASVspoof2015, significantly better than the existing cross-dataset results. This paper reveals the great potential of end-to-end DNNs for synthetic speech detection, without hand-crafted features.
Learning Cluster Structured Sparsity by Reweighting
Oct 11, 2019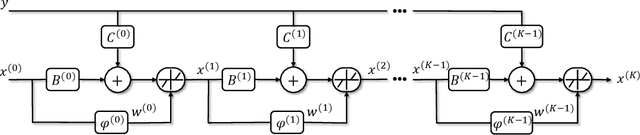
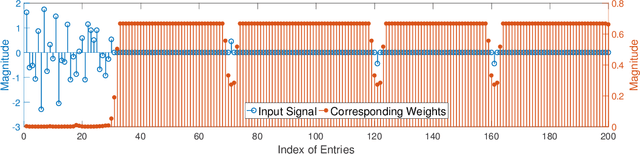
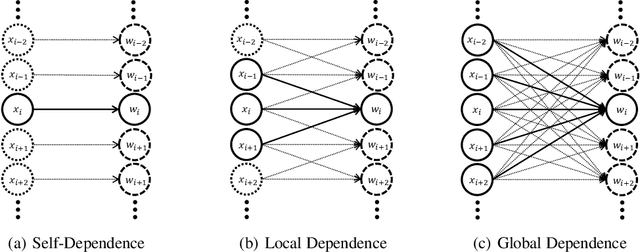
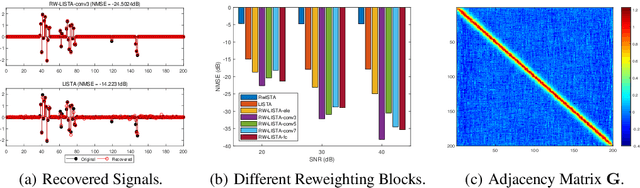
Recently, the paradigm of unfolding iterative algorithms into finite-length feed-forward neural networks has achieved a great success in the area of sparse recovery. Benefit from available training data, the learned networks have achieved state-of-the-art performance in respect of both speed and accuracy. However, the structure behind sparsity, imposing constraint on the support of sparse signals, is often an essential prior knowledge but seldom considered in the existing networks. In this paper, we aim at bridging this gap. Specifically, exploiting the iterative reweighted $\ell_1$ minimization (IRL1) algorithm, we propose to learn the cluster structured sparsity (CSS) by rewegihting adaptively. In particular, we first unfold the Reweighted Iterative Shrinkage Algorithm (RwISTA) into an end-to-end trainable deep architecture termed as RW-LISTA. Then instead of the element-wise reweighting, the global and local reweighting manner are proposed for the cluster structured sparse learning. Numerical experiments further show the superiority of our algorithm against both classical algorithms and learning-based networks on different tasks.
Facial Feature Embedded CycleGAN for VIS-NIR Translation
Apr 25, 2019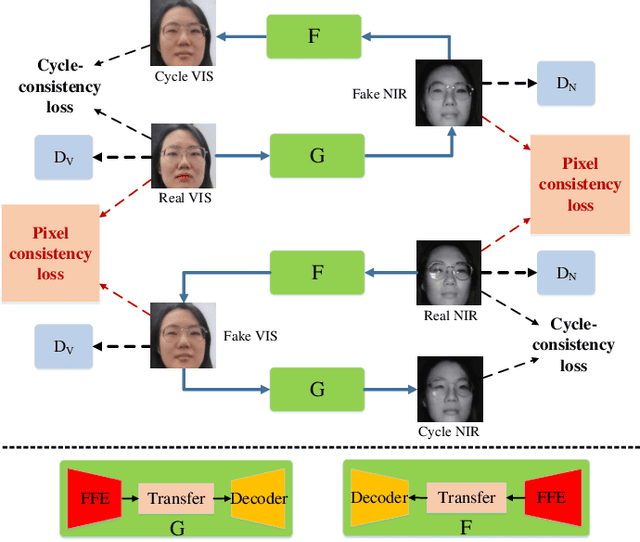
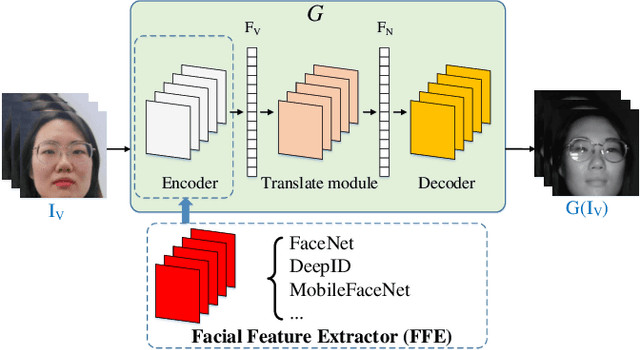
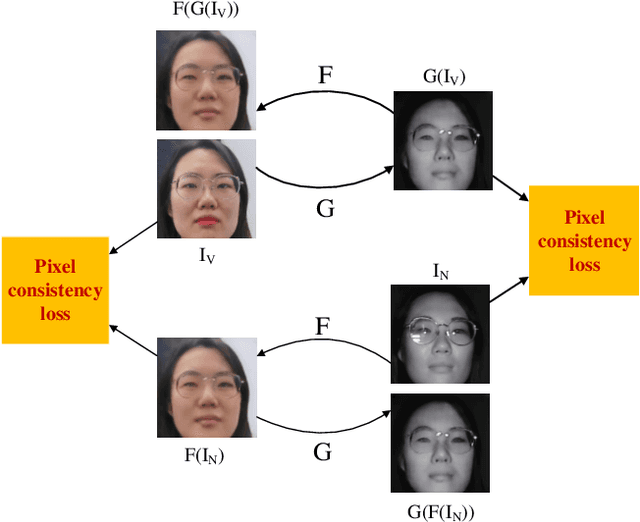

VIS-NIR face recognition remains a challenging task due to the distinction between spectral components of two modalities and insufficient paired training data. Inspired by the CycleGAN, this paper presents a method aiming to translate VIS face images into fake NIR images whose distributions are intended to approximate those of true NIR images, which is achieved by proposing a new facial feature embedded CycleGAN. Firstly, to learn the particular feature of NIR domain while preserving common facial representation between VIS and NIR domains, we employ a general facial feature extractor (FFE) to replace the encoder in the original generator of CycleGAN. For implementing the facial feature extractor, herein the MobileFaceNet is pretrained on a VIS face database, and is able to extract effective features. Secondly, the domain-invariant feature learning is enhanced by considering a new pixel consistency loss. Lastly, we establish a new WHU VIS-NIR database which varies in face rotation and expressions to enrich the training data. Experimental results on the Oulu-CASIA NIR-VIS database and the WHU VIS-NIR database show that the proposed FFE-based CycleGAN (FFE-CycleGAN) outperforms state-of-the-art VIS-NIR face recognition methods and achieves 96.5\% accuracy.