 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards End-to-End Synthetic Speech Detection
Paper and Code
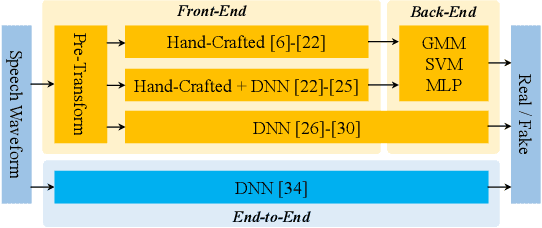
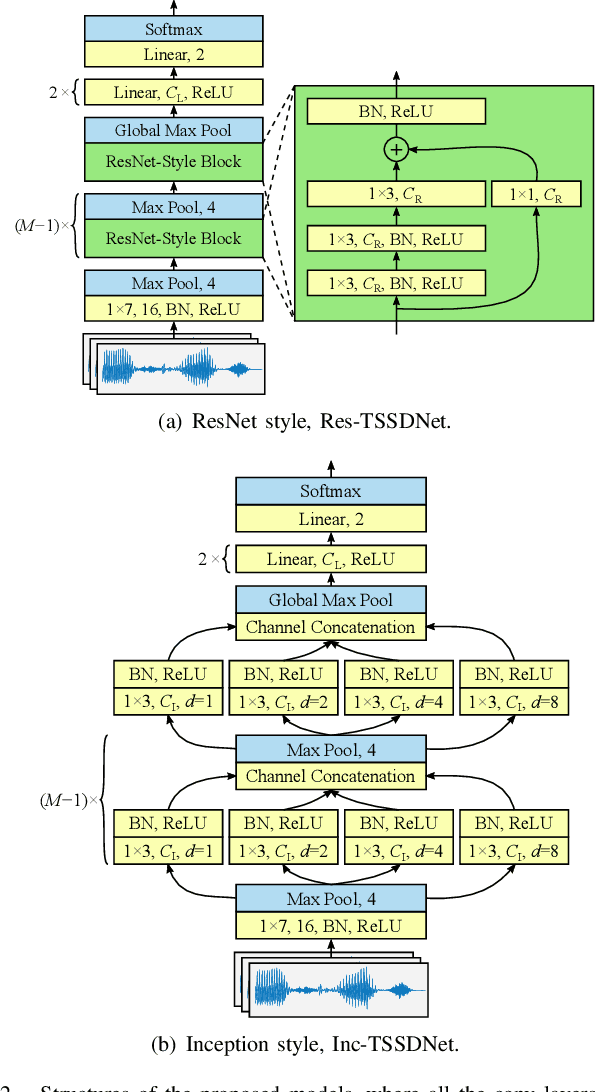
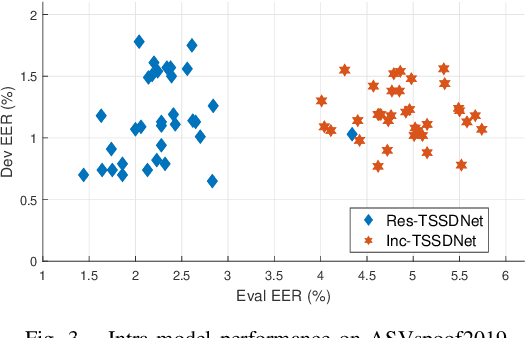
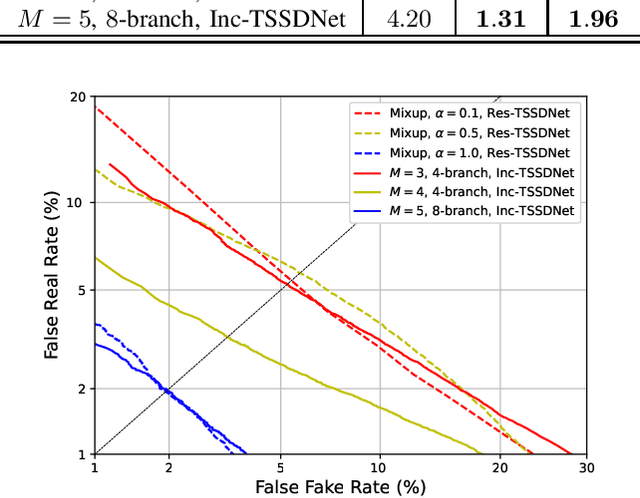
The constant Q transform (CQT) has been shown to be one of the most effective speech signal pre-transforms to facilitate synthetic speech detection, followed by either hand-crafted (subband) constant Q cepstral coefficient (CQCC) feature extraction and a back-end binary classifier, or a deep neural network (DNN) directly for further feature extraction and classification. Despite the rich literature on such a pipeline, we show in this paper that the pre-transform and hand-crafted features could simply be replaced by end-to-end DNNs. Specifically, we experimentally verify that by only using standard components, a light-weight neural network could outperform the state-of-the-art methods for the ASVspoof2019 challenge. The proposed model is termed Time-domain Synthetic Speech Detection Net (TSSDNet), having ResNet- or Inception-style structures. We further demonstrate that the proposed models also have attractive generalization capability. Trained on ASVspoof2019, they could achieve promising detection performance when tested on disjoint ASVspoof2015, significantly better than the existing cross-dataset results. This paper reveals the great potential of end-to-end DNNs for synthetic speech detection, without hand-crafted features.