 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Exposure Imaging with Events
Apr 11, 2026By combining complementary benefits of short- and long-exposure images, Dual-Exposure Imaging (DEI) enhances image quality in low-light scenarios. However, existing DEI approaches inevitably suffer from producing artifacts due to spatial displacement from scene motion and image feature discrepancies from different exposure times. To tackle this problem, we propose a novel Event-based DEI (E-DEI) algorithm, which reconstructs high-quality images from dual-exposure image pairs and events, leveraging high temporal resolution of event cameras to provide accurate inter-/intra-frame dynamic information. Specifically, we decompose this complex task into an integration of two sub-tasks, i.e., event-based motion deblurring and low-light image enhancement tasks, which guides us to design E-DEI network as a dual-path parallel feature propagation architecture. We propose a Dual-path Feature Alignment and Fusion (DFAF) module to effectively align and fuse features extracted from dual-exposure images with assistance of events. Furthermore, we build a real-world Dataset containing Paired low-/normal-light Images and Events (PIED). Experiments on multiple datasets show the superiority of our method. The code and dataset are available at github.
Super-Resolving Blurry Images with Events
May 11, 2024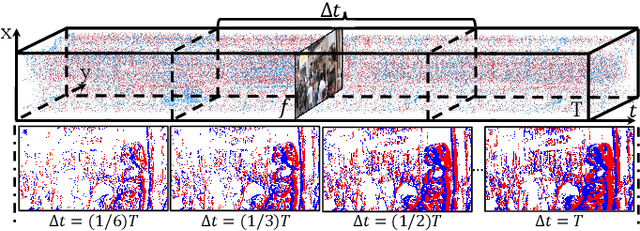
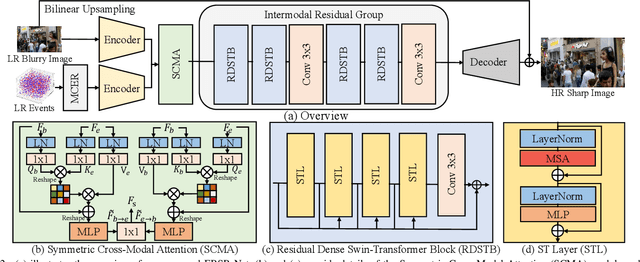


Super-resolution from motion-blurred images poses a significant challenge due to the combined effects of motion blur and low spatial resolution. To address this challenge, this paper introduces an Event-based Blurry Super Resolution Network (EBSR-Net), which leverages the high temporal resolution of events to mitigate motion blur and improve high-resolution image prediction. Specifically, we propose a multi-scale center-surround event representation to fully capture motion and texture information inherent in events. Additionally, we design a symmetric cross-modal attention module to fully exploit the complementarity between blurry images and events. Furthermore, we introduce an intermodal residual group composed of several residual dense Swin Transformer blocks, each incorporating multiple Swin Transformer layers and a residual connection, to extract global context and facilitate inter-block feature aggregation. Extensive experiments show that our method compares favorably against state-of-the-art approaches and achieves remarkable performance.
Learning Monocular Depth from Focus with Event Focal Stack
May 11, 2024Depth from Focus estimates depth by determining the moment of maximum focus from multiple shots at different focal distances, i.e. the Focal Stack. However, the limited sampling rate of conventional optical cameras makes it difficult to obtain sufficient focus cues during the focal sweep. Inspired by biological vision, the event camera records intensity changes over time in extremely low latency, which provides more temporal information for focus time acquisition. In this study, we propose the EDFF Network to estimate sparse depth from the Event Focal Stack. Specifically, we utilize the event voxel grid to encode intensity change information and project event time surface into the depth domain to preserve per-pixel focal distance information. A Focal-Distance-guided Cross-Modal Attention Module is presented to fuse the information mentioned above. Additionally, we propose a Multi-level Depth Fusion Block designed to integrate results from each level of a UNet-like architecture and produce the final output. Extensive experiments validate that our method outperforms existing state-of-the-art approaches.
Non-Uniform Exposure Imaging via Neuromorphic Shutter Control
Apr 22, 2024



By leveraging the blur-noise trade-off, imaging with non-uniform exposures largely extends the image acquisition flexibility in harsh environments. However, the limitation of conventional cameras in perceiving intra-frame dynamic information prevents existing methods from being implemented in the real-world frame acquisition for real-time adaptive camera shutter control. To address this challenge, we propose a novel Neuromorphic Shutter Control (NSC) system to avoid motion blurs and alleviate instant noises, where the extremely low latency of events is leveraged to monitor the real-time motion and facilitate the scene-adaptive exposure. Furthermore, to stabilize the inconsistent Signal-to-Noise Ratio (SNR) caused by the non-uniform exposure times, we propose an event-based image denoising network within a self-supervised learning paradigm, i.e., SEID, exploring the statistics of image noises and inter-frame motion information of events to obtain artificial supervision signals for high-quality imaging in real-world scenes. To illustrate the effectiveness of the proposed NSC, we implement it in hardware by building a hybrid-camera imaging prototype system, with which we collect a real-world dataset containing well-synchronized frames and events in diverse scenarios with different target scenes and motion patterns. Experiments on the synthetic and real-world datasets demonstrate the superiority of our method over state-of-the-art approaches.
CrossZoom: Simultaneously Motion Deblurring and Event Super-Resolving
Sep 29, 2023


Even though the collaboration between traditional and neuromorphic event cameras brings prosperity to frame-event based vision applications, the performance is still confined by the resolution gap crossing two modalities in both spatial and temporal domains. This paper is devoted to bridging the gap by increasing the temporal resolution for images, i.e., motion deblurring, and the spatial resolution for events, i.e., event super-resolving, respectively. To this end, we introduce CrossZoom, a novel unified neural Network (CZ-Net) to jointly recover sharp latent sequences within the exposure period of a blurry input and the corresponding High-Resolution (HR) events. Specifically, we present a multi-scale blur-event fusion architecture that leverages the scale-variant properties and effectively fuses cross-modality information to achieve cross-enhancement. Attention-based adaptive enhancement and cross-interaction prediction modules are devised to alleviate the distortions inherent in Low-Resolution (LR) events and enhance the final results through the prior blur-event complementary information. Furthermore, we propose a new dataset containing HR sharp-blurry images and the corresponding HR-LR event streams to facilitate future research. Extensive qualitative and quantitative experiments on synthetic and real-world datasets demonstrate the effectiveness and robustness of the proposed method. Codes and datasets are released at https://bestrivenzc.github.io/CZ-Net/.
Learning Parallax for Stereo Event-based Motion Deblurring
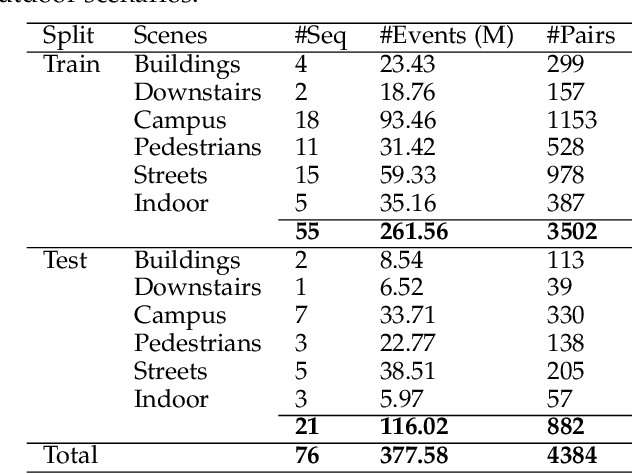
Sep 18, 2023Due to the extremely low latency, events have been recently exploited to supplement lost information for motion deblurring. Existing approaches largely rely on the perfect pixel-wise alignment between intensity images and events, which is not always fulfilled in the real world. To tackle this problem, we propose a novel coarse-to-fine framework, named NETwork of Event-based motion Deblurring with STereo event and intensity cameras (St-EDNet), to recover high-quality images directly from the misaligned inputs, consisting of a single blurry image and the concurrent event streams. Specifically, the coarse spatial alignment of the blurry image and the event streams is first implemented with a cross-modal stereo matching module without the need for ground-truth depths. Then, a dual-feature embedding architecture is proposed to gradually build the fine bidirectional association of the coarsely aligned data and reconstruct the sequence of the latent sharp images. Furthermore, we build a new dataset with STereo Event and Intensity Cameras (StEIC), containing real-world events, intensity images, and dense disparity maps. Experiments on real-world datasets demonstrate the superiority of the proposed network over state-of-the-art methods.
Video Frame Interpolation with Stereo Event and Intensity Camera
Jul 17, 2023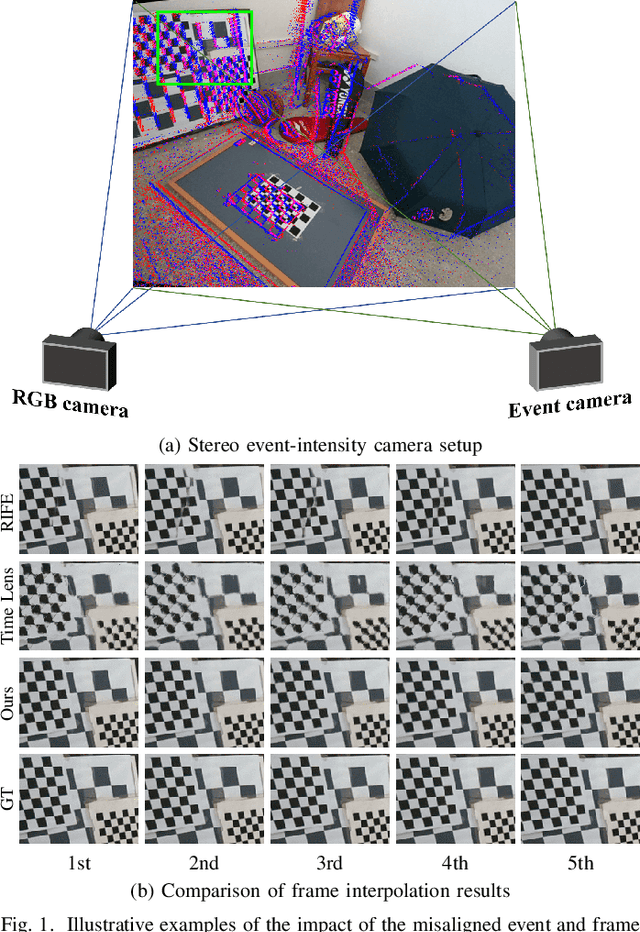



The stereo event-intensity camera setup is widely applied to leverage the advantages of both event cameras with low latency and intensity cameras that capture accurate brightness and texture information. However, such a setup commonly encounters cross-modality parallax that is difficult to be eliminated solely with stereo rectification especially for real-world scenes with complex motions and varying depths, posing artifacts and distortion for existing Event-based Video Frame Interpolation (E-VFI) approaches. To tackle this problem, we propose a novel Stereo Event-based VFI (SE-VFI) network (SEVFI-Net) to generate high-quality intermediate frames and corresponding disparities from misaligned inputs consisting of two consecutive keyframes and event streams emitted between them. Specifically, we propose a Feature Aggregation Module (FAM) to alleviate the parallax and achieve spatial alignment in the feature domain. We then exploit the fused features accomplishing accurate optical flow and disparity estimation, and achieving better interpolated results through flow-based and synthesis-based ways. We also build a stereo visual acquisition system composed of an event camera and an RGB-D camera to collect a new Stereo Event-Intensity Dataset (SEID) containing diverse scenes with complex motions and varying depths. Experiments on public real-world stereo datasets, i.e., DSEC and MVSEC, and our SEID dataset demonstrate that our proposed SEVFI-Net outperforms state-of-the-art methods by a large margin.
Self-Supervised Scene Dynamic Recovery from Rolling Shutter Images and Events
Apr 19, 2023



Scene Dynamic Recovery (SDR) by inverting distorted Rolling Shutter (RS) images to an undistorted high frame-rate Global Shutter (GS) video is a severely ill-posed problem due to the missing temporal dynamic information in both RS intra-frame scanlines and inter-frame exposures, particularly when prior knowledge about camera/object motions is unavailable. Commonly used artificial assumptions on scenes/motions and data-specific characteristics are prone to producing sub-optimal solutions in real-world scenarios. To address this challenge, we propose an event-based SDR network within a self-supervised learning paradigm, i.e., SelfUnroll. We leverage the extremely high temporal resolution of event cameras to provide accurate inter/intra-frame dynamic information. Specifically, an Event-based Inter/intra-frame Compensator (E-IC) is proposed to predict the per-pixel dynamic between arbitrary time intervals, including the temporal transition and spatial translation. Exploring connections in terms of RS-RS, RS-GS, and GS-RS, we explicitly formulate mutual constraints with the proposed E-IC, resulting in supervisions without ground-truth GS images. Extensive evaluations over synthetic and real datasets demonstrate that the proposed method achieves state-of-the-art and shows remarkable performance for event-based RS2GS inversion in real-world scenarios. The dataset and code are available at https://w3un.github.io/selfunroll/.