 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Uniform Exposure Imaging via Neuromorphic Shutter Control
Apr 22, 2024



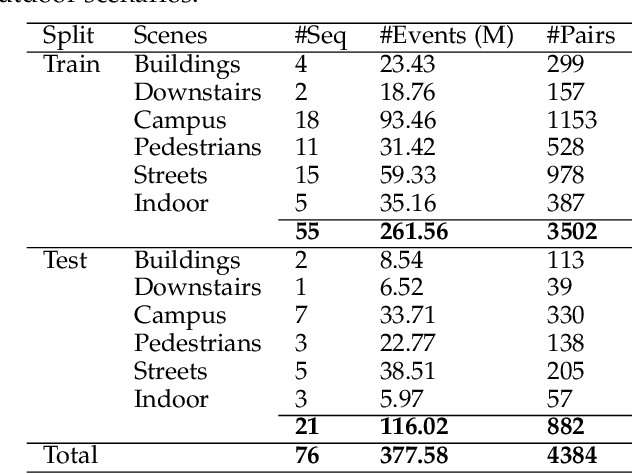
By leveraging the blur-noise trade-off, imaging with non-uniform exposures largely extends the image acquisition flexibility in harsh environments. However, the limitation of conventional cameras in perceiving intra-frame dynamic information prevents existing methods from being implemented in the real-world frame acquisition for real-time adaptive camera shutter control. To address this challenge, we propose a novel Neuromorphic Shutter Control (NSC) system to avoid motion blurs and alleviate instant noises, where the extremely low latency of events is leveraged to monitor the real-time motion and facilitate the scene-adaptive exposure. Furthermore, to stabilize the inconsistent Signal-to-Noise Ratio (SNR) caused by the non-uniform exposure times, we propose an event-based image denoising network within a self-supervised learning paradigm, i.e., SEID, exploring the statistics of image noises and inter-frame motion information of events to obtain artificial supervision signals for high-quality imaging in real-world scenes. To illustrate the effectiveness of the proposed NSC, we implement it in hardware by building a hybrid-camera imaging prototype system, with which we collect a real-world dataset containing well-synchronized frames and events in diverse scenarios with different target scenes and motion patterns. Experiments on the synthetic and real-world datasets demonstrate the superiority of our method over state-of-the-art approaches.
CrossZoom: Simultaneously Motion Deblurring and Event Super-Resolving
Sep 29, 2023


Even though the collaboration between traditional and neuromorphic event cameras brings prosperity to frame-event based vision applications, the performance is still confined by the resolution gap crossing two modalities in both spatial and temporal domains. This paper is devoted to bridging the gap by increasing the temporal resolution for images, i.e., motion deblurring, and the spatial resolution for events, i.e., event super-resolving, respectively. To this end, we introduce CrossZoom, a novel unified neural Network (CZ-Net) to jointly recover sharp latent sequences within the exposure period of a blurry input and the corresponding High-Resolution (HR) events. Specifically, we present a multi-scale blur-event fusion architecture that leverages the scale-variant properties and effectively fuses cross-modality information to achieve cross-enhancement. Attention-based adaptive enhancement and cross-interaction prediction modules are devised to alleviate the distortions inherent in Low-Resolution (LR) events and enhance the final results through the prior blur-event complementary information. Furthermore, we propose a new dataset containing HR sharp-blurry images and the corresponding HR-LR event streams to facilitate future research. Extensive qualitative and quantitative experiments on synthetic and real-world datasets demonstrate the effectiveness and robustness of the proposed method. Codes and datasets are released at https://bestrivenzc.github.io/CZ-Net/.
Learning Parallax for Stereo Event-based Motion Deblurring
Sep 18, 2023Due to the extremely low latency, events have been recently exploited to supplement lost information for motion deblurring. Existing approaches largely rely on the perfect pixel-wise alignment between intensity images and events, which is not always fulfilled in the real world. To tackle this problem, we propose a novel coarse-to-fine framework, named NETwork of Event-based motion Deblurring with STereo event and intensity cameras (St-EDNet), to recover high-quality images directly from the misaligned inputs, consisting of a single blurry image and the concurrent event streams. Specifically, the coarse spatial alignment of the blurry image and the event streams is first implemented with a cross-modal stereo matching module without the need for ground-truth depths. Then, a dual-feature embedding architecture is proposed to gradually build the fine bidirectional association of the coarsely aligned data and reconstruct the sequence of the latent sharp images. Furthermore, we build a new dataset with STereo Event and Intensity Cameras (StEIC), containing real-world events, intensity images, and dense disparity maps. Experiments on real-world datasets demonstrate the superiority of the proposed network over state-of-the-art methods.
No-Reference Color Image Quality Assessment: From Entropy to Perceptual Quality
Dec 27, 2018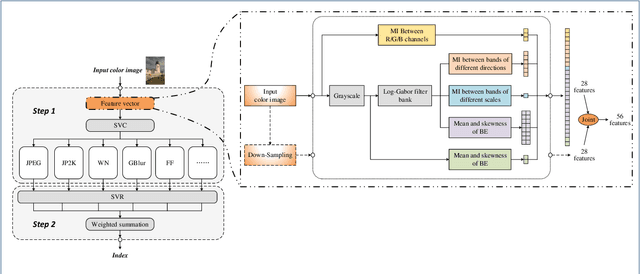

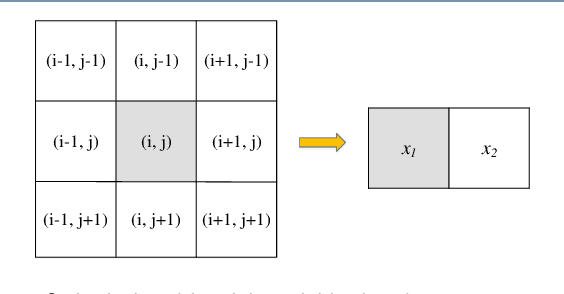
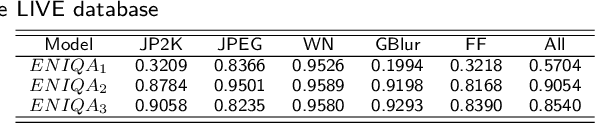
This paper presents a high-performance general-purpose no-reference (NR) image quality assessment (IQA) method based on image entropy. The image features are extracted from two domains. In the spatial domain, the mutual information between the color channels and the two-dimensional entropy are calculated. In the frequency domain, the two-dimensional entropy and the mutual information of the filtered sub-band images are computed as the feature set of the input color image. Then, with all the extracted features, the support vector classifier (SVC) for distortion classification and support vector regression (SVR) are utilized for the quality prediction, to obtain the final quality assessment score. The proposed method, which we call entropy-based no-reference image quality assessment (ENIQA), can assess the quality of different categories of distorted images, and has a low complexity. The proposed ENIQA method was assessed on the LIVE and TID2013 databases and showed a superior performance. The experimental results confirmed that the proposed ENIQA method has a high consistency of objective and subjective assessment on color images, which indicates the good overall performance and generalization ability of ENIQA. The source code is available on github https://github.com/jacob6/ENIQA.
A Deep Graph Embedding Network Model for Face Recognition
Sep 25, 2014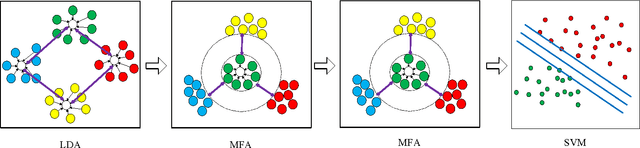


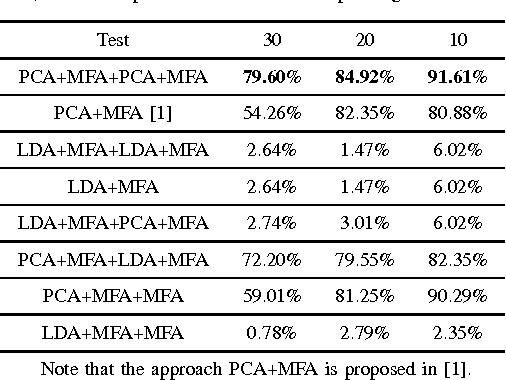
In this paper, we propose a new deep learning network "GENet", it combines the multi-layer network architec- ture and graph embedding framework. Firstly, we use simplest unsupervised learning PCA/LDA as first layer to generate the low- level feature. Secondly, many cascaded dimensionality reduction layers based on graph embedding framework are applied to GENet. Finally, a linear SVM classifier is used to classify dimension-reduced features. The experiments indicate that higher classification accuracy can be obtained by this algorithm on the CMU-PIE, ORL, Extended Yale B dataset.
Image Classification with A Deep Network Model based on Compressive Sensing
Sep 25, 2014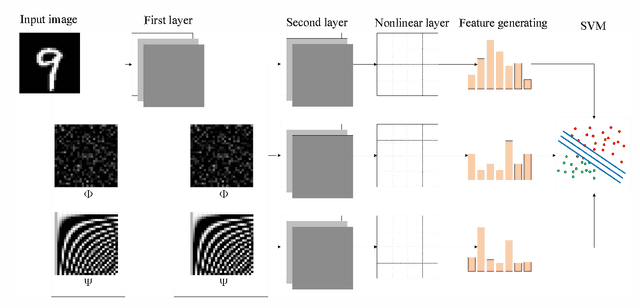
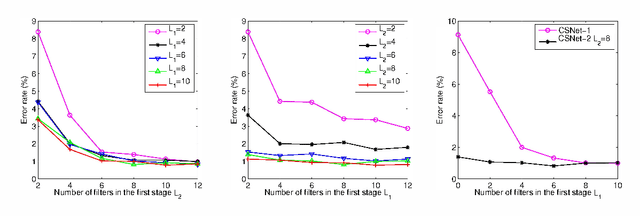

To simplify the parameter of the deep learning network, a cascaded compressive sensing model "CSNet" is implemented for image classification. Firstly, we use cascaded compressive sensing network to learn feature from the data. Secondly, CSNet generates the feature by binary hashing and block-wise histograms. Finally, a linear SVM classifier is used to classify these features. The experiments on the MNIST dataset indicate that higher classification accuracy can be obtained by this algorithm.