 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVDI++: Event-based Video Deblurring and Interpolation via Self-Supervised Learning
Sep 10, 2025



Frame-based cameras with extended exposure times often produce perceptible visual blurring and information loss between frames, significantly degrading video quality. To address this challenge, we introduce EVDI++, a unified self-supervised framework for Event-based Video Deblurring and Interpolation that leverages the high temporal resolution of event cameras to mitigate motion blur and enable intermediate frame prediction. Specifically, the Learnable Double Integral (LDI) network is designed to estimate the mapping relation between reference frames and sharp latent images. Then, we refine the coarse results and optimize overall training efficiency by introducing a learning-based division reconstruction module, enabling images to be converted with varying exposure intervals. We devise an adaptive parameter-free fusion strategy to obtain the final results, utilizing the confidence embedded in the LDI outputs of concurrent events. A self-supervised learning framework is proposed to enable network training with real-world blurry videos and events by exploring the mutual constraints among blurry frames, latent images, and event streams. We further construct a dataset with real-world blurry images and events using a DAVIS346c camera, demonstrating the generalizability of the proposed EVDI++ in real-world scenarios. Extensive experiments on both synthetic and real-world datasets show that our method achieves state-of-the-art performance in video deblurring and interpolation tasks.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Super-Resolving Blurry Images with Events
May 11, 2024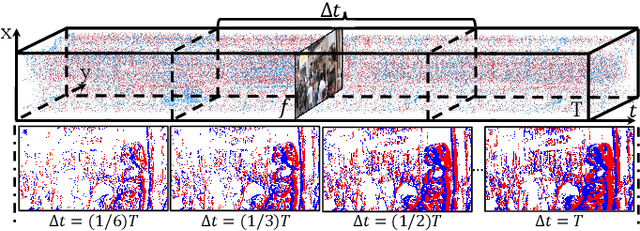
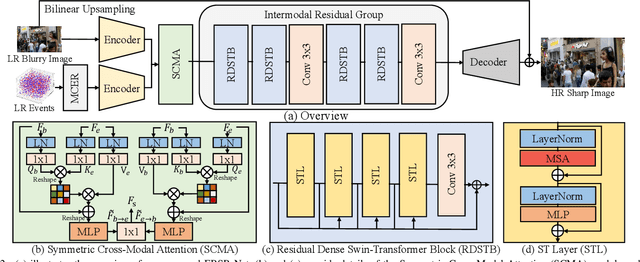


Super-resolution from motion-blurred images poses a significant challenge due to the combined effects of motion blur and low spatial resolution. To address this challenge, this paper introduces an Event-based Blurry Super Resolution Network (EBSR-Net), which leverages the high temporal resolution of events to mitigate motion blur and improve high-resolution image prediction. Specifically, we propose a multi-scale center-surround event representation to fully capture motion and texture information inherent in events. Additionally, we design a symmetric cross-modal attention module to fully exploit the complementarity between blurry images and events. Furthermore, we introduce an intermodal residual group composed of several residual dense Swin Transformer blocks, each incorporating multiple Swin Transformer layers and a residual connection, to extract global context and facilitate inter-block feature aggregation. Extensive experiments show that our method compares favorably against state-of-the-art approaches and achieves remarkable performance.
Learning Monocular Depth from Focus with Event Focal Stack
May 11, 2024Depth from Focus estimates depth by determining the moment of maximum focus from multiple shots at different focal distances, i.e. the Focal Stack. However, the limited sampling rate of conventional optical cameras makes it difficult to obtain sufficient focus cues during the focal sweep. Inspired by biological vision, the event camera records intensity changes over time in extremely low latency, which provides more temporal information for focus time acquisition. In this study, we propose the EDFF Network to estimate sparse depth from the Event Focal Stack. Specifically, we utilize the event voxel grid to encode intensity change information and project event time surface into the depth domain to preserve per-pixel focal distance information. A Focal-Distance-guided Cross-Modal Attention Module is presented to fuse the information mentioned above. Additionally, we propose a Multi-level Depth Fusion Block designed to integrate results from each level of a UNet-like architecture and produce the final output. Extensive experiments validate that our method outperforms existing state-of-the-art approaches.