 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-RL Induces Exploration in Language Agents
Dec 18, 2025Reinforcement learning (RL) has enabled the training of large language model (LLM) agents to interact with the environment and to solve multi-turn long-horizon tasks. However, the RL-trained agents often struggle in tasks that require active exploration and fail to efficiently adapt from trial-and-error experiences. In this paper, we present LaMer, a general Meta-RL framework that enables LLM agents to actively explore and learn from the environment feedback at test time. LaMer consists of two key components: (i) a cross-episode training framework to encourage exploration and long-term rewards optimization; and (ii) in-context policy adaptation via reflection, allowing the agent to adapt their policy from task feedback signal without gradient update. Experiments across diverse environments show that LaMer significantly improves performance over RL baselines, with 11%, 14%, and 19% performance gains on Sokoban, MineSweeper and Webshop, respectively. Moreover, LaMer also demonstrates better generalization to more challenging or previously unseen tasks compared to the RL-trained agents. Overall, our results demonstrate that Meta-RL provides a principled approach to induce exploration in language agents, enabling more robust adaptation to novel environments through learned exploration strategies.
Large (Vision) Language Models are Unsupervised In-Context Learners
Apr 03, 2025Recent advances in large language and vision-language models have enabled zero-shot inference, allowing models to solve new tasks without task-specific training. Various adaptation techniques such as prompt engineering, In-Context Learning (ICL), and supervised fine-tuning can further enhance the model's performance on a downstream task, but they require substantial manual effort to construct effective prompts or labeled examples. In this work, we introduce a joint inference framework for fully unsupervised adaptation, eliminating the need for manual prompt engineering and labeled examples. Unlike zero-shot inference, which makes independent predictions, the joint inference makes predictions simultaneously for all inputs in a given task. Since direct joint inference involves computationally expensive optimization, we develop efficient approximation techniques, leading to two unsupervised adaptation methods: unsupervised fine-tuning and unsupervised ICL. We demonstrate the effectiveness of our methods across diverse tasks and models, including language-only Llama-3.1 on natural language processing tasks, reasoning-oriented Qwen2.5-Math on grade school math problems, vision-language OpenFlamingo on vision tasks, and the API-only access GPT-4o model on massive multi-discipline tasks. Our experiments demonstrate substantial improvements over the standard zero-shot approach, including 39% absolute improvement on the challenging GSM8K math reasoning dataset. Remarkably, despite being fully unsupervised, our framework often performs on par with supervised approaches that rely on ground truth labels.
Let Go of Your Labels with Unsupervised Transfer
Jun 11, 2024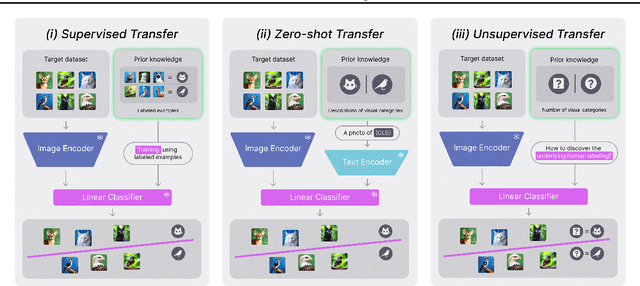
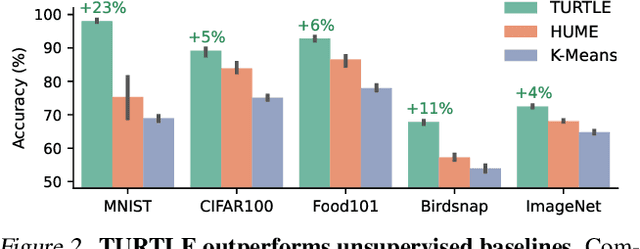

Foundation vision-language models have enabled remarkable zero-shot transferability of the pre-trained representations to a wide range of downstream tasks. However, to solve a new task, zero-shot transfer still necessitates human guidance to define visual categories that appear in the data. Here, we show that fully unsupervised transfer emerges when searching for the labeling of a dataset that induces maximal margin classifiers in representation spaces of different foundation models. We present TURTLE, a fully unsupervised method that effectively employs this guiding principle to uncover the underlying labeling of a downstream dataset without any supervision and task-specific representation learning. We evaluate TURTLE on a diverse benchmark suite of 26 datasets and show that it achieves new state-of-the-art unsupervised performance. Furthermore, TURTLE, although being fully unsupervised, outperforms zero-shot transfer baselines on a wide range of datasets. In particular, TURTLE matches the average performance of CLIP zero-shot on 26 datasets by employing the same representation space, spanning a wide range of architectures and model sizes. By guiding the search for the underlying labeling using the representation spaces of two foundation models, TURTLE surpasses zero-shot transfer and unsupervised prompt tuning baselines, demonstrating the surprising power and effectiveness of unsupervised transfer.
Learning Cluster Structured Sparsity by Reweighting
Oct 11, 2019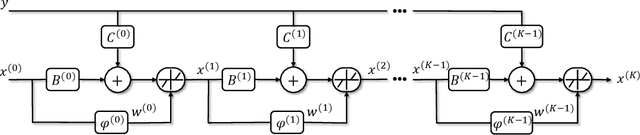
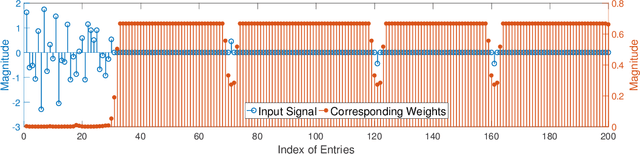
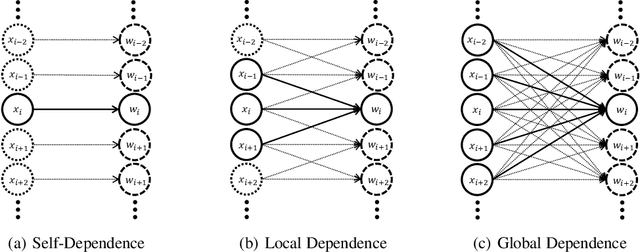
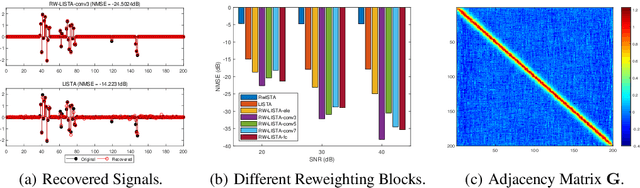
Recently, the paradigm of unfolding iterative algorithms into finite-length feed-forward neural networks has achieved a great success in the area of sparse recovery. Benefit from available training data, the learned networks have achieved state-of-the-art performance in respect of both speed and accuracy. However, the structure behind sparsity, imposing constraint on the support of sparse signals, is often an essential prior knowledge but seldom considered in the existing networks. In this paper, we aim at bridging this gap. Specifically, exploiting the iterative reweighted $\ell_1$ minimization (IRL1) algorithm, we propose to learn the cluster structured sparsity (CSS) by rewegihting adaptively. In particular, we first unfold the Reweighted Iterative Shrinkage Algorithm (RwISTA) into an end-to-end trainable deep architecture termed as RW-LISTA. Then instead of the element-wise reweighting, the global and local reweighting manner are proposed for the cluster structured sparse learning. Numerical experiments further show the superiority of our algorithm against both classical algorithms and learning-based networks on different tasks.