 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Large-Scale Scene Reconstruction via Mixed Gaussian Splatting
May 29, 2025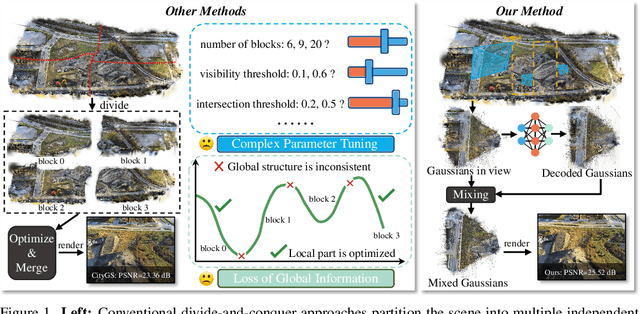
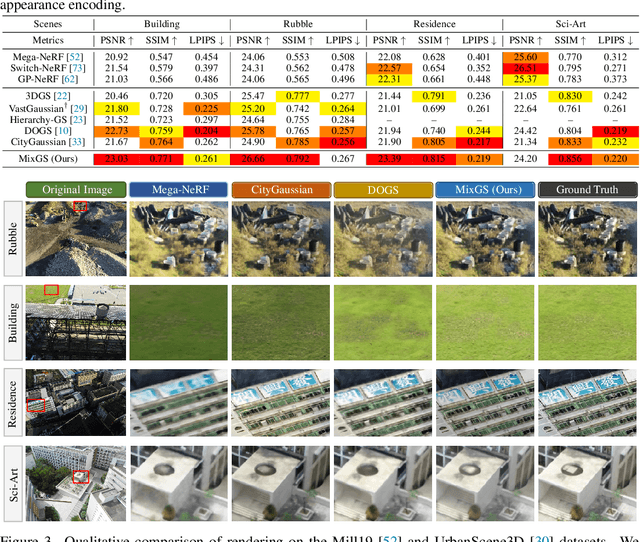
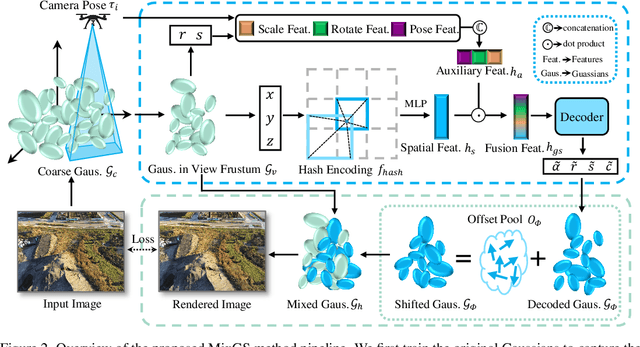
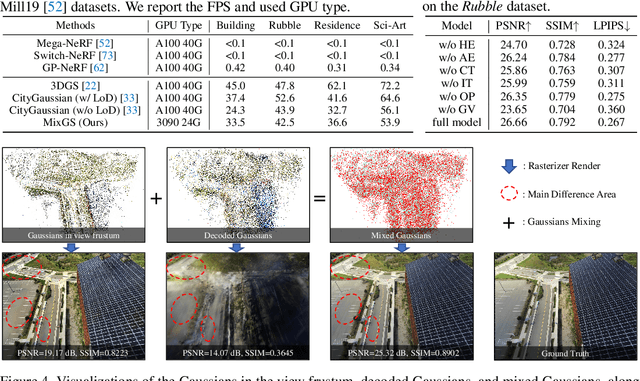
Recent advances in 3D Gaussian Splatting have shown remarkable potential for novel view synthesis. However, most existing large-scale scene reconstruction methods rely on the divide-and-conquer paradigm, which often leads to the loss of global scene information and requires complex parameter tuning due to scene partitioning and local optimization. To address these limitations, we propose MixGS, a novel holistic optimization framework for large-scale 3D scene reconstruction. MixGS models the entire scene holistically by integrating camera pose and Gaussian attributes into a view-aware representation, which is decoded into fine-detailed Gaussians. Furthermore, a novel mixing operation combines decoded and original Gaussians to jointly preserve global coherence and local fidelity. Extensive experiments on large-scale scenes demonstrate that MixGS achieves state-of-the-art rendering quality and competitive speed, while significantly reducing computational requirements, enabling large-scale scene reconstruction training on a single 24GB VRAM GPU. The code will be released at https://github.com/azhuantou/MixGS.
Unsupervised Network for Single Image Raindrop Removal
Dec 04, 2024



Image quality degradation caused by raindrops is one of the most important but challenging problems that reduce the performance of vision systems. Most existing raindrop removal algorithms are based on a supervised learning method using pairwise images, which are hard to obtain in real-world applications. This study proposes a deep neural network for raindrop removal based on unsupervised learning, which only requires two unpaired image sets with and without raindrops. Our proposed model performs layer separation based on cycle network architecture, which aims to separate a rainy image into a raindrop layer, a transparency mask, and a clean background layer. The clean background layer is the target raindrop removal result, while the transparency mask indicates the spatial locations of the raindrops. In addition, the proposed model applies a feedback mechanism to benefit layer separation by refining low-level representation with high-level information. i.e., the output of the previous iteration is used as input for the next iteration, together with the input image with raindrops. As a result, raindrops could be gradually removed through this feedback manner. Extensive experiments on raindrop benchmark datasets demonstrate the effectiveness of the proposed method on quantitative metrics and visual quality.
Facial Feature Embedded CycleGAN for VIS-NIR Translation
Apr 25, 2019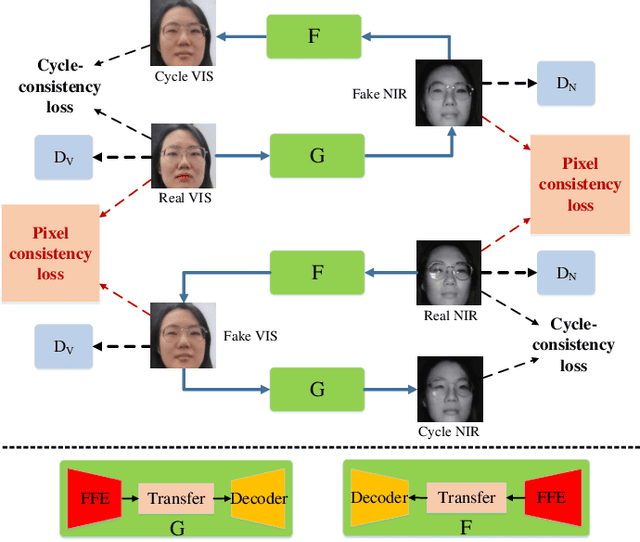
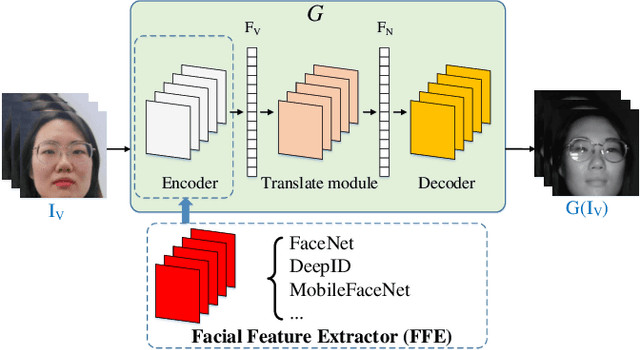
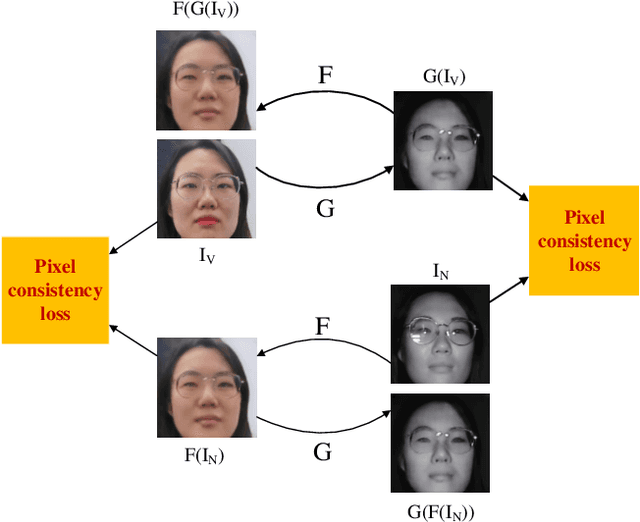

VIS-NIR face recognition remains a challenging task due to the distinction between spectral components of two modalities and insufficient paired training data. Inspired by the CycleGAN, this paper presents a method aiming to translate VIS face images into fake NIR images whose distributions are intended to approximate those of true NIR images, which is achieved by proposing a new facial feature embedded CycleGAN. Firstly, to learn the particular feature of NIR domain while preserving common facial representation between VIS and NIR domains, we employ a general facial feature extractor (FFE) to replace the encoder in the original generator of CycleGAN. For implementing the facial feature extractor, herein the MobileFaceNet is pretrained on a VIS face database, and is able to extract effective features. Secondly, the domain-invariant feature learning is enhanced by considering a new pixel consistency loss. Lastly, we establish a new WHU VIS-NIR database which varies in face rotation and expressions to enrich the training data. Experimental results on the Oulu-CASIA NIR-VIS database and the WHU VIS-NIR database show that the proposed FFE-based CycleGAN (FFE-CycleGAN) outperforms state-of-the-art VIS-NIR face recognition methods and achieves 96.5\% accuracy.