 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr.Occ: Depth- and Region-Guided 3D Occupancy from Surround-View Cameras for Autonomous Driving
Mar 05, 20263D semantic occupancy prediction is crucial for autonomous driving perception, offering comprehensive geometric scene understanding and semantic recognition. However, existing methods struggle with geometric misalignment in view transformation due to the lack of pixel-level accurate depth estimation, and severe spatial class imbalance where semantic categories exhibit strong spatial anisotropy. To address these challenges, we propose Dr. Occ, a depth- and region-guided occupancy prediction framework. Specifically, we introduce a depth-guided 2D-to-3D View Transformer (D$^2$-VFormer) that effectively leverages high-quality dense depth cues from MoGe-2 to construct reliable geometric priors, thereby enabling precise geometric alignment of voxel features. Moreover, inspired by the Mixture-of-Experts (MoE) framework, we propose a region-guided Expert Transformer (R/R$^2$-EFormer) that adaptively allocates region-specific experts to focus on different spatial regions, effectively addressing spatial semantic variations. Thus, the two components make complementary contributions: depth guidance ensures geometric alignment, while region experts enhance semantic learning. Experiments on the Occ3D--nuScenes benchmark demonstrate that Dr. Occ improves the strong baseline BEVDet4D by 7.43% mIoU and 3.09% IoU under the full vision-only setting.
DF-Calib: Targetless LiDAR-Camera Calibration via Depth Flow
Apr 02, 2025


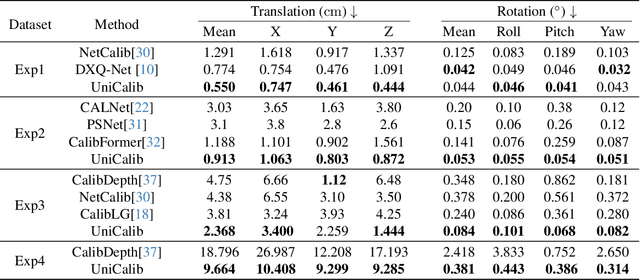
Precise LiDAR-camera calibration is crucial for integrating these two sensors into robotic systems to achieve robust perception. In applications like autonomous driving, online targetless calibration enables a prompt sensor misalignment correction from mechanical vibrations without extra targets. However, existing methods exhibit limitations in effectively extracting consistent features from LiDAR and camera data and fail to prioritize salient regions, compromising cross-modal alignment robustness. To address these issues, we propose DF-Calib, a LiDAR-camera calibration method that reformulates calibration as an intra-modality depth flow estimation problem. DF-Calib estimates a dense depth map from the camera image and completes the sparse LiDAR projected depth map, using a shared feature encoder to extract consistent depth-to-depth features, effectively bridging the 2D-3D cross-modal gap. Additionally, we introduce a reliability map to prioritize valid pixels and propose a perceptually weighted sparse flow loss to enhance depth flow estimation. Experimental results across multiple datasets validate its accuracy and generalization,with DF-Calib achieving a mean translation error of 0.635cm and rotation error of 0.045 degrees on the KITTI dataset.
LiDAR-enhanced 3D Gaussian Splatting Mapping
Mar 07, 2025



This paper introduces LiGSM, a novel LiDAR-enhanced 3D Gaussian Splatting (3DGS) mapping framework that improves the accuracy and robustness of 3D scene mapping by integrating LiDAR data. LiGSM constructs joint loss from images and LiDAR point clouds to estimate the poses and optimize their extrinsic parameters, enabling dynamic adaptation to variations in sensor alignment. Furthermore, it leverages LiDAR point clouds to initialize 3DGS, providing a denser and more reliable starting points compared to sparse SfM points. In scene rendering, the framework augments standard image-based supervision with depth maps generated from LiDAR projections, ensuring an accurate scene representation in both geometry and photometry. Experiments on public and self-collected datasets demonstrate that LiGSM outperforms comparative methods in pose tracking and scene rendering.
Frequency-Adaptive Low-Latency Object Detection Using Events and Frames
Dec 05, 2024



Fusing Events and RGB images for object detection leverages the robustness of Event cameras in adverse environments and the rich semantic information provided by RGB cameras. However, two critical mismatches: low-latency Events \textit{vs.}~high-latency RGB frames; temporally sparse labels in training \textit{vs.}~continuous flow in inference, significantly hinder the high-frequency fusion-based object detection. To address these challenges, we propose the \textbf{F}requency-\textbf{A}daptive Low-Latency \textbf{O}bject \textbf{D}etector (FAOD). FAOD aligns low-frequency RGB frames with high-frequency Events through an Align Module, which reinforces cross-modal style and spatial proximity to address the Event-RGB Mismatch. We further propose a training strategy, Time Shift, which enforces the module to align the prediction from temporally shifted Event-RGB pairs and their original representation, that is, consistent with Event-aligned annotations. This strategy enables the network to use high-frequency Event data as the primary reference while treating low-frequency RGB images as supplementary information, retaining the low-latency nature of the Event stream toward high-frequency detection. Furthermore, we observe that these corrected Event-RGB pairs demonstrate better generalization from low training frequency to higher inference frequencies compared to using Event data alone. Extensive experiments on the PKU-DAVIS-SOD and DSEC-Detection datasets demonstrate that our FAOD achieves SOTA performance. Specifically, in the PKU-DAVIS-SOD Dataset, FAOD achieves 9.8 points improvement in terms of the mAP in fully paired Event-RGB data with only a quarter of the parameters compared to SODFormer, and even maintains robust performance (only a 3 points drop in mAP) under 80$\times$ Event-RGB frequency mismatch.
MCVO: A Generic Visual Odometry for Arbitrarily Arranged Multi-Cameras
Dec 04, 2024



Making multi-camera visual SLAM systems easier to set up and more robust to the environment is always one of the focuses of vision robots. Existing monocular and binocular vision SLAM systems have narrow FoV and are fragile in textureless environments with degenerated accuracy and limited robustness. Thus multi-camera SLAM systems are gaining attention because they can provide redundancy for texture degeneration with wide FoV. However, current multi-camera SLAM systems face massive data processing pressure and elaborately designed camera configurations, leading to estimation failures for arbitrarily arranged multi-camera systems. To address these problems, we propose a generic visual odometry for arbitrarily arranged multi-cameras, which can achieve metric-scale state estimation with high flexibility in the cameras' arrangement. Specifically, we first design a learning-based feature extraction and tracking framework to shift the pressure of CPU processing of multiple video streams. Then we use the rigid constraints between cameras to estimate the metric scale poses for robust SLAM system initialization. Finally, we fuse the features of the multi-cameras in the SLAM back-end to achieve robust pose estimation and online scale optimization. Additionally, multi-camera features help improve the loop detection for pose graph optimization. Experiments on KITTI-360 and MultiCamData datasets validate the robustness of our method over arbitrarily placed cameras. Compared with other stereo and multi-camera visual SLAM systems, our method obtains higher pose estimation accuracy with better generalization ability. Our codes and online demos are available at \url{https://github.com/JunhaoWang615/MCVO}
QuadricsReg: Large-Scale Point Cloud Registration using Quadric Primitives
Dec 04, 2024



In the realm of large-scale point cloud registration, designing a compact symbolic representation is crucial for efficiently processing vast amounts of data, ensuring registration robustness against significant viewpoint variations and occlusions. This paper introduces a novel point cloud registration method, i.e., QuadricsReg, which leverages concise quadrics primitives to represent scenes and utilizes their geometric characteristics to establish correspondences for 6-DoF transformation estimation. As a symbolic feature, the quadric representation fully captures the primary geometric characteristics of scenes, which can efficiently handle the complexity of large-scale point clouds. The intrinsic characteristics of quadrics, such as types and scales, are employed to initialize correspondences. Then we build a multi-level compatibility graph set to find the correspondences using the maximum clique on the geometric consistency between quadrics. Finally, we estimate the 6-DoF transformation using the quadric correspondences, which is further optimized based on the quadric degeneracy-aware distance in a factor graph, ensuring high registration accuracy and robustness against degenerate structures. We test on 5 public datasets and the self-collected heterogeneous dataset across different LiDAR sensors and robot platforms. The exceptional registration success rates and minimal registration errors demonstrate the effectiveness of QuadricsReg in large-scale point cloud registration scenarios. Furthermore, the real-world registration testing on our self-collected heterogeneous dataset shows the robustness and generalization ability of QuadricsReg on different LiDAR sensors and robot platforms. The codes and demos will be released at \url{https://levenberg.github.io/QuadricsReg}.
Unsupervised Multi-view UAV Image Geo-localization via Iterative Rendering
Nov 22, 2024



Unmanned Aerial Vehicle (UAV) Cross-View Geo-Localization (CVGL) presents significant challenges due to the view discrepancy between oblique UAV images and overhead satellite images. Existing methods heavily rely on the supervision of labeled datasets to extract viewpoint-invariant features for cross-view retrieval. However, these methods have expensive training costs and tend to overfit the region-specific cues, showing limited generalizability to new regions. To overcome this issue, we propose an unsupervised solution that lifts the scene representation to 3d space from UAV observations for satellite image generation, providing robust representation against view distortion. By generating orthogonal images that closely resemble satellite views, our method reduces view discrepancies in feature representation and mitigates shortcuts in region-specific image pairing. To further align the rendered image's perspective with the real one, we design an iterative camera pose updating mechanism that progressively modulates the rendered query image with potential satellite targets, eliminating spatial offsets relative to the reference images. Additionally, this iterative refinement strategy enhances cross-view feature invariance through view-consistent fusion across iterations. As such, our unsupervised paradigm naturally avoids the problem of region-specific overfitting, enabling generic CVGL for UAV images without feature fine-tuning or data-driven training. Experiments on the University-1652 and SUES-200 datasets demonstrate that our approach significantly improves geo-localization accuracy while maintaining robustness across diverse regions. Notably, without model fine-tuning or paired training, our method achieves competitive performance with recent supervised methods.
Learning Cross-view Visual Geo-localization without Ground Truth
Mar 19, 2024

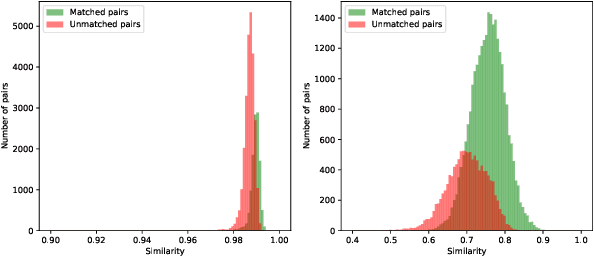
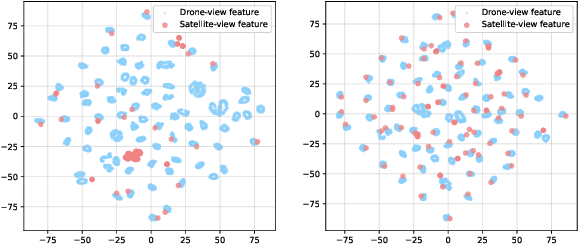
Cross-View Geo-Localization (CVGL) involves determining the geographical location of a query image by matching it with a corresponding GPS-tagged reference image. Current state-of-the-art methods predominantly rely on training models with labeled paired images, incurring substantial annotation costs and training burdens. In this study, we investigate the adaptation of frozen models for CVGL without requiring ground truth pair labels. We observe that training on unlabeled cross-view images presents significant challenges, including the need to establish relationships within unlabeled data and reconcile view discrepancies between uncertain queries and references. To address these challenges, we propose a self-supervised learning framework to train a learnable adapter for a frozen Foundation Model (FM). This adapter is designed to map feature distributions from diverse views into a uniform space using unlabeled data exclusively. To establish relationships within unlabeled data, we introduce an Expectation-Maximization-based Pseudo-labeling module, which iteratively estimates associations between cross-view features and optimizes the adapter. To maintain the robustness of the FM's representation, we incorporate an information consistency module with a reconstruction loss, ensuring that adapted features retain strong discriminative ability across views. Experimental results demonstrate that our proposed method achieves significant improvements over vanilla FMs and competitive accuracy compared to supervised methods, while necessitating fewer training parameters and relying solely on unlabeled data. Evaluation of our adaptation for task-specific models further highlights its broad applicability.
FE-DeTr: Keypoint Detection and Tracking in Low-quality Image Frames with Events
Mar 18, 2024


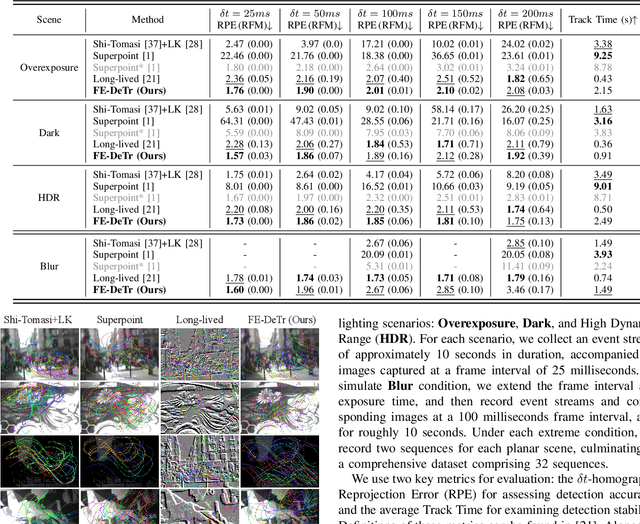
Keypoint detection and tracking in traditional image frames are often compromised by image quality issues such as motion blur and extreme lighting conditions. Event cameras offer potential solutions to these challenges by virtue of their high temporal resolution and high dynamic range. However, they have limited performance in practical applications due to their inherent noise in event data. This paper advocates fusing the complementary information from image frames and event streams to achieve more robust keypoint detection and tracking. Specifically, we propose a novel keypoint detection network that fuses the textural and structural information from image frames with the high-temporal-resolution motion information from event streams, namely FE-DeTr. The network leverages a temporal response consistency for supervision, ensuring stable and efficient keypoint detection. Moreover, we use a spatio-temporal nearest-neighbor search strategy for robust keypoint tracking. Extensive experiments are conducted on a new dataset featuring both image frames and event data captured under extreme conditions. The experimental results confirm the superior performance of our method over both existing frame-based and event-based methods.
Rethinking Scale Imbalance in Semi-supervised Object Detection for Aerial Images
Oct 23, 2023



This paper focuses on the scale imbalance problem of semi-supervised object detection(SSOD) in aerial images. Compared to natural images, objects in aerial images show smaller sizes and larger quantities per image, increasing the difficulty of manual annotation. Meanwhile, the advanced SSOD technique can train superior detectors by leveraging limited labeled data and massive unlabeled data, saving annotation costs. However, as an understudied task in aerial images, SSOD suffers from a drastic performance drop when facing a large proportion of small objects. By analyzing the predictions between small and large objects, we identify three imbalance issues caused by the scale bias, i.e., pseudo-label imbalance, label assignment imbalance, and negative learning imbalance. To tackle these issues, we propose a novel Scale-discriminative Semi-Supervised Object Detection (S^3OD) learning pipeline for aerial images. In our S^3OD, three key components, Size-aware Adaptive Thresholding (SAT), Size-rebalanced Label Assignment (SLA), and Teacher-guided Negative Learning (TNL), are proposed to warrant scale unbiased learning. Specifically, SAT adaptively selects appropriate thresholds to filter pseudo-labels for objects at different scales. SLA balances positive samples of objects at different scales through resampling and reweighting. TNL alleviates the imbalance in negative samples by leveraging information generated by a teacher model. Extensive experiments conducted on the DOTA-v1.5 benchmark demonstrate the superiority of our proposed methods over state-of-the-art competitors. Codes will be released soon.