 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-a-Supervisor: Mistaken Therapeutic Behaviors Trigger Targeted Supervisory Feedback
Aug 12, 2025



Although large language models (LLMs) hold significant promise in psychotherapy, their direct application in patient-facing scenarios raises ethical and safety concerns. Therefore, this work shifts towards developing an LLM as a supervisor to train real therapists. In addition to the privacy of clinical therapist training data, a fundamental contradiction complicates the training of therapeutic behaviors: clear feedback standards are necessary to ensure a controlled training system, yet there is no absolute "gold standard" for appropriate therapeutic behaviors in practice. In contrast, many common therapeutic mistakes are universal and identifiable, making them effective triggers for targeted feedback that can serve as clearer evidence. Motivated by this, we create a novel therapist-training paradigm: (1) guidelines for mistaken behaviors and targeted correction strategies are first established as standards; (2) a human-in-the-loop dialogue-feedback dataset is then constructed, where a mistake-prone agent intentionally makes standard mistakes during interviews naturally, and a supervisor agent locates and identifies mistakes and provides targeted feedback; (3) after fine-tuning on this dataset, the final supervisor model is provided for real therapist training. The detailed experimental results of automated, human and downstream assessments demonstrate that models fine-tuned on our dataset MATE, can provide high-quality feedback according to the clinical guideline, showing significant potential for the therapist training scenario.
LiDAR-enhanced 3D Gaussian Splatting Mapping
Mar 07, 2025



This paper introduces LiGSM, a novel LiDAR-enhanced 3D Gaussian Splatting (3DGS) mapping framework that improves the accuracy and robustness of 3D scene mapping by integrating LiDAR data. LiGSM constructs joint loss from images and LiDAR point clouds to estimate the poses and optimize their extrinsic parameters, enabling dynamic adaptation to variations in sensor alignment. Furthermore, it leverages LiDAR point clouds to initialize 3DGS, providing a denser and more reliable starting points compared to sparse SfM points. In scene rendering, the framework augments standard image-based supervision with depth maps generated from LiDAR projections, ensuring an accurate scene representation in both geometry and photometry. Experiments on public and self-collected datasets demonstrate that LiGSM outperforms comparative methods in pose tracking and scene rendering.
Efficient Bi-manipulation using RGBD Multi-model Fusion based on Attention Mechanism
Apr 27, 2024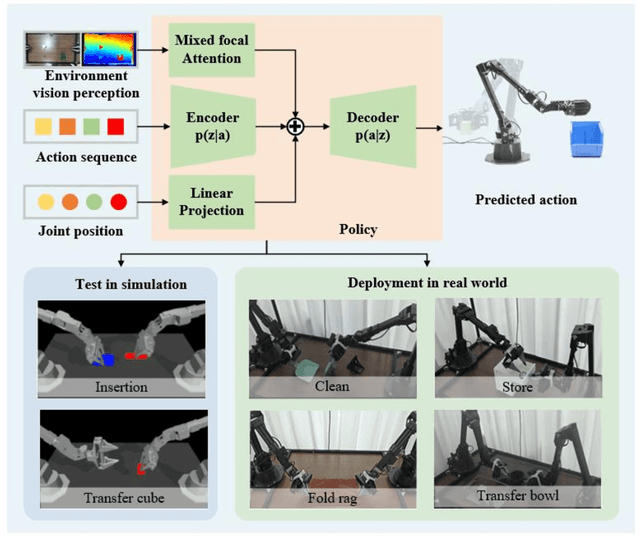
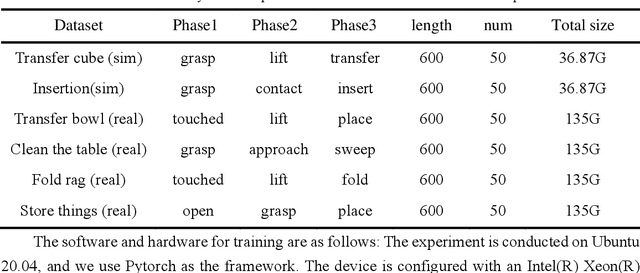
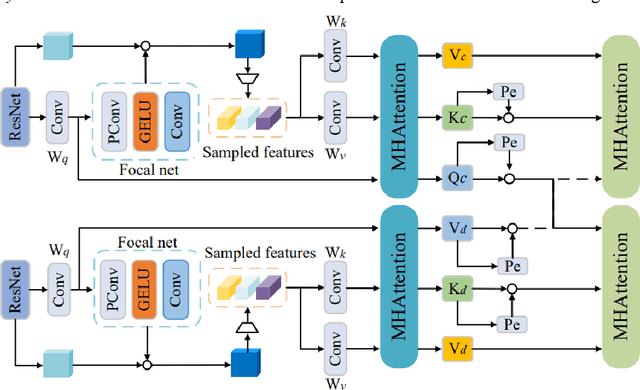
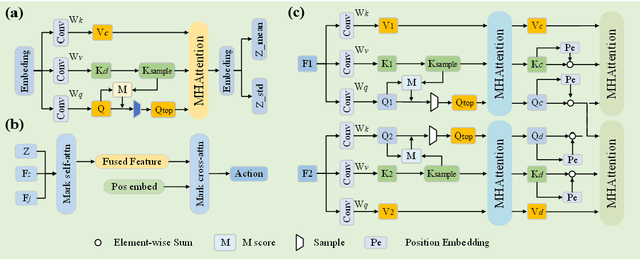
Dual-arm robots have great application prospects in intelligent manufacturing due to their human-like structure when deployed with advanced intelligence algorithm. However, the previous visuomotor policy suffers from perception deficiencies in environments where features of images are impaired by the various conditions, such as abnormal lighting, occlusion and shadow etc. The Focal CVAE framework is proposed for RGB-D multi-modal data fusion to address this challenge. In this study, a mixed focal attention module is designed for the fusion of RGB images containing color features and depth images containing 3D shape and structure information. This module highlights the prominent local features and focuses on the relevance of RGB and depth via cross-attention. A saliency attention module is proposed to improve its computational efficiency, which is applied in the encoder and the decoder of the framework. We illustrate the effectiveness of the proposed method via extensive simulation and experiments. It's shown that the performances of bi-manipulation are all significantly improved in the four real-world tasks with lower computational cost. Besides, the robustness is validated through experiments under different scenarios where there is a perception deficiency problem, demonstrating the feasibility of the method.
Fractal Gripper: Adaptive manipulator with mode switching
Feb 25, 2024

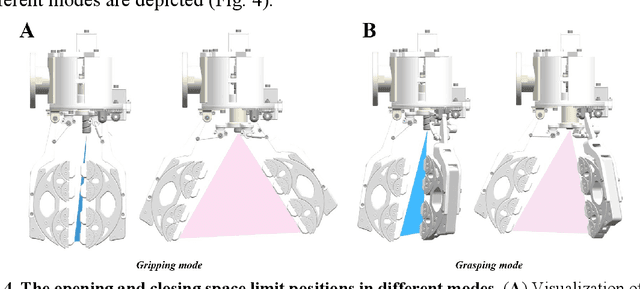
Although the multi-jointed underactuated manipulator is highly dexterous, its grasping capacity does not match that of the parallel jaw gripper. This work introduces a fractal gripper to enhance the grasping capacity of multi-joint underactuated manipulators, preserving their passive clamping features. We describe in detail the working principle and manufacturing process of the fractal gripper. This work, inspired by the 'Fractal Vise' structure, resulted in the invention of a fractal gripper with mode switching capabilities. The fractal gripper inherits the inherent adaptive properties of the fractal structure and realizes the self-resetting function by integrating spring into the original design, thereby enhancing the efficiency of object grasping tasks. The fractal gripper prevents object damage by distributing pressure evenly and applying it at multiple points through its fractal structure during closure. Objects of various shapes are effectively grasped by the fractal gripper, which ensures a safe and secure grasp. The superior performance was provided by the force distribution characteristics of the fractal gripper. By applying the flexible polymer PDMS, which possesses superior elasticity, to the fractal structure's wrapping surface, potential scratching during grasping is effectively prevented, thus protecting the object's geometric surface. Grab experiments with objects of diverse shapes and sizes confirm fractal gripper multi-scale adaptability and superior grasping stability.
Set-to-Sequence Ranking-based Concept-aware Learning Path Recommendation
Jun 07, 2023



With the development of the online education system, personalized education recommendation has played an essential role. In this paper, we focus on developing path recommendation systems that aim to generating and recommending an entire learning path to the given user in each session. Noticing that existing approaches fail to consider the correlations of concepts in the path, we propose a novel framework named Set-to-Sequence Ranking-based Concept-aware Learning Path Recommendation (SRC), which formulates the recommendation task under a set-to-sequence paradigm. Specifically, we first design a concept-aware encoder module which can capture the correlations among the input learning concepts. The outputs are then fed into a decoder module that sequentially generates a path through an attention mechanism that handles correlations between the learning and target concepts. Our recommendation policy is optimized by policy gradient. In addition, we also introduce an auxiliary module based on knowledge tracing to enhance the model's stability by evaluating students' learning effects on learning concepts. We conduct extensive experiments on two real-world public datasets and one industrial dataset, and the experimental results demonstrate the superiority and effectiveness of SRC. Code will be available at https://gitee.com/mindspore/models/tree/master/research/recommend/SRC.
Towards Return Parity in Markov Decision Processes
Nov 19, 2021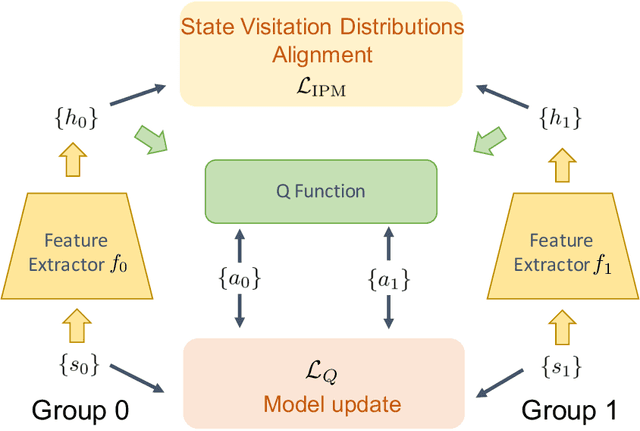

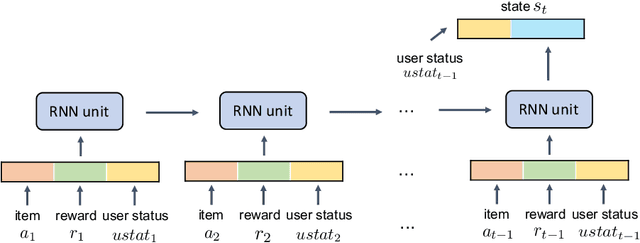
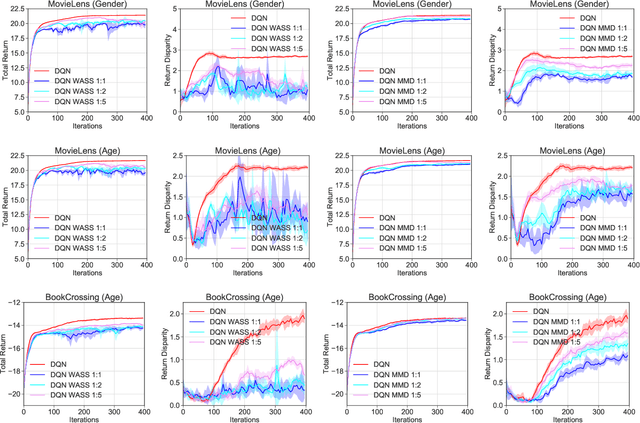
Algorithmic decisions made by machine learning models in high-stakes domains may have lasting impacts over time. Unfortunately, naive applications of standard fairness criterion in static settings over temporal domains may lead to delayed and adverse effects. To understand the dynamics of performance disparity, we study a fairness problem in Markov decision processes (MDPs). Specifically, we propose return parity, a fairness notion that requires MDPs from different demographic groups that share the same state and action spaces to achieve approximately the same expected time-discounted rewards. We first provide a decomposition theorem for return disparity, which decomposes the return disparity of any two MDPs into the distance between group-wise reward functions, the discrepancy of group policies, and the discrepancy between state visitation distributions induced by the group policies. Motivated by our decomposition theorem, we propose algorithms to mitigate return disparity via learning a shared group policy with state visitation distributional alignment using integral probability metrics. We conduct experiments to corroborate our results, showing that the proposed algorithm can successfully close the disparity gap while maintaining the performance of policies on two real-world recommender system benchmark datasets.
On Effective Scheduling of Model-based Reinforcement Learning
Nov 16, 2021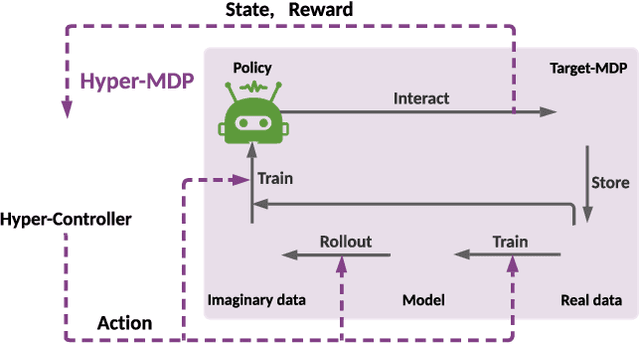
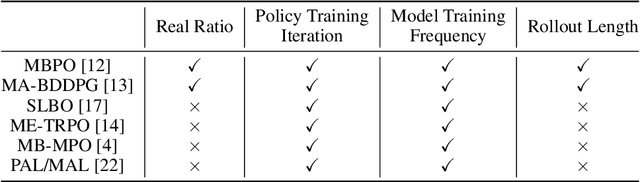
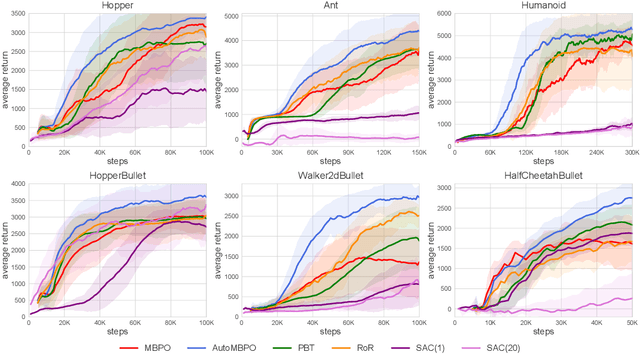

Model-based reinforcement learning has attracted wide attention due to its superior sample efficiency. Despite its impressive success so far, it is still unclear how to appropriately schedule the important hyperparameters to achieve adequate performance, such as the real data ratio for policy optimization in Dyna-style model-based algorithms. In this paper, we first theoretically analyze the role of real data in policy training, which suggests that gradually increasing the ratio of real data yields better performance. Inspired by the analysis, we propose a framework named AutoMBPO to automatically schedule the real data ratio as well as other hyperparameters in training model-based policy optimization (MBPO) algorithm, a representative running case of model-based methods. On several continuous control tasks, the MBPO instance trained with hyperparameters scheduled by AutoMBPO can significantly surpass the original one, and the real data ratio schedule found by AutoMBPO shows consistency with our theoretical analysis.
Curriculum Offline Imitation Learning
Nov 03, 2021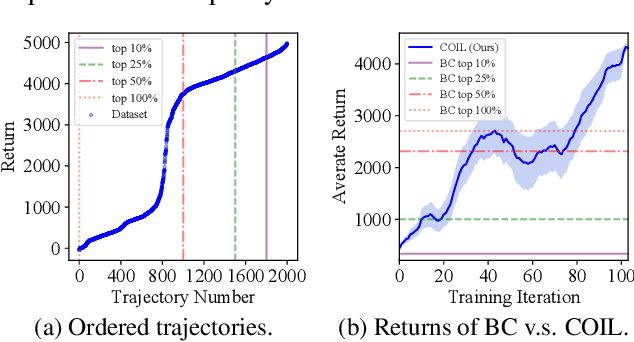
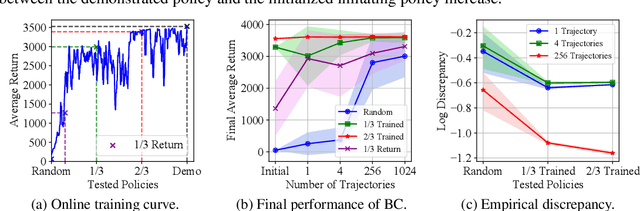
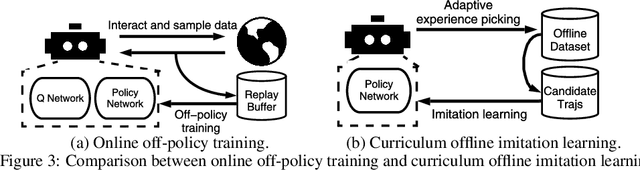

Offline reinforcement learning (RL) tasks require the agent to learn from a pre-collected dataset with no further interactions with the environment. Despite the potential to surpass the behavioral policies, RL-based methods are generally impractical due to the training instability and bootstrapping the extrapolation errors, which always require careful hyperparameter tuning via online evaluation. In contrast, offline imitation learning (IL) has no such issues since it learns the policy directly without estimating the value function by bootstrapping. However, IL is usually limited in the capability of the behavioral policy and tends to learn a mediocre behavior from the dataset collected by the mixture of policies. In this paper, we aim to take advantage of IL but mitigate such a drawback. Observing that behavior cloning is able to imitate neighboring policies with less data, we propose \textit{Curriculum Offline Imitation Learning (COIL)}, which utilizes an experience picking strategy for imitating from adaptive neighboring policies with a higher return, and improves the current policy along curriculum stages. On continuous control benchmarks, we compare COIL against both imitation-based and RL-based methods, showing that it not only avoids just learning a mediocre behavior on mixed datasets but is also even competitive with state-of-the-art offline RL methods.
Task-wise Split Gradient Boosting Trees for Multi-center Diabetes Prediction
Aug 16, 2021



Diabetes prediction is an important data science application in the social healthcare domain. There exist two main challenges in the diabetes prediction task: data heterogeneity since demographic and metabolic data are of different types, data insufficiency since the number of diabetes cases in a single medical center is usually limited. To tackle the above challenges, we employ gradient boosting decision trees (GBDT) to handle data heterogeneity and introduce multi-task learning (MTL) to solve data insufficiency. To this end, Task-wise Split Gradient Boosting Trees (TSGB) is proposed for the multi-center diabetes prediction task. Specifically, we firstly introduce task gain to evaluate each task separately during tree construction, with a theoretical analysis of GBDT's learning objective. Secondly, we reveal a problem when directly applying GBDT in MTL, i.e., the negative task gain problem. Finally, we propose a novel split method for GBDT in MTL based on the task gain statistics, named task-wise split, as an alternative to standard feature-wise split to overcome the mentioned negative task gain problem. Extensive experiments on a large-scale real-world diabetes dataset and a commonly used benchmark dataset demonstrate TSGB achieves superior performance against several state-of-the-art methods. Detailed case studies further support our analysis of negative task gain problems and provide insightful findings. The proposed TSGB method has been deployed as an online diabetes risk assessment software for early diagnosis.
Model-based Multi-agent Policy Optimization with Adaptive Opponent-wise Rollouts
May 19, 2021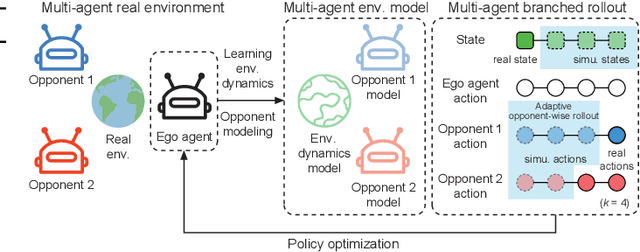
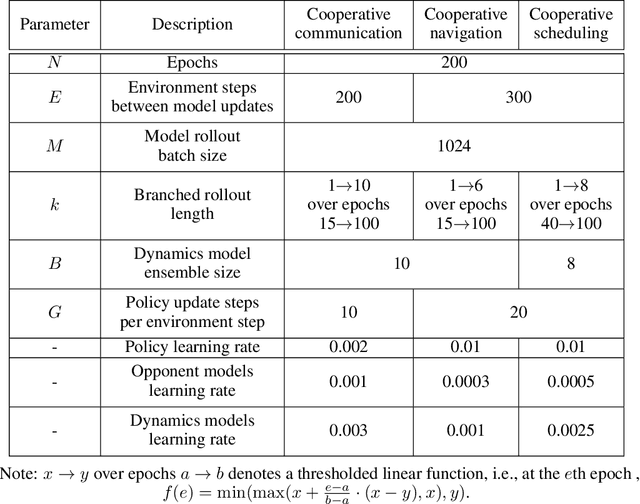
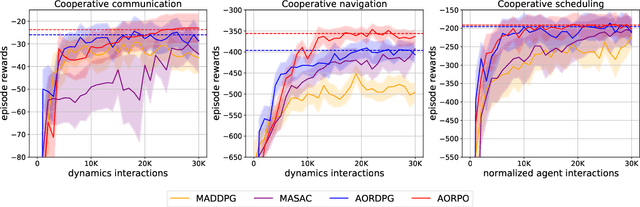
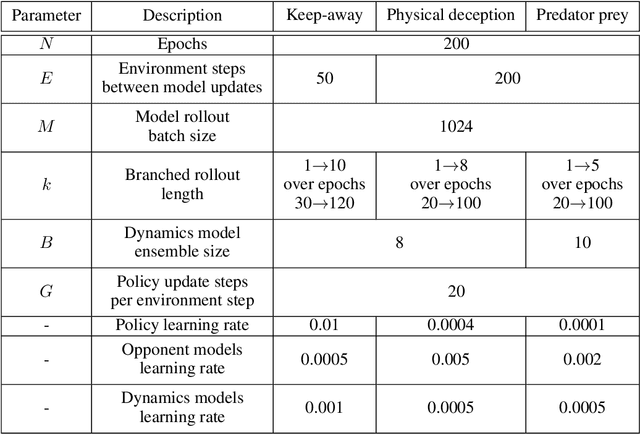
This paper investigates the model-based methods in multi-agent reinforcement learning (MARL). We specify the dynamics sample complexity and the opponent sample complexity in MARL, and conduct a theoretic analysis of return discrepancy upper bound. To reduce the upper bound with the intention of low sample complexity during the whole learning process, we propose a novel decentralized model-based MARL method, named Adaptive Opponent-wise Rollout Policy Optimization (AORPO). In AORPO, each agent builds its multi-agent environment model, consisting of a dynamics model and multiple opponent models, and trains its policy with the adaptive opponent-wise rollout. We further prove the theoretic convergence of AORPO under reasonable assumptions. Empirical experiments on competitive and cooperative tasks demonstrate that AORPO can achieve improved sample efficiency with comparable asymptotic performance over the compared MARL methods.