 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Effective Scheduling of Model-based Reinforcement Learning
Paper and Code
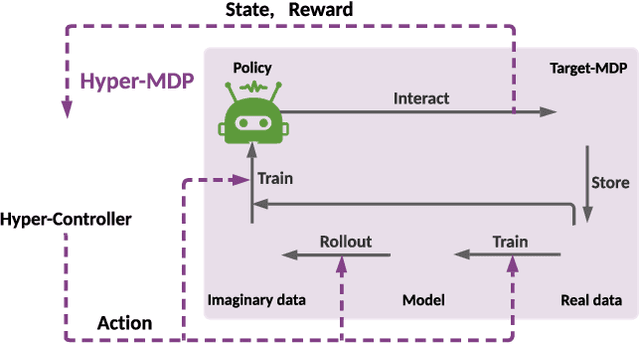
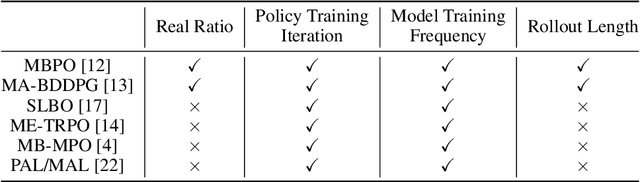
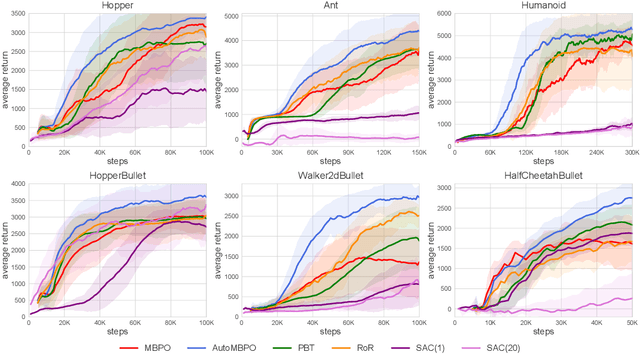

Model-based reinforcement learning has attracted wide attention due to its superior sample efficiency. Despite its impressive success so far, it is still unclear how to appropriately schedule the important hyperparameters to achieve adequate performance, such as the real data ratio for policy optimization in Dyna-style model-based algorithms. In this paper, we first theoretically analyze the role of real data in policy training, which suggests that gradually increasing the ratio of real data yields better performance. Inspired by the analysis, we propose a framework named AutoMBPO to automatically schedule the real data ratio as well as other hyperparameters in training model-based policy optimization (MBPO) algorithm, a representative running case of model-based methods. On several continuous control tasks, the MBPO instance trained with hyperparameters scheduled by AutoMBPO can significantly surpass the original one, and the real data ratio schedule found by AutoMBPO shows consistency with our theoretical analysis.