 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Horizon Rollout via Dynamics Diffusion for Offline Reinforcement Learning
Jun 09, 2024



With the great success of diffusion models (DMs) in generating realistic synthetic vision data, many researchers have investigated their potential in decision-making and control. Most of these works utilized DMs to sample directly from the trajectory space, where DMs can be viewed as a combination of dynamics models and policies. In this work, we explore how to decouple DMs' ability as dynamics models in fully offline settings, allowing the learning policy to roll out trajectories. As DMs learn the data distribution from the dataset, their intrinsic policy is actually the behavior policy induced from the dataset, which results in a mismatch between the behavior policy and the learning policy. We propose Dynamics Diffusion, short as DyDiff, which can inject information from the learning policy to DMs iteratively. DyDiff ensures long-horizon rollout accuracy while maintaining policy consistency and can be easily deployed on model-free algorithms. We provide theoretical analysis to show the advantage of DMs on long-horizon rollout over models and demonstrate the effectiveness of DyDiff in the context of offline reinforcement learning, where the rollout dataset is provided but no online environment for interaction. Our code is at https://github.com/FineArtz/DyDiff.
Diffusion-based Dynamics Models for Long-Horizon Rollout in Offline Reinforcement Learning
May 29, 2024With the great success of diffusion models (DMs) in generating realistic synthetic vision data, many researchers have investigated their potential in decision-making and control. Most of these works utilized DMs to sample directly from the trajectory space, where DMs can be viewed as a combination of dynamics models and policies. In this work, we explore how to decouple DMs' ability as dynamics models in fully offline settings, allowing the learning policy to roll out trajectories. As DMs learn the data distribution from the dataset, their intrinsic policy is actually the behavior policy induced from the dataset, which results in a mismatch between the behavior policy and the learning policy. We propose Dynamics Diffusion, short as DyDiff, which can inject information from the learning policy to DMs iteratively. DyDiff ensures long-horizon rollout accuracy while maintaining policy consistency and can be easily deployed on model-free algorithms. We provide theoretical analysis to show the advantage of DMs on long-horizon rollout over models and demonstrate the effectiveness of DyDiff in the context of offline reinforcement learning, where the rollout dataset is provided but no online environment for interaction. Our code is at https://github.com/FineArtz/DyDiff.
Diffusion Models for Reinforcement Learning: A Survey
Nov 02, 2023


Diffusion models have emerged as a prominent class of generative models, surpassing previous methods regarding sample quality and training stability. Recent works have shown the advantages of diffusion models in improving reinforcement learning (RL) solutions, including as trajectory planners, expressive policy classes, data synthesizers, etc. This survey aims to provide an overview of the advancements in this emerging field and hopes to inspire new avenues of research. First, we examine several challenges encountered by current RL algorithms. Then, we present a taxonomy of existing methods based on the roles played by diffusion models in RL and explore how the existing challenges are addressed. We further outline successful applications of diffusion models in various RL-related tasks while discussing the limitations of current approaches. Finally, we conclude the survey and offer insights into future research directions, focusing on enhancing model performance and applying diffusion models to broader tasks. We are actively maintaining a GitHub repository for papers and other related resources in applying diffusion models in RL: https://github.com/apexrl/Diff4RLSurvey .
Bootstrapped Transformer for Offline Reinforcement Learning
Jun 17, 2022
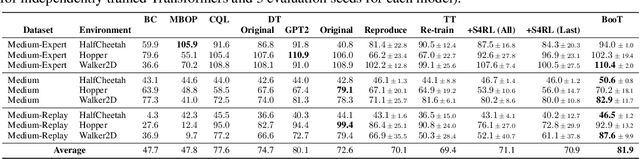

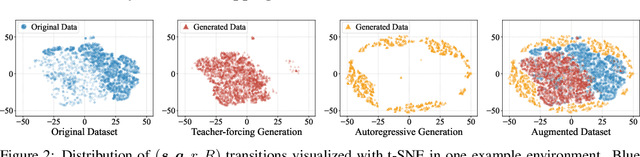
Offline reinforcement learning (RL) aims at learning policies from previously collected static trajectory data without interacting with the real environment. Recent works provide a novel perspective by viewing offline RL as a generic sequence generation problem, adopting sequence models such as Transformer architecture to model distributions over trajectories, and repurposing beam search as a planning algorithm. However, the training datasets utilized in general offline RL tasks are quite limited and often suffer from insufficient distribution coverage, which could be harmful to training sequence generation models yet has not drawn enough attention in the previous works. In this paper, we propose a novel algorithm named Bootstrapped Transformer, which incorporates the idea of bootstrapping and leverages the learned model to self-generate more offline data to further boost the sequence model training. We conduct extensive experiments on two offline RL benchmarks and demonstrate that our model can largely remedy the existing offline RL training limitations and beat other strong baseline methods. We also analyze the generated pseudo data and the revealed characteristics may shed some light on offline RL training. The codes are available at https://seqml.github.io/bootorl.
Curriculum Offline Imitation Learning
Nov 03, 2021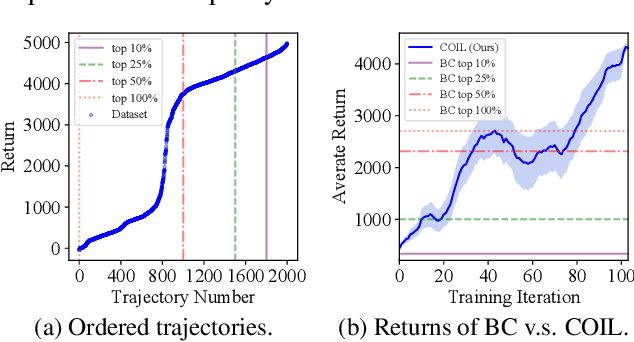
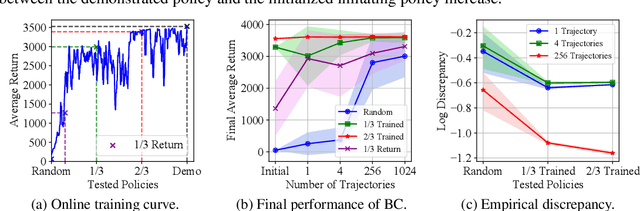
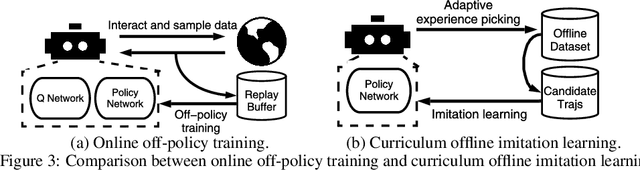

Offline reinforcement learning (RL) tasks require the agent to learn from a pre-collected dataset with no further interactions with the environment. Despite the potential to surpass the behavioral policies, RL-based methods are generally impractical due to the training instability and bootstrapping the extrapolation errors, which always require careful hyperparameter tuning via online evaluation. In contrast, offline imitation learning (IL) has no such issues since it learns the policy directly without estimating the value function by bootstrapping. However, IL is usually limited in the capability of the behavioral policy and tends to learn a mediocre behavior from the dataset collected by the mixture of policies. In this paper, we aim to take advantage of IL but mitigate such a drawback. Observing that behavior cloning is able to imitate neighboring policies with less data, we propose \textit{Curriculum Offline Imitation Learning (COIL)}, which utilizes an experience picking strategy for imitating from adaptive neighboring policies with a higher return, and improves the current policy along curriculum stages. On continuous control benchmarks, we compare COIL against both imitation-based and RL-based methods, showing that it not only avoids just learning a mediocre behavior on mixed datasets but is also even competitive with state-of-the-art offline RL methods.