 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's all In the (Exponential) Family: An Equivalence between Maximum Likelihood Estimation and Control Variates for Sketching Algorithms
Feb 04, 2026Maximum likelihood estimators (MLE) and control variate estimators (CVE) have been used in conjunction with known information across sketching algorithms and applications in machine learning. We prove that under certain conditions in an exponential family, an optimal CVE will achieve the same asymptotic variance as the MLE, giving an Expectation-Maximization (EM) algorithm for the MLE. Experiments show the EM algorithm is faster and numerically stable compared to other root finding algorithms for the MLE for the bivariate Normal distribution, and we expect this to hold across distributions satisfying these conditions. We show how the EM algorithm leads to reproducibility for algorithms using MLE / CVE, and demonstrate how the EM algorithm leads to finding the MLE when the CV weights are known.
It's all the (Exponential) Family: An Equivalence between Maximum Likelihood Estimation and Control Variates for Sketching Algorithms
Jan 29, 2026Maximum likelihood estimators (MLE) and control variate estimators (CVE) have been used in conjunction with known information across sketching algorithms and applications in machine learning. We prove that under certain conditions in an exponential family, an optimal CVE will achieve the same asymptotic variance as the MLE, giving an Expectation-Maximization (EM) algorithm for the MLE. Experiments show the EM algorithm is faster and numerically stable compared to other root finding algorithms for the MLE for the bivariate Normal distribution, and we expect this to hold across distributions satisfying these conditions. We show how the EM algorithm leads to reproducibility for algorithms using MLE / CVE, and demonstrate how the EM algorithm leads to finding the MLE when the CV weights are known.
Bootstrapped Transformer for Offline Reinforcement Learning
Jun 17, 2022
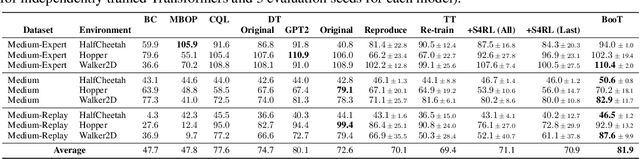

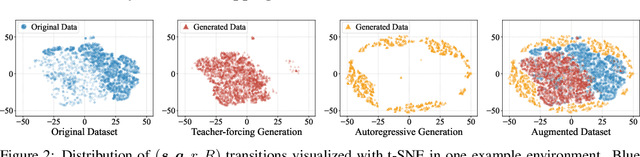
Offline reinforcement learning (RL) aims at learning policies from previously collected static trajectory data without interacting with the real environment. Recent works provide a novel perspective by viewing offline RL as a generic sequence generation problem, adopting sequence models such as Transformer architecture to model distributions over trajectories, and repurposing beam search as a planning algorithm. However, the training datasets utilized in general offline RL tasks are quite limited and often suffer from insufficient distribution coverage, which could be harmful to training sequence generation models yet has not drawn enough attention in the previous works. In this paper, we propose a novel algorithm named Bootstrapped Transformer, which incorporates the idea of bootstrapping and leverages the learned model to self-generate more offline data to further boost the sequence model training. We conduct extensive experiments on two offline RL benchmarks and demonstrate that our model can largely remedy the existing offline RL training limitations and beat other strong baseline methods. We also analyze the generated pseudo data and the revealed characteristics may shed some light on offline RL training. The codes are available at https://seqml.github.io/bootorl.
Learning to Select Cuts for Efficient Mixed-Integer Programming
May 28, 2021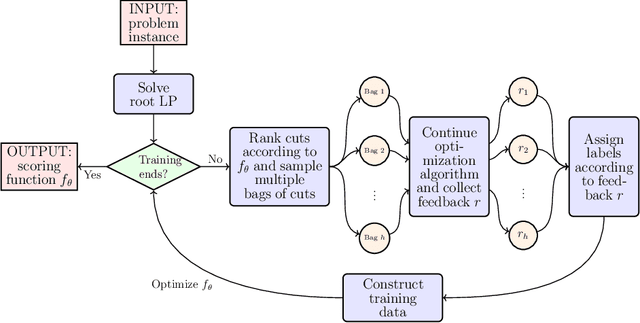
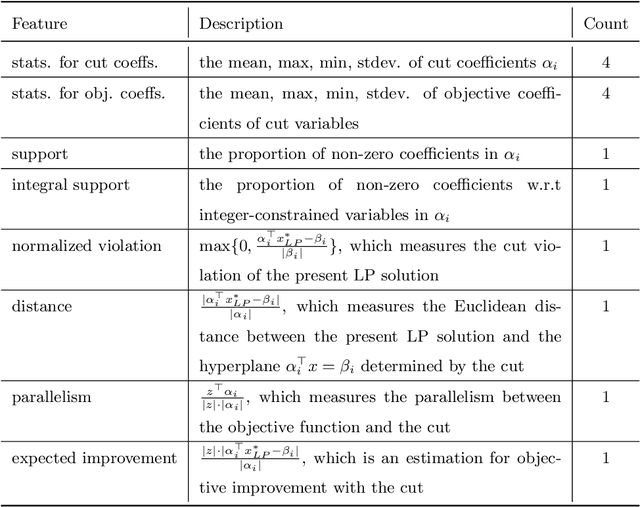

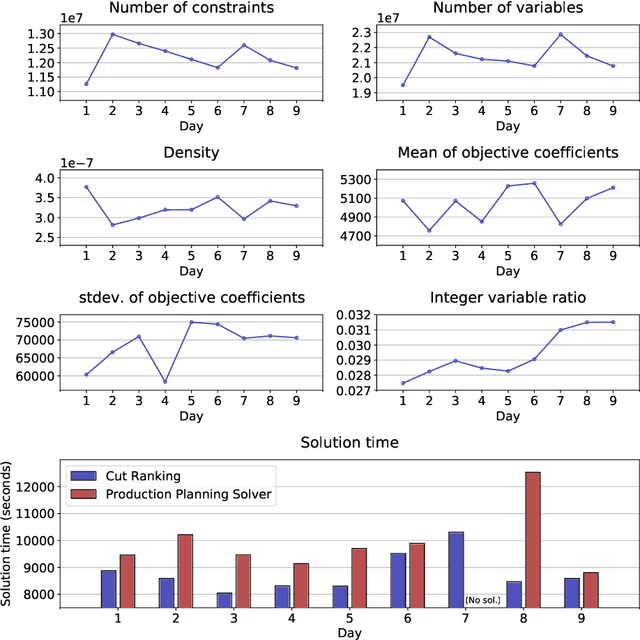
Cutting plane methods play a significant role in modern solvers for tackling mixed-integer programming (MIP) problems. Proper selection of cuts would remove infeasible solutions in the early stage, thus largely reducing the computational burden without hurting the solution accuracy. However, the major cut selection approaches heavily rely on heuristics, which strongly depend on the specific problem at hand and thus limit their generalization capability. In this paper, we propose a data-driven and generalizable cut selection approach, named Cut Ranking, in the settings of multiple instance learning. To measure the quality of the candidate cuts, a scoring function, which takes the instance-specific cut features as inputs, is trained and applied in cut ranking and selection. In order to evaluate our method, we conduct extensive experiments on both synthetic datasets and real-world datasets. Compared with commonly used heuristics for cut selection, the learning-based policy has shown to be more effective, and is capable of generalizing over multiple problems with different properties. Cut Ranking has been deployed in an industrial solver for large-scale MIPs. In the online A/B testing of the product planning problems with more than $10^7$ variables and constraints daily, Cut Ranking has achieved the average speedup ratio of 12.42% over the production solver without any accuracy loss of solution.
GIKT: A Graph-based Interaction Model for Knowledge Tracing
Sep 13, 2020
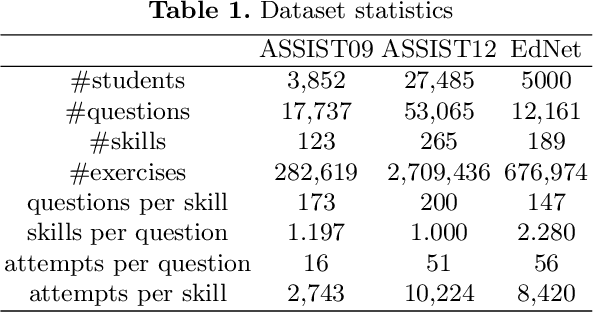
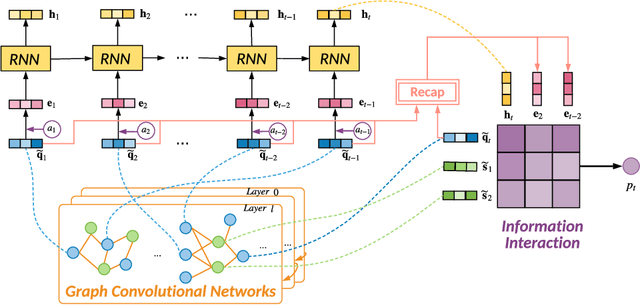
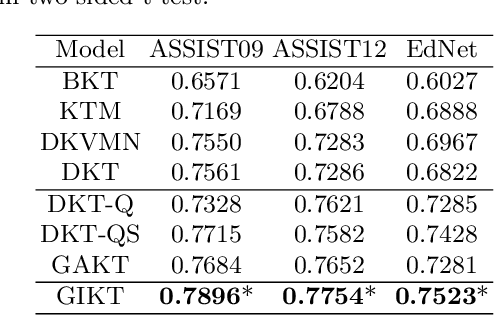
With the rapid development in online education, knowledge tracing (KT) has become a fundamental problem which traces students' knowledge status and predicts their performance on new questions. Questions are often numerous in online education systems, and are always associated with much fewer skills. However, the previous literature fails to involve question information together with high-order question-skill correlations, which is mostly limited by data sparsity and multi-skill problems. From the model perspective, previous models can hardly capture the long-term dependency of student exercise history, and cannot model the interactions between student-questions, and student-skills in a consistent way. In this paper, we propose a Graph-based Interaction model for Knowledge Tracing (GIKT) to tackle the above probems. More specifically, GIKT utilizes graph convolutional network (GCN) to substantially incorporate question-skill correlations via embedding propagation. Besides, considering that relevant questions are usually scattered throughout the exercise history, and that question and skill are just different instantiations of knowledge, GIKT generalizes the degree of students' master of the question to the interactions between the student's current state, the student's history related exercises, the target question, and related skills. Experiments on three datasets demonstrate that GIKT achieves the new state-of-the-art performance, with at least 1% absolute AUC improvement.