 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeh-MINT: Modeling Pocket-Ligand Binding with Hierarchical Molecular Interaction Network
Apr 25, 2026Accurate molecular representations are critical for drug discovery, and a central challenge lies in capturing the chemical environment of molecular fragments, as key interactions, such as H-bond and π stacking, occur only under specific local conditions. Most existing approaches represent molecules as atom-level graphs; however, atom-level representations can hardly express higher-order chemical context (e.g., stereochemistry, lone pairs, conjugation). Fragment-based methods (e.g., principal subgraph, predefined functional groups) fail to preserve essential information such as chirality, aromaticity, and ionic states. This work addresses these limitations from two aspects. (i) OverlapBPE tokenization. We propose a novel data-driven molecule tokenization method. Unlike existing approaches, our method allows overlapping fragments, reflecting the inherently fuzzy boundaries of small-molecule substructures and, together with enriched chemical information at the token level, thereby preserving a more complete chemical context. (ii) h-MINT model. OverlapBPE induces many-to-many atom-fragment mappings, which necessitate a new hierarchical architecture. We therefore develop a hierarchical molecular interaction network capable of jointly modeling interactions at both atom and fragment levels. By supporting fragment overlaps, the model naturally accommodates the many-to-many atom-fragment mappings introduced by the OverlapBPE scheme. Extensive evaluation against state-of-the-art methods shows our method improves binding affinity prediction by 2-4% Pearson/Spearman correlation on PDBBind and LBA, enhances virtual screening by 1-3% in key metrics on DUD-E and LIT-PCBA, and achieves the best overall HTS performance on PubChem assays. Further analysis demonstrates that our method effectively captures interactive information while maintaining good generalization.
Protein Autoregressive Modeling via Multiscale Structure Generation
Feb 04, 2026We present protein autoregressive modeling (PAR), the first multi-scale autoregressive framework for protein backbone generation via coarse-to-fine next-scale prediction. Using the hierarchical nature of proteins, PAR generates structures that mimic sculpting a statue, forming a coarse topology and refining structural details over scales. To achieve this, PAR consists of three key components: (i) multi-scale downsampling operations that represent protein structures across multiple scales during training; (ii) an autoregressive transformer that encodes multi-scale information and produces conditional embeddings to guide structure generation; (iii) a flow-based backbone decoder that generates backbone atoms conditioned on these embeddings. Moreover, autoregressive models suffer from exposure bias, caused by the training and the generation procedure mismatch, and substantially degrades structure generation quality. We effectively alleviate this issue by adopting noisy context learning and scheduled sampling, enabling robust backbone generation. Notably, PAR exhibits strong zero-shot generalization, supporting flexible human-prompted conditional generation and motif scaffolding without requiring fine-tuning. On the unconditional generation benchmark, PAR effectively learns protein distributions and produces backbones of high design quality, and exhibits favorable scaling behavior. Together, these properties establish PAR as a promising framework for protein structure generation.
Flow Matching Meets Biology and Life Science: A Survey
Jul 23, 2025Over the past decade, advances in generative modeling, such as generative adversarial networks, masked autoencoders, and diffusion models, have significantly transformed biological research and discovery, enabling breakthroughs in molecule design, protein generation, drug discovery, and beyond. At the same time, biological applications have served as valuable testbeds for evaluating the capabilities of generative models. Recently, flow matching has emerged as a powerful and efficient alternative to diffusion-based generative modeling, with growing interest in its application to problems in biology and life sciences. This paper presents the first comprehensive survey of recent developments in flow matching and its applications in biological domains. We begin by systematically reviewing the foundations and variants of flow matching, and then categorize its applications into three major areas: biological sequence modeling, molecule generation and design, and peptide and protein generation. For each, we provide an in-depth review of recent progress. We also summarize commonly used datasets and software tools, and conclude with a discussion of potential future directions. The corresponding curated resources are available at https://github.com/Violet24K/Awesome-Flow-Matching-Meets-Biology.
Training Free Guided Flow Matching with Optimal Control
Oct 23, 2024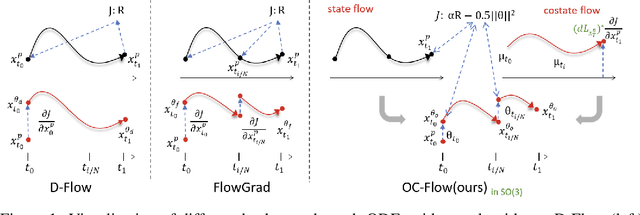


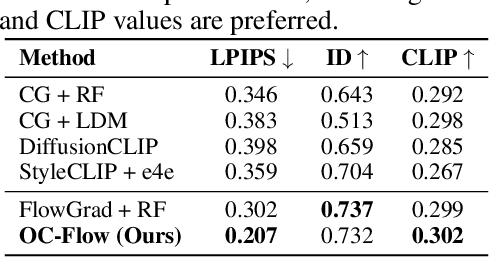
Controlled generation with pre-trained Diffusion and Flow Matching models has vast applications. One strategy for guiding ODE-based generative models is through optimizing a target loss $R(x_1)$ while staying close to the prior distribution. Along this line, some recent work showed the effectiveness of guiding flow model by differentiating through its ODE sampling process. Despite the superior performance, the theoretical understanding of this line of methods is still preliminary, leaving space for algorithm improvement. Moreover, existing methods predominately focus on Euclidean data manifold, and there is a compelling need for guided flow methods on complex geometries such as SO(3), which prevails in high-stake scientific applications like protein design. We present OC-Flow, a general and theoretically grounded training-free framework for guided flow matching using optimal control. Building upon advances in optimal control theory, we develop effective and practical algorithms for solving optimal control in guided ODE-based generation and provide a systematic theoretical analysis of the convergence guarantee in both Euclidean and SO(3). We show that existing backprop-through-ODE methods can be interpreted as special cases of Euclidean OC-Flow. OC-Flow achieved superior performance in extensive experiments on text-guided image manipulation, conditional molecule generation, and all-atom peptide design.
MolCRAFT: Structure-Based Drug Design in Continuous Parameter Space
Apr 18, 2024Generative models for structure-based drug design (SBDD) have shown promising results in recent years. Existing works mainly focus on how to generate molecules with higher binding affinity, ignoring the feasibility prerequisites for generated 3D poses and resulting in false positives. We conduct thorough studies on key factors of ill-conformational problems when applying autoregressive methods and diffusion to SBDD, including mode collapse and hybrid continuous-discrete space. In this paper, we introduce \ours, the first SBDD model that operates in the continuous parameter space, together with a novel noise reduced sampling strategy. Empirical results show that our model consistently achieves superior performance in binding affinity with more stable 3D structure, demonstrating our ability to accurately model interatomic interactions. To our best knowledge, MolCRAFT is the first to achieve reference-level Vina Scores (-6.59 kcal/mol), outperforming other strong baselines by a wide margin (-0.84 kcal/mol). Code is available at https://github.com/AlgoMole/MolCRAFT.
Unified Generative Modeling of 3D Molecules via Bayesian Flow Networks
Mar 17, 2024Advanced generative model (e.g., diffusion model) derived from simplified continuity assumptions of data distribution, though showing promising progress, has been difficult to apply directly to geometry generation applications due to the multi-modality and noise-sensitive nature of molecule geometry. This work introduces Geometric Bayesian Flow Networks (GeoBFN), which naturally fits molecule geometry by modeling diverse modalities in the differentiable parameter space of distributions. GeoBFN maintains the SE-(3) invariant density modeling property by incorporating equivariant inter-dependency modeling on parameters of distributions and unifying the probabilistic modeling of different modalities. Through optimized training and sampling techniques, we demonstrate that GeoBFN achieves state-of-the-art performance on multiple 3D molecule generation benchmarks in terms of generation quality (90.87% molecule stability in QM9 and 85.6% atom stability in GEOM-DRUG. GeoBFN can also conduct sampling with any number of steps to reach an optimal trade-off between efficiency and quality (e.g., 20-times speedup without sacrificing performance).
ClickPrompt: CTR Models are Strong Prompt Generators for Adapting Language Models to CTR Prediction
Oct 17, 2023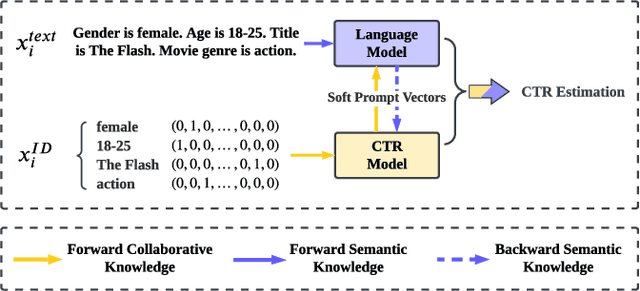
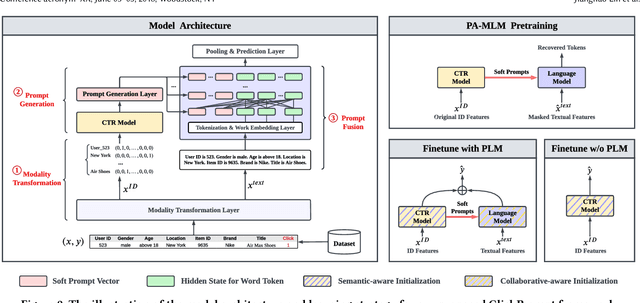
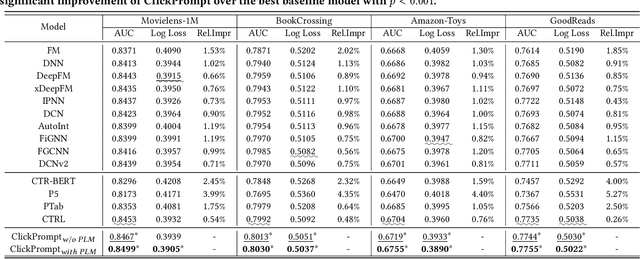
Click-through rate (CTR) prediction has become increasingly indispensable for various Internet applications. Traditional CTR models convert the multi-field categorical data into ID features via one-hot encoding, and extract the collaborative signals among features. Such a paradigm suffers from the problem of semantic information loss. Another line of research explores the potential of pretrained language models (PLMs) for CTR prediction by converting input data into textual sentences through hard prompt templates. Although semantic signals are preserved, they generally fail to capture the collaborative information (e.g., feature interactions, pure ID features), not to mention the unacceptable inference overhead brought by the huge model size. In this paper, we aim to model both the semantic knowledge and collaborative knowledge for accurate CTR estimation, and meanwhile address the inference inefficiency issue. To benefit from both worlds and close their gaps, we propose a novel model-agnostic framework (i.e., ClickPrompt), where we incorporate CTR models to generate interaction-aware soft prompts for PLMs. We design a prompt-augmented masked language modeling (PA-MLM) pretraining task, where PLM has to recover the masked tokens based on the language context, as well as the soft prompts generated by CTR model. The collaborative and semantic knowledge from ID and textual features would be explicitly aligned and interacted via the prompt interface. Then, we can either tune the CTR model with PLM for superior performance, or solely tune the CTR model without PLM for inference efficiency. Experiments on four real-world datasets validate the effectiveness of ClickPrompt compared with existing baselines.
MAP: A Model-agnostic Pretraining Framework for Click-through Rate Prediction
Aug 03, 2023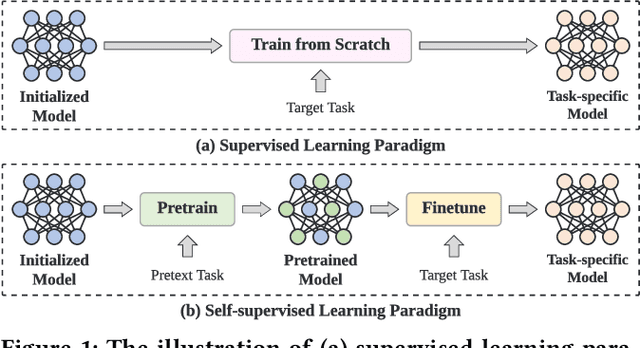
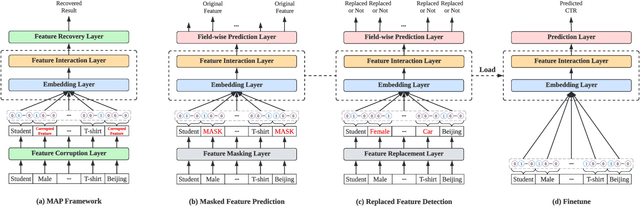
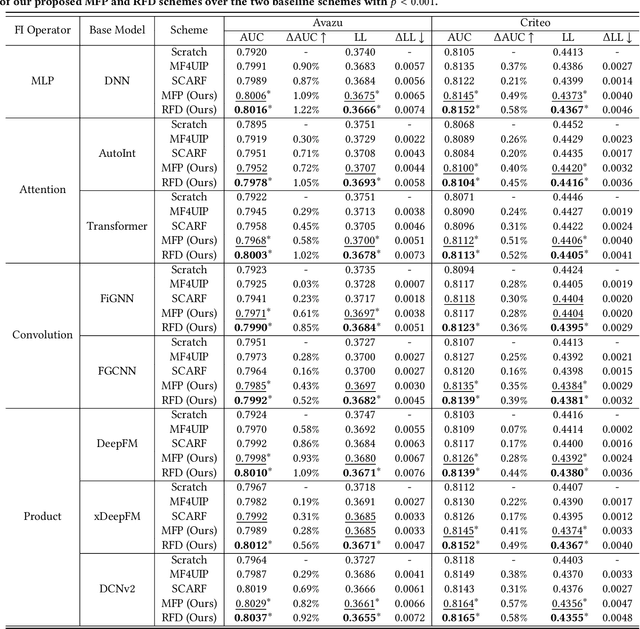
With the widespread application of personalized online services, click-through rate (CTR) prediction has received more and more attention and research. The most prominent features of CTR prediction are its multi-field categorical data format, and vast and daily-growing data volume. The large capacity of neural models helps digest such massive amounts of data under the supervised learning paradigm, yet they fail to utilize the substantial data to its full potential, since the 1-bit click signal is not sufficient to guide the model to learn capable representations of features and instances. The self-supervised learning paradigm provides a more promising pretrain-finetune solution to better exploit the large amount of user click logs, and learn more generalized and effective representations. However, self-supervised learning for CTR prediction is still an open question, since current works on this line are only preliminary and rudimentary. To this end, we propose a Model-agnostic pretraining (MAP) framework that applies feature corruption and recovery on multi-field categorical data, and more specifically, we derive two practical algorithms: masked feature prediction (MFP) and replaced feature detection (RFD). MFP digs into feature interactions within each instance through masking and predicting a small portion of input features, and introduces noise contrastive estimation (NCE) to handle large feature spaces. RFD further turns MFP into a binary classification mode through replacing and detecting changes in input features, making it even simpler and more effective for CTR pretraining. Our extensive experiments on two real-world large-scale datasets (i.e., Avazu, Criteo) demonstrate the advantages of these two methods on several strong backbones (e.g., DCNv2, DeepFM), and achieve new state-of-the-art performance in terms of both effectiveness and efficiency for CTR prediction.
Task-wise Split Gradient Boosting Trees for Multi-center Diabetes Prediction
Aug 16, 2021



Diabetes prediction is an important data science application in the social healthcare domain. There exist two main challenges in the diabetes prediction task: data heterogeneity since demographic and metabolic data are of different types, data insufficiency since the number of diabetes cases in a single medical center is usually limited. To tackle the above challenges, we employ gradient boosting decision trees (GBDT) to handle data heterogeneity and introduce multi-task learning (MTL) to solve data insufficiency. To this end, Task-wise Split Gradient Boosting Trees (TSGB) is proposed for the multi-center diabetes prediction task. Specifically, we firstly introduce task gain to evaluate each task separately during tree construction, with a theoretical analysis of GBDT's learning objective. Secondly, we reveal a problem when directly applying GBDT in MTL, i.e., the negative task gain problem. Finally, we propose a novel split method for GBDT in MTL based on the task gain statistics, named task-wise split, as an alternative to standard feature-wise split to overcome the mentioned negative task gain problem. Extensive experiments on a large-scale real-world diabetes dataset and a commonly used benchmark dataset demonstrate TSGB achieves superior performance against several state-of-the-art methods. Detailed case studies further support our analysis of negative task gain problems and provide insightful findings. The proposed TSGB method has been deployed as an online diabetes risk assessment software for early diagnosis.
A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation
Oct 23, 2020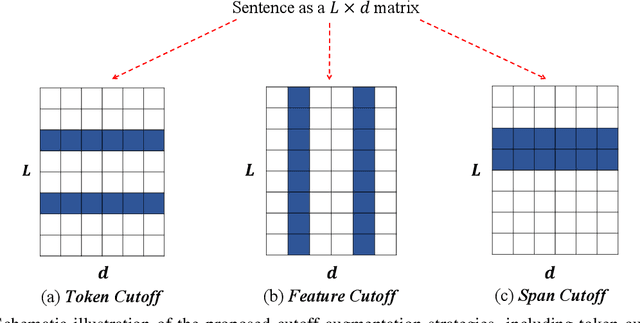
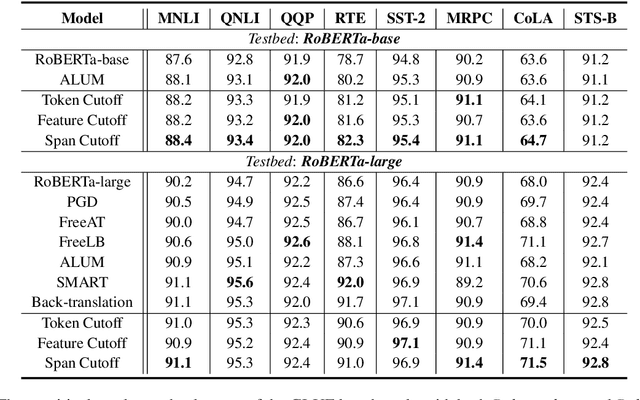

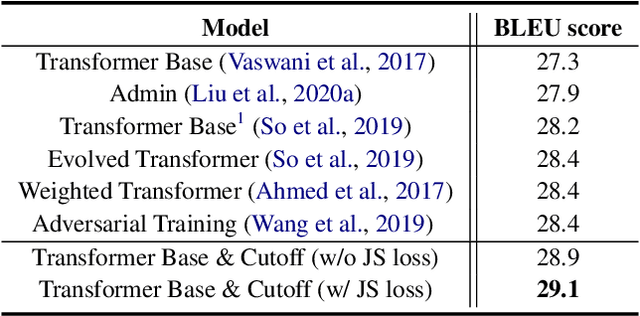
Adversarial training has been shown effective at endowing the learned representations with stronger generalization ability. However, it typically requires expensive computation to determine the direction of the injected perturbations. In this paper, we introduce a set of simple yet effective data augmentation strategies dubbed cutoff, where part of the information within an input sentence is erased to yield its restricted views (during the fine-tuning stage). Notably, this process relies merely on stochastic sampling and thus adds little computational overhead. A Jensen-Shannon Divergence consistency loss is further utilized to incorporate these augmented samples into the training objective in a principled manner. To verify the effectiveness of the proposed strategies, we apply cutoff to both natural language understanding and generation problems. On the GLUE benchmark, it is demonstrated that cutoff, in spite of its simplicity, performs on par or better than several competitive adversarial-based approaches. We further extend cutoff to machine translation and observe significant gains in BLEU scores (based upon the Transformer Base model). Moreover, cutoff consistently outperforms adversarial training and achieves state-of-the-art results on the IWSLT2014 German-English dataset.