 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAP: A Model-agnostic Pretraining Framework for Click-through Rate Prediction
Paper and Code
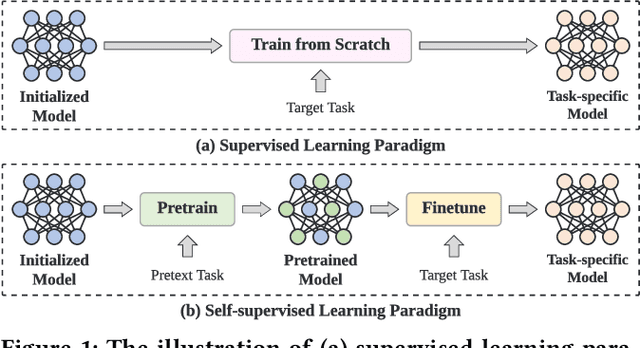
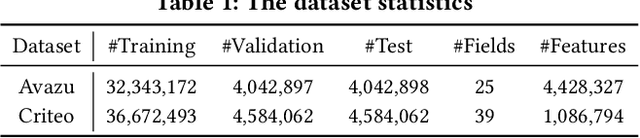
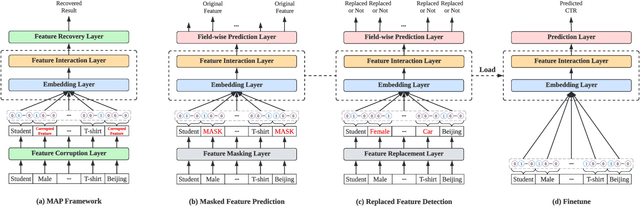
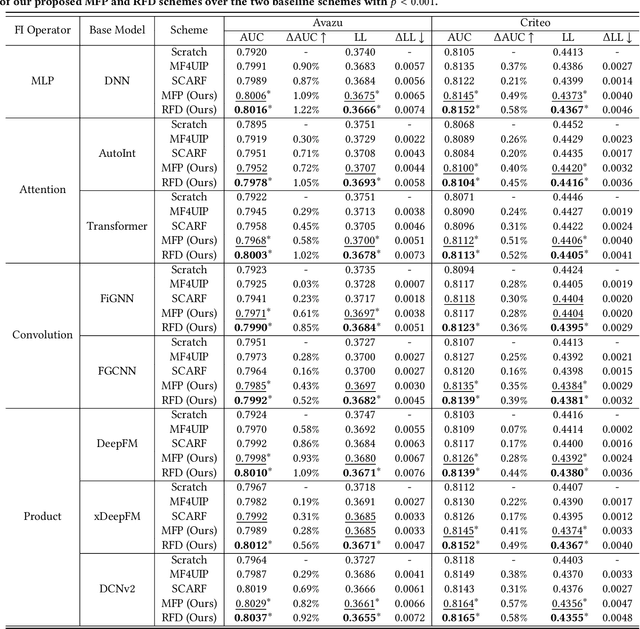
With the widespread application of personalized online services, click-through rate (CTR) prediction has received more and more attention and research. The most prominent features of CTR prediction are its multi-field categorical data format, and vast and daily-growing data volume. The large capacity of neural models helps digest such massive amounts of data under the supervised learning paradigm, yet they fail to utilize the substantial data to its full potential, since the 1-bit click signal is not sufficient to guide the model to learn capable representations of features and instances. The self-supervised learning paradigm provides a more promising pretrain-finetune solution to better exploit the large amount of user click logs, and learn more generalized and effective representations. However, self-supervised learning for CTR prediction is still an open question, since current works on this line are only preliminary and rudimentary. To this end, we propose a Model-agnostic pretraining (MAP) framework that applies feature corruption and recovery on multi-field categorical data, and more specifically, we derive two practical algorithms: masked feature prediction (MFP) and replaced feature detection (RFD). MFP digs into feature interactions within each instance through masking and predicting a small portion of input features, and introduces noise contrastive estimation (NCE) to handle large feature spaces. RFD further turns MFP into a binary classification mode through replacing and detecting changes in input features, making it even simpler and more effective for CTR pretraining. Our extensive experiments on two real-world large-scale datasets (i.e., Avazu, Criteo) demonstrate the advantages of these two methods on several strong backbones (e.g., DCNv2, DeepFM), and achieve new state-of-the-art performance in terms of both effectiveness and efficiency for CTR prediction.