 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROMO: Retrieval-enhanced Offline Model-based Optimization
Oct 19, 2023Data-driven black-box model-based optimization (MBO) problems arise in a great number of practical application scenarios, where the goal is to find a design over the whole space maximizing a black-box target function based on a static offline dataset. In this work, we consider a more general but challenging MBO setting, named constrained MBO (CoMBO), where only part of the design space can be optimized while the rest is constrained by the environment. A new challenge arising from CoMBO is that most observed designs that satisfy the constraints are mediocre in evaluation. Therefore, we focus on optimizing these mediocre designs in the offline dataset while maintaining the given constraints rather than further boosting the best observed design in the traditional MBO setting. We propose retrieval-enhanced offline model-based optimization (ROMO), a new derivable forward approach that retrieves the offline dataset and aggregates relevant samples to provide a trusted prediction, and use it for gradient-based optimization. ROMO is simple to implement and outperforms state-of-the-art approaches in the CoMBO setting. Empirically, we conduct experiments on a synthetic Hartmann (3D) function dataset, an industrial CIO dataset, and a suite of modified tasks in the Design-Bench benchmark. Results show that ROMO performs well in a wide range of constrained optimization tasks.
Task-wise Split Gradient Boosting Trees for Multi-center Diabetes Prediction
Aug 16, 2021



Diabetes prediction is an important data science application in the social healthcare domain. There exist two main challenges in the diabetes prediction task: data heterogeneity since demographic and metabolic data are of different types, data insufficiency since the number of diabetes cases in a single medical center is usually limited. To tackle the above challenges, we employ gradient boosting decision trees (GBDT) to handle data heterogeneity and introduce multi-task learning (MTL) to solve data insufficiency. To this end, Task-wise Split Gradient Boosting Trees (TSGB) is proposed for the multi-center diabetes prediction task. Specifically, we firstly introduce task gain to evaluate each task separately during tree construction, with a theoretical analysis of GBDT's learning objective. Secondly, we reveal a problem when directly applying GBDT in MTL, i.e., the negative task gain problem. Finally, we propose a novel split method for GBDT in MTL based on the task gain statistics, named task-wise split, as an alternative to standard feature-wise split to overcome the mentioned negative task gain problem. Extensive experiments on a large-scale real-world diabetes dataset and a commonly used benchmark dataset demonstrate TSGB achieves superior performance against several state-of-the-art methods. Detailed case studies further support our analysis of negative task gain problems and provide insightful findings. The proposed TSGB method has been deployed as an online diabetes risk assessment software for early diagnosis.
Latent Attention For If-Then Program Synthesis
Nov 07, 2016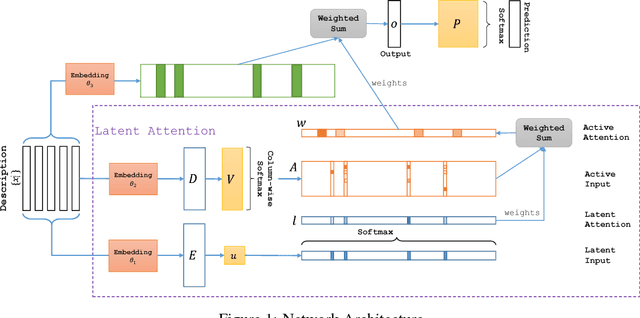
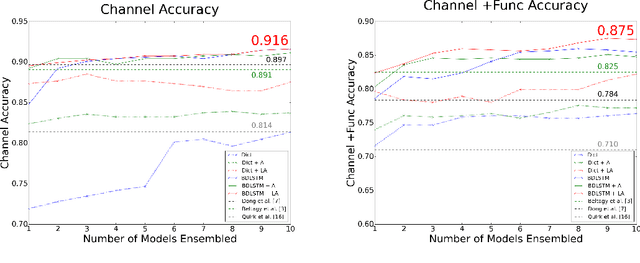
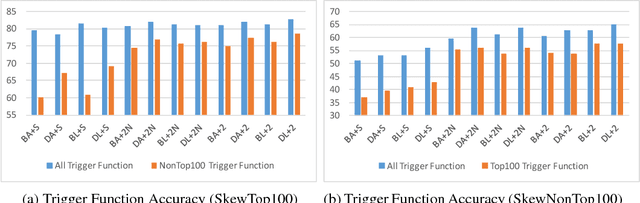
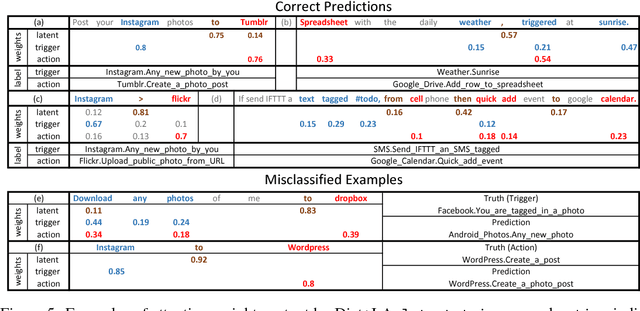
Automatic translation from natural language descriptions into programs is a longstanding challenging problem. In this work, we consider a simple yet important sub-problem: translation from textual descriptions to If-Then programs. We devise a novel neural network architecture for this task which we train end-to-end. Specifically, we introduce Latent Attention, which computes multiplicative weights for the words in the description in a two-stage process with the goal of better leveraging the natural language structures that indicate the relevant parts for predicting program elements. Our architecture reduces the error rate by 28.57% compared to prior art. We also propose a one-shot learning scenario of If-Then program synthesis and simulate it with our existing dataset. We demonstrate a variation on the training procedure for this scenario that outperforms the original procedure, significantly closing the gap to the model trained with all data.