 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule By Example: Harnessing Logical Rules for Explainable Hate Speech Detection
Jul 24, 2023Classic approaches to content moderation typically apply a rule-based heuristic approach to flag content. While rules are easily customizable and intuitive for humans to interpret, they are inherently fragile and lack the flexibility or robustness needed to moderate the vast amount of undesirable content found online today. Recent advances in deep learning have demonstrated the promise of using highly effective deep neural models to overcome these challenges. However, despite the improved performance, these data-driven models lack transparency and explainability, often leading to mistrust from everyday users and a lack of adoption by many platforms. In this paper, we present Rule By Example (RBE): a novel exemplar-based contrastive learning approach for learning from logical rules for the task of textual content moderation. RBE is capable of providing rule-grounded predictions, allowing for more explainable and customizable predictions compared to typical deep learning-based approaches. We demonstrate that our approach is capable of learning rich rule embedding representations using only a few data examples. Experimental results on 3 popular hate speech classification datasets show that RBE is able to outperform state-of-the-art deep learning classifiers as well as the use of rules in both supervised and unsupervised settings while providing explainable model predictions via rule-grounding.
Rethinking Multimodal Content Moderation from an Asymmetric Angle with Mixed-modality
May 17, 2023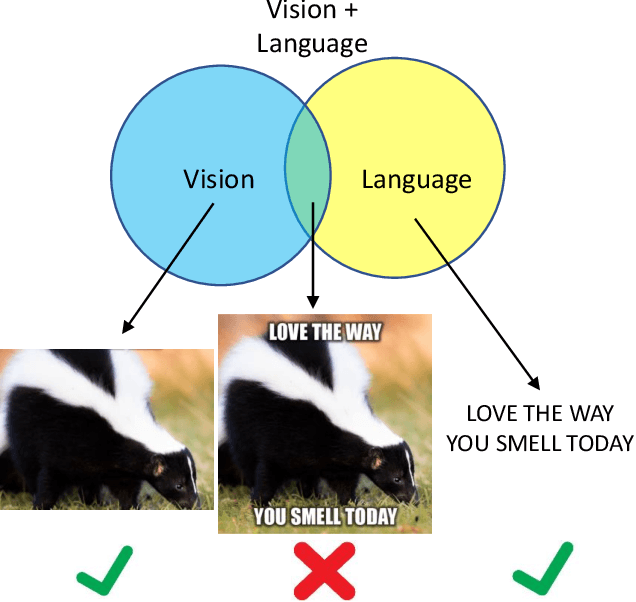
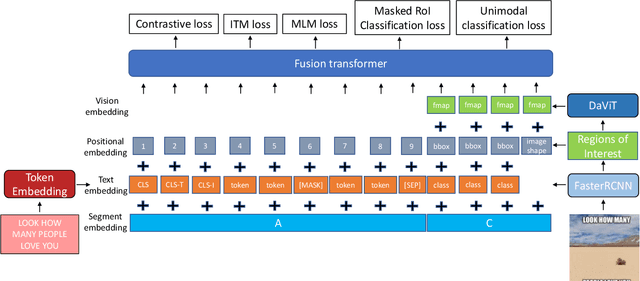
There is a rapidly growing need for multimodal content moderation (CM) as more and more content on social media is multimodal in nature. Existing unimodal CM systems may fail to catch harmful content that crosses modalities (e.g., memes or videos), which may lead to severe consequences. In this paper, we present a novel CM model, Asymmetric Mixed-Modal Moderation (AM3), to target multimodal and unimodal CM tasks. Specifically, to address the asymmetry in semantics between vision and language, AM3 has a novel asymmetric fusion architecture that is designed to not only fuse the common knowledge in both modalities but also to exploit the unique information in each modality. Unlike previous works that focus on fusing the two modalities while overlooking the intrinsic difference between the information conveyed in multimodality and in unimodality (asymmetry in modalities), we propose a novel cross-modality contrastive loss to learn the unique knowledge that only appears in multimodality. This is critical as some harmful intent may only be conveyed through the intersection of both modalities. With extensive experiments, we show that AM3 outperforms all existing state-of-the-art methods on both multimodal and unimodal CM benchmarks.
Contextual Bandit Applications in Customer Support Bot
Dec 06, 2021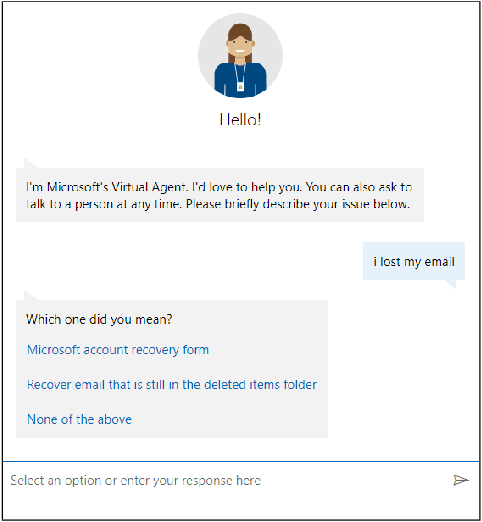
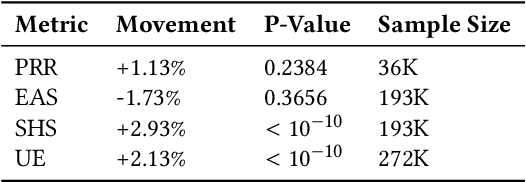
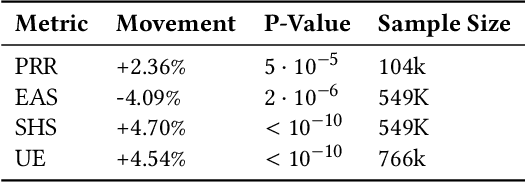
Virtual support agents have grown in popularity as a way for businesses to provide better and more accessible customer service. Some challenges in this domain include ambiguous user queries as well as changing support topics and user behavior (non-stationarity). We do, however, have access to partial feedback provided by the user (clicks, surveys, and other events) which can be leveraged to improve the user experience. Adaptable learning techniques, like contextual bandits, are a natural fit for this problem setting. In this paper, we discuss real-world implementations of contextual bandits (CB) for the Microsoft virtual agent. It includes intent disambiguation based on neural-linear bandits (NLB) and contextual recommendations based on a collection of multi-armed bandits (MAB). Our solutions have been deployed to production and have improved key business metrics of the Microsoft virtual agent, as confirmed by A/B experiments. Results include a relative increase of over 12% in problem resolution rate and relative decrease of over 4% in escalations to a human operator. While our current use cases focus on intent disambiguation and contextual recommendation for support bots, we believe our methods can be extended to other domains.
* in KDD 2021
CoDA: Contrast-enhanced and Diversity-promoting Data Augmentation for Natural Language Understanding
Oct 16, 2020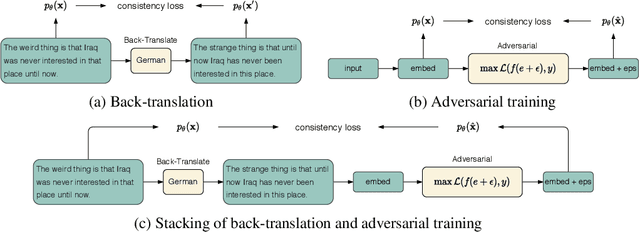
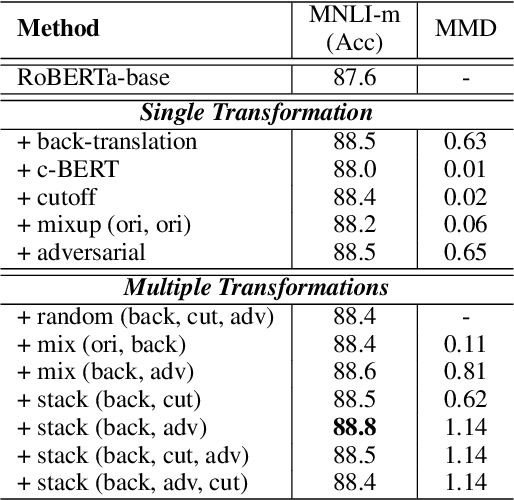

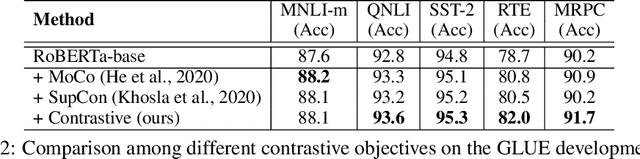
Data augmentation has been demonstrated as an effective strategy for improving model generalization and data efficiency. However, due to the discrete nature of natural language, designing label-preserving transformations for text data tends to be more challenging. In this paper, we propose a novel data augmentation framework dubbed CoDA, which synthesizes diverse and informative augmented examples by integrating multiple transformations organically. Moreover, a contrastive regularization objective is introduced to capture the global relationship among all the data samples. A momentum encoder along with a memory bank is further leveraged to better estimate the contrastive loss. To verify the effectiveness of the proposed framework, we apply CoDA to Transformer-based models on a wide range of natural language understanding tasks. On the GLUE benchmark, CoDA gives rise to an average improvement of 2.2% while applied to the RoBERTa-large model. More importantly, it consistently exhibits stronger results relative to several competitive data augmentation and adversarial training base-lines (including the low-resource settings). Extensive experiments show that the proposed contrastive objective can be flexibly combined with various data augmentation approaches to further boost their performance, highlighting the wide applicability of the CoDA framework.
xBD: A Dataset for Assessing Building Damage from Satellite Imagery
Nov 21, 2019
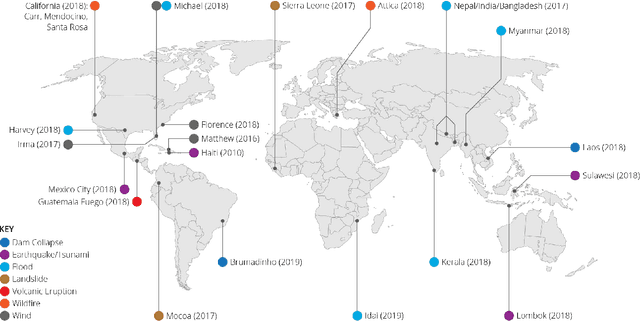
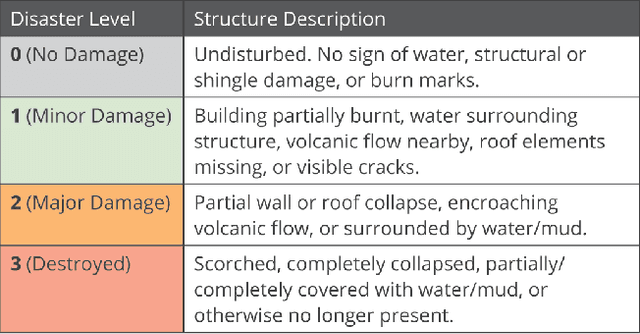

We present xBD, a new, large-scale dataset for the advancement of change detection and building damage assessment for humanitarian assistance and disaster recovery research. Natural disaster response requires an accurate understanding of damaged buildings in an affected region. Current response strategies require in-person damage assessments within 24-48 hours of a disaster. Massive potential exists for using aerial imagery combined with computer vision algorithms to assess damage and reduce the potential danger to human life. In collaboration with multiple disaster response agencies, xBD provides pre- and post-event satellite imagery across a variety of disaster events with building polygons, ordinal labels of damage level, and corresponding satellite metadata. Furthermore, the dataset contains bounding boxes and labels for environmental factors such as fire, water, and smoke. xBD is the largest building damage assessment dataset to date, containing 850,736 building annotations across 45,362 km\textsuperscript{2} of imagery.