 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Sight, Still in Mind: Reasoning and Planning about Unobserved Objects with Video Tracking Enabled Memory Models
Sep 26, 2023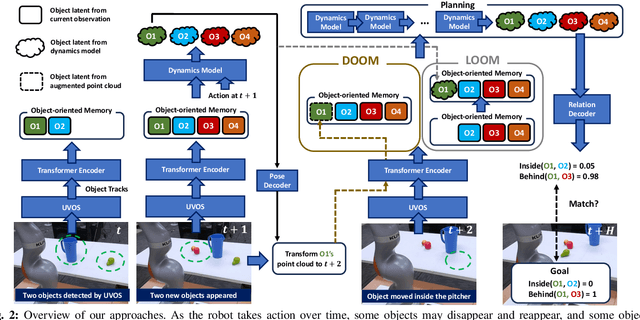
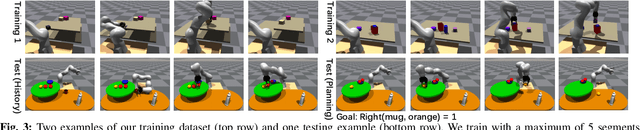
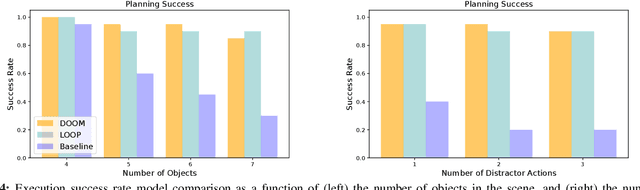
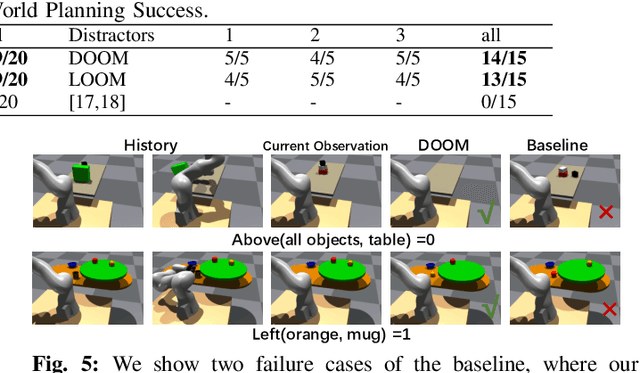
Robots need to have a memory of previously observed, but currently occluded objects to work reliably in realistic environments. We investigate the problem of encoding object-oriented memory into a multi-object manipulation reasoning and planning framework. We propose DOOM and LOOM, which leverage transformer relational dynamics to encode the history of trajectories given partial-view point clouds and an object discovery and tracking engine. Our approaches can perform multiple challenging tasks including reasoning with occluded objects, novel objects appearance, and object reappearance. Throughout our extensive simulation and real-world experiments, we find that our approaches perform well in terms of different numbers of objects and different numbers of distractor actions. Furthermore, we show our approaches outperform an implicit memory baseline.
Rethinking Multimodal Content Moderation from an Asymmetric Angle with Mixed-modality
May 17, 2023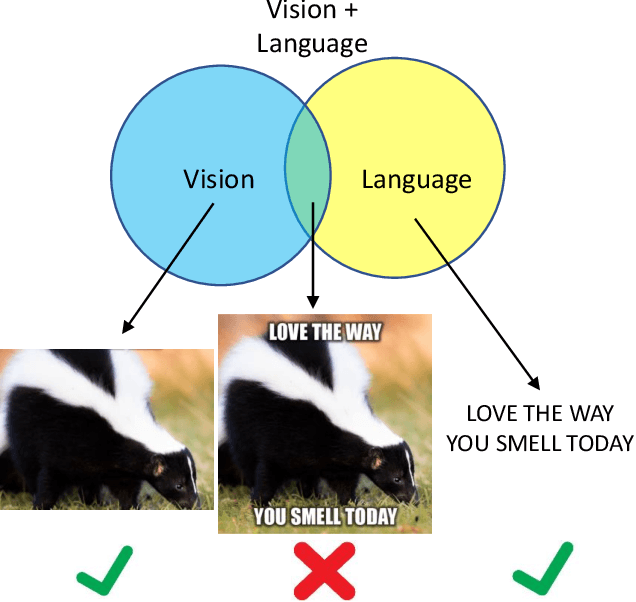
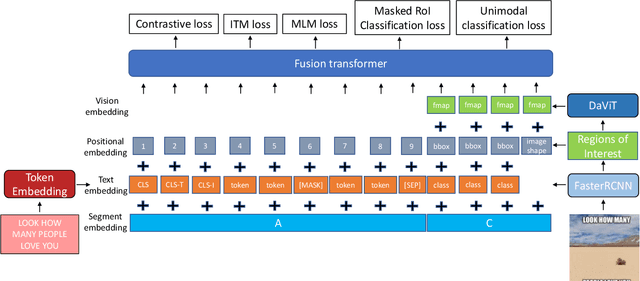
There is a rapidly growing need for multimodal content moderation (CM) as more and more content on social media is multimodal in nature. Existing unimodal CM systems may fail to catch harmful content that crosses modalities (e.g., memes or videos), which may lead to severe consequences. In this paper, we present a novel CM model, Asymmetric Mixed-Modal Moderation (AM3), to target multimodal and unimodal CM tasks. Specifically, to address the asymmetry in semantics between vision and language, AM3 has a novel asymmetric fusion architecture that is designed to not only fuse the common knowledge in both modalities but also to exploit the unique information in each modality. Unlike previous works that focus on fusing the two modalities while overlooking the intrinsic difference between the information conveyed in multimodality and in unimodality (asymmetry in modalities), we propose a novel cross-modality contrastive loss to learn the unique knowledge that only appears in multimodality. This is critical as some harmful intent may only be conveyed through the intersection of both modalities. With extensive experiments, we show that AM3 outperforms all existing state-of-the-art methods on both multimodal and unimodal CM benchmarks.
Maximal Cliques on Multi-Frame Proposal Graph for Unsupervised Video Object Segmentation
Jan 29, 2023
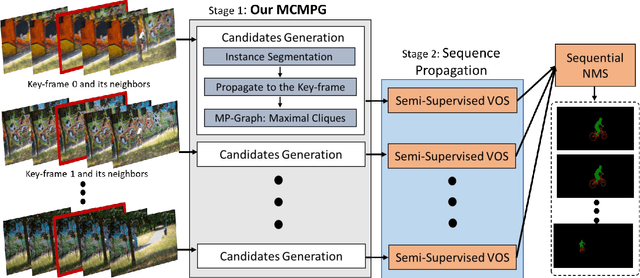
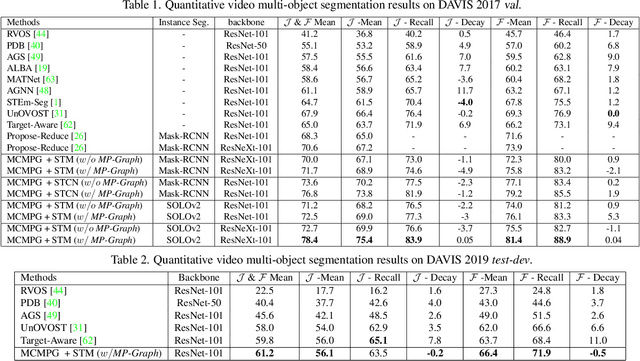
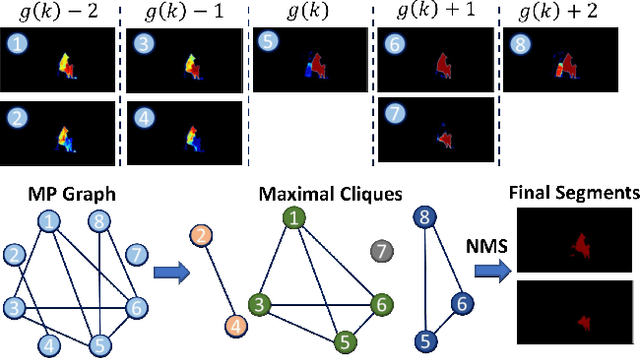
Unsupervised Video Object Segmentation (UVOS) aims at discovering objects and tracking them through videos. For accurate UVOS, we observe if one can locate precise segment proposals on key frames, subsequent processes are much simpler. Hence, we propose to reason about key frame proposals using a graph built with the object probability masks initially generated from multiple frames around the key frame and then propagated to the key frame. On this graph, we compute maximal cliques, with each clique representing one candidate object. By making multiple proposals in the clique to vote for the key frame proposal, we obtain refined key frame proposals that could be better than any of the single-frame proposals. A semi-supervised VOS algorithm subsequently tracks these key frame proposals to the entire video. Our algorithm is modular and hence can be used with any instance segmentation and semi-supervised VOS algorithm. We achieve state-of-the-art performance on the DAVIS-2017 validation and test-dev dataset. On the related problem of video instance segmentation, our method shows competitive performance with the previous best algorithm that requires joint training with the VOS algorithm.
BATMAN: Bilateral Attention Transformer in Motion-Appearance Neighboring Space for Video Object Segmentation
Aug 08, 2022
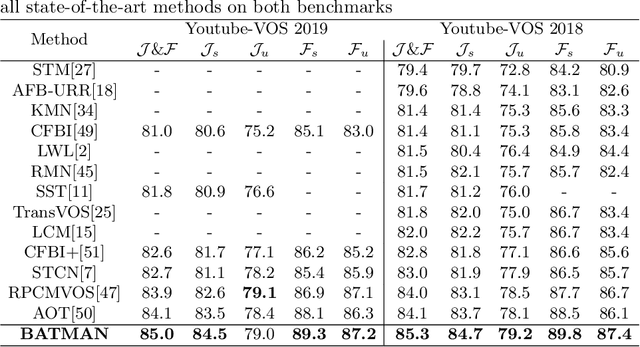
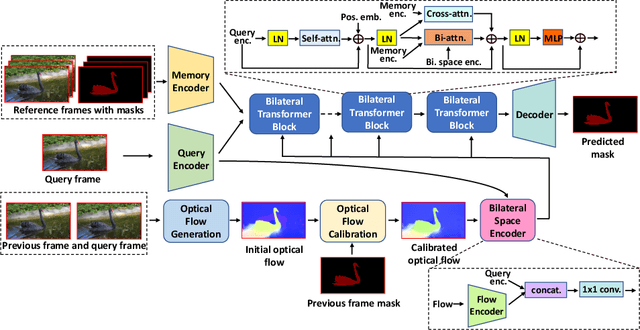
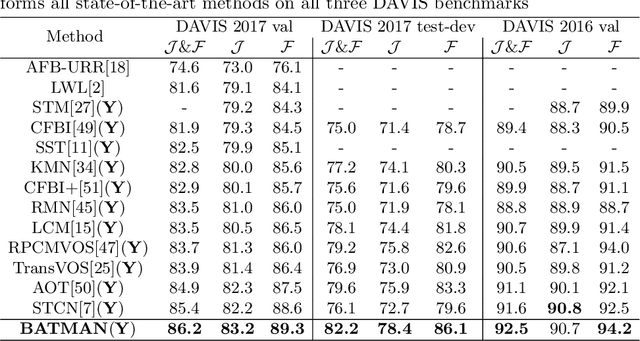
Video Object Segmentation (VOS) is fundamental to video understanding. Transformer-based methods show significant performance improvement on semi-supervised VOS. However, existing work faces challenges segmenting visually similar objects in close proximity of each other. In this paper, we propose a novel Bilateral Attention Transformer in Motion-Appearance Neighboring space (BATMAN) for semi-supervised VOS. It captures object motion in the video via a novel optical flow calibration module that fuses the segmentation mask with optical flow estimation to improve within-object optical flow smoothness and reduce noise at object boundaries. This calibrated optical flow is then employed in our novel bilateral attention, which computes the correspondence between the query and reference frames in the neighboring bilateral space considering both motion and appearance. Extensive experiments validate the effectiveness of BATMAN architecture by outperforming all existing state-of-the-art on all four popular VOS benchmarks: Youtube-VOS 2019 (85.0%), Youtube-VOS 2018 (85.3%), DAVIS 2017Val/Testdev (86.2%/82.2%), and DAVIS 2016 (92.5%).
Deep Variational Instance Segmentation
Jul 22, 2020
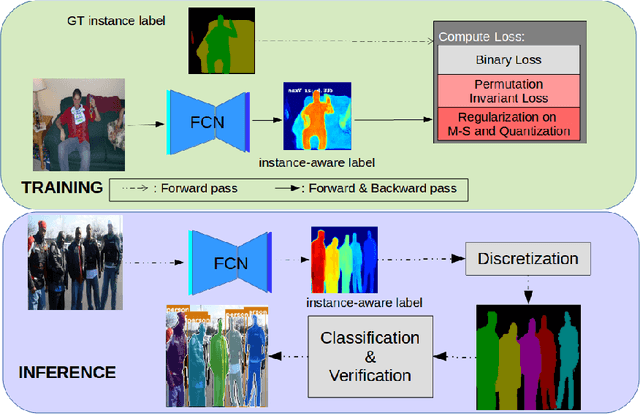
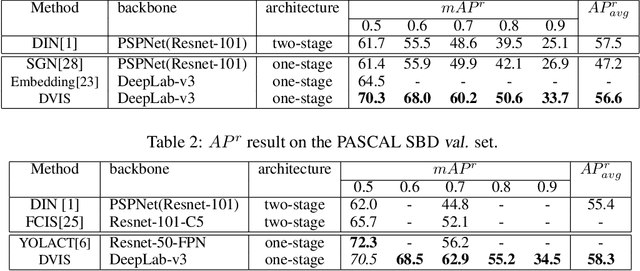
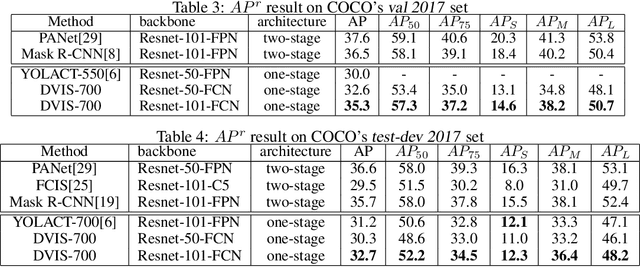
Instance Segmentation, which seeks to obtain both class and instance labels for each pixel in the input image, is a challenging task in computer vision. State-of-the-art algorithms often employ two separate stages, the first one generating object proposals and the second one recognizing and refining the boundaries. Further, proposals are usually based on detectors such as faster R-CNN which search for boxes in the entire image exhaustively. In this paper, we propose a novel algorithm that directly utilizes a fully convolutional network (FCN) to predict instance labels. Specifically, we propose a variational relaxation of instance segmentation as minimizing an optimization functional for a piecewise-constant segmentation problem, which can be used to train an FCN end-to-end. It extends the classical Mumford-Shah variational segmentation problem to be able to handle permutation-invariant labels in the ground truth of instance segmentation. Experiments on PASCAL VOC 2012, Semantic Boundaries dataset(SBD), and the MSCOCO 2017 dataset show that the proposed approach efficiently tackle the instance segmentation task. The source code and trained models will be released with the paper.