 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning Neural Dynamics with Lie Group Embedding through Supervised Projective Manifold Learning
May 24, 2026We propose Lie group embedded dynamical neural networks (LieEDNN) and the corresponding learning algorithms based on gradient descent and metric projection on smooth manifold, where we treat Lie group as an intrinsic representation for continuous symmetry of manifold geometry. Thereby we achieve learnable and stable dynamics on the underlying manifold for general Lie group, and we are able to utilize the powerful representation capability of Lie group such as SO(3) and SE(3) to solve real world engineering problems in areas such as robotics, graphics, and control. Two core challenges are: (i) General Lie groups are incompatible with addition arithmetic, which is necessary for neural network interactions. (ii) The dynamics evolve in the nonlinear representation space of special algebra rather than the normal Euclidean space, which violates the paradigm of common neural ODEs. To address these two challenges, we firstly introduce adjoint Lie group action on the Lie algebra, which induces a linear mapping and transfer to the block-wise structure of weight matrices, such that addition could operate on the Lie algebra as a vector space. Then we parameterize the Lie algebra and the adjoint action as linear transformation so that the architecture is aligned with neural network perceptrons. Explicitly, this embedding appears as block-wise manifold constraints on weights, and we develop algorithms to learn the equilibrium with stability guarantees of the temporal neural network dynamics. Experiments are implemented on a specific Lie group SE(3), with the application scenario of telescopic manipulators.
Out of Sight, Still in Mind: Reasoning and Planning about Unobserved Objects with Video Tracking Enabled Memory Models
Sep 26, 2023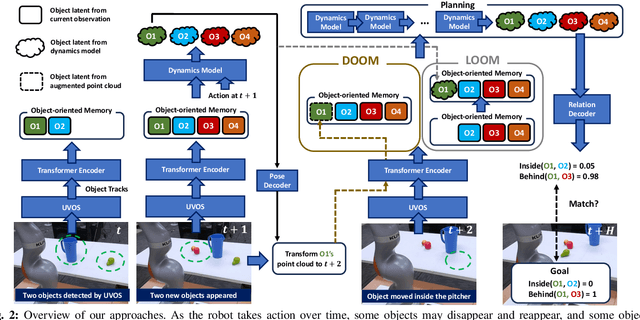
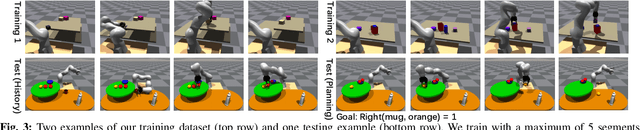
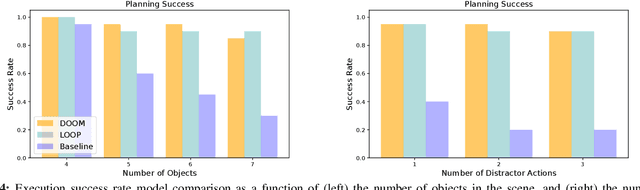
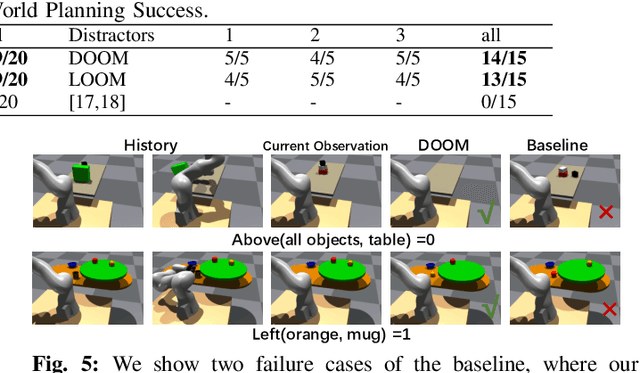
Robots need to have a memory of previously observed, but currently occluded objects to work reliably in realistic environments. We investigate the problem of encoding object-oriented memory into a multi-object manipulation reasoning and planning framework. We propose DOOM and LOOM, which leverage transformer relational dynamics to encode the history of trajectories given partial-view point clouds and an object discovery and tracking engine. Our approaches can perform multiple challenging tasks including reasoning with occluded objects, novel objects appearance, and object reappearance. Throughout our extensive simulation and real-world experiments, we find that our approaches perform well in terms of different numbers of objects and different numbers of distractor actions. Furthermore, we show our approaches outperform an implicit memory baseline.
Towards Trainable Saliency Maps in Medical Imaging
Nov 15, 2020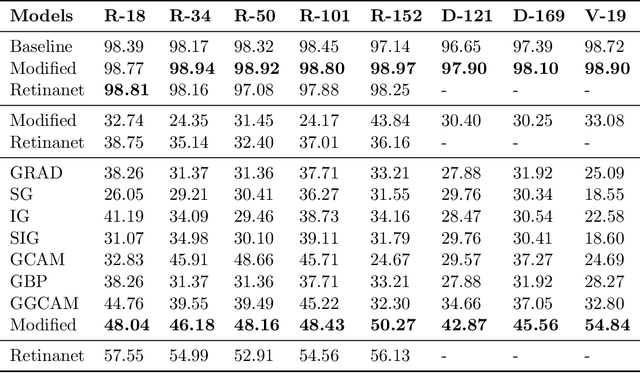
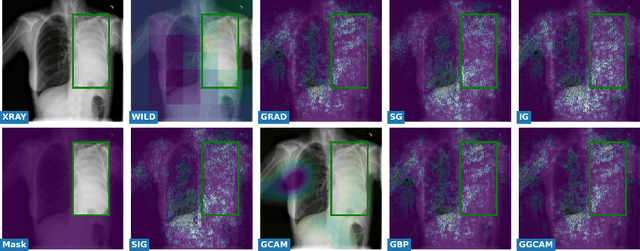
While success of Deep Learning (DL) in automated diagnosis can be transformative to the medicinal practice especially for people with little or no access to doctors, its widespread acceptability is severely limited by inherent black-box decision making and unsafe failure modes. While saliency methods attempt to tackle this problem in non-medical contexts, their apriori explanations do not transfer well to medical usecases. With this study we validate a model design element agnostic to both architecture complexity and model task, and show how introducing this element gives an inherently self-explanatory model. We compare our results with state of the art non-trainable saliency maps on RSNA Pneumonia Dataset and demonstrate a much higher localization efficacy using our adopted technique. We also compare, with a fully supervised baseline and provide a reasonable alternative to it's high data labelling overhead. We further investigate the validity of our claims through qualitative evaluation from an expert reader.
Robust Policies via Mid-Level Visual Representations: An Experimental Study in Manipulation and Navigation
Nov 13, 2020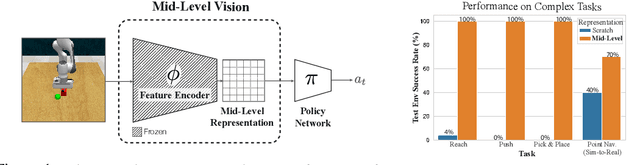
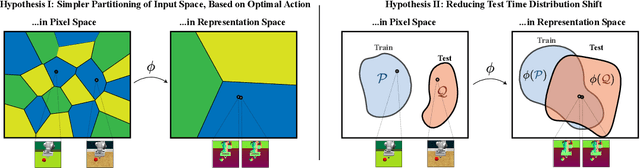
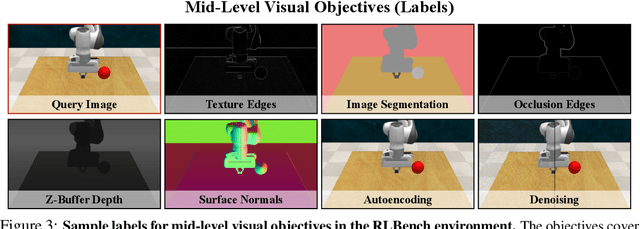
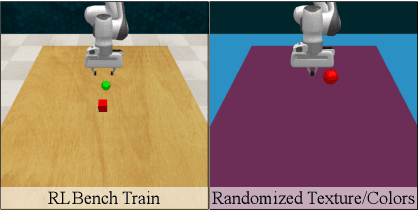
Vision-based robotics often separates the control loop into one module for perception and a separate module for control. It is possible to train the whole system end-to-end (e.g. with deep RL), but doing it "from scratch" comes with a high sample complexity cost and the final result is often brittle, failing unexpectedly if the test environment differs from that of training. We study the effects of using mid-level visual representations (features learned asynchronously for traditional computer vision objectives), as a generic and easy-to-decode perceptual state in an end-to-end RL framework. Mid-level representations encode invariances about the world, and we show that they aid generalization, improve sample complexity, and lead to a higher final performance. Compared to other approaches for incorporating invariances, such as domain randomization, asynchronously trained mid-level representations scale better: both to harder problems and to larger domain shifts. In practice, this means that mid-level representations could be used to successfully train policies for tasks where domain randomization and learning-from-scratch failed. We report results on both manipulation and navigation tasks, and for navigation include zero-shot sim-to-real experiments on real robots.
Federated Learning for Breast Density Classification: A Real-World Implementation
Sep 17, 2020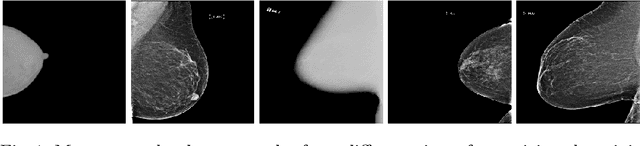

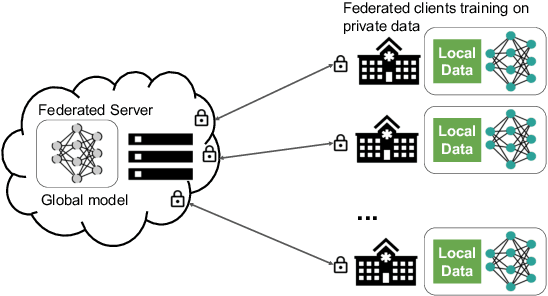
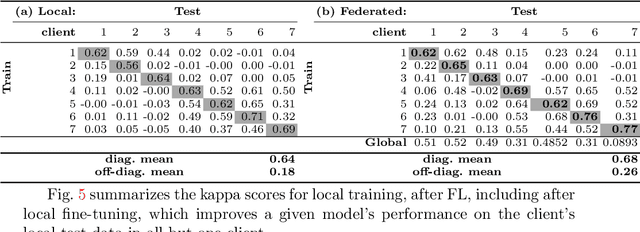
Building robust deep learning-based models requires large quantities of diverse training data. In this study, we investigate the use of federated learning (FL) to build medical imaging classification models in a real-world collaborative setting. Seven clinical institutions from across the world joined this FL effort to train a model for breast density classification based on Breast Imaging, Reporting & Data System (BI-RADS). We show that despite substantial differences among the datasets from all sites (mammography system, class distribution, and data set size) and without centralizing data, we can successfully train AI models in federation. The results show that models trained using FL perform 6.3% on average better than their counterparts trained on an institute's local data alone. Furthermore, we show a 45.8% relative improvement in the models' generalizability when evaluated on the other participating sites' testing data.
Assessing the (Un)Trustworthiness of Saliency Maps for Localizing Abnormalities in Medical Imaging
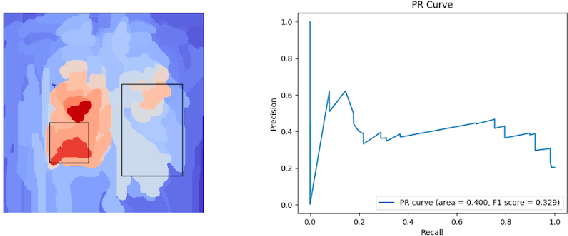
Aug 06, 2020Saliency maps have become a widely used method to make deep learning models more interpretable by providing post-hoc explanations of classifiers through identification of the most pertinent areas of the input medical image. They are increasingly being used in medical imaging to provide clinically plausible explanations for the decisions the neural network makes. However, the utility and robustness of these visualization maps has not yet been rigorously examined in the context of medical imaging. We posit that trustworthiness in this context requires 1) localization utility, 2) sensitivity to model weight randomization, 3) repeatability, and 4) reproducibility. Using the localization information available in two large public radiology datasets, we quantify the performance of eight commonly used saliency map approaches for the above criteria using area under the precision-recall curves (AUPRC) and structural similarity index (SSIM), comparing their performance to various baseline measures. Using our framework to quantify the trustworthiness of saliency maps, we show that all eight saliency map techniques fail at least one of the criteria and are, in most cases, less trustworthy when compared to the baselines. We suggest that their usage in the high-risk domain of medical imaging warrants additional scrutiny and recommend that detection or segmentation models be used if localization is the desired output of the network. Additionally, to promote reproducibility of our findings, we provide the code we used for all tests performed in this work at this link: https://github.com/QTIM-Lab/Assessing-Saliency-Maps.