 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Multi-sensor Conditioning for Street-view Novel-view Synthesis
Jun 01, 2026Modern vehicle platforms are equipped with a rich sensor suite, including LiDAR, calibrated multi-camera rigs, and accurate ego-motion, that in principle offers strong signal for re-rendering a driving scene from novel viewpoints. A growing line of recent work leverages video diffusion models for this task, using their generative priors to synthesize plausible novel views from sparse vehicle observations. In practice, however, existing methods exploit only a fragment of this signal, and their quality tends to degrade as the target trajectory departs from the recorded driving path. We argue that this is fundamentally a multi-sensor fusion problem: sparse LiDAR reprojections supply accurate but incomplete metric geometry, surround-view reference imagery supplies dense appearance but no metric depth, and camera poses tie the two together across views. We introduce StreetNVS, a video diffusion framework that jointly conditions on all three signals through a Reference-Enhanced Camera Attention module based on a relative ray-level positional encoding. We develop a two-stage curriculum training strategy that gradually exposes the model to increasingly sparse LiDAR. On the Waymo Open Dataset, StreetNVS substantially outperforms state-of-the-art baselines under sparse LiDAR conditioning, matches methods that rely on 10-100 times denser point clouds. We further show capabilities of synthesizing coherent videos along extreme out-of-trajectory paths such as elevation, lane-shift, pullback, and rotation. Our website: https://streetnvs.github.io
WildPose: A Unified Framework for Robust Pose Estimation in the Wild
May 12, 2026Estimating camera pose in dynamic environments is a critical challenge, as most visual SLAM and SfM methods assume static scenes. While recent dynamic-aware methods exist, they are often not unified: semantic-based approaches are brittle, per-sequence optimization methods fail on short sequences, and other learned models may degrade on static-only scenes. We present WildPose, a unified monocular pose estimation framework that is robust in dynamic environments while maintaining state-of-the-art performance on static and low-ego-motion datasets. Our key insight is to connect two powerful paradigms in modern 3D vision: the rich perceptual frontend of feedforward models and the end-to-end optimization of differentiable bundle adjustment (BA). We achieve this with a 3D-aware update operator built on a frozen, pre-trained MASt3R feature backbone, together with a high-capacity motion mask detector that uses multi-level 3D-aware features from the same backbone. Extensive experiments show WildPose consistently outperforms prior methods across dynamic (Wild-SLAM, Bonn), static (TUM, 7-Scenes), and low-ego-motion (Sintel) benchmarks.
GaussFusion: Improving 3D Reconstruction in the Wild with A Geometry-Informed Video Generator
Mar 26, 2026We present GaussFusion, a novel approach for improving 3D Gaussian splatting (3DGS) reconstructions in the wild through geometry-informed video generation. GaussFusion mitigates common 3DGS artifacts, including floaters, flickering, and blur caused by camera pose errors, incomplete coverage, and noisy geometry initialization. Unlike prior RGB-based approaches limited to a single reconstruction pipeline, our method introduces a geometry-informed video-to-video generator that refines 3DGS renderings across both optimization-based and feed-forward methods. Given an existing reconstruction, we render a Gaussian primitive video buffer encoding depth, normals, opacity, and covariance, which the generator refines to produce temporally coherent, artifact-free frames. We further introduce an artifact synthesis pipeline that simulates diverse degradation patterns, ensuring robustness and generalization. GaussFusion achieves state-of-the-art performance on novel-view synthesis benchmarks, and an efficient variant runs in real time at 21 FPS while maintaining similar performance, enabling interactive 3D applications.
CoPE-VideoLM: Codec Primitives For Efficient Video Language Models
Feb 13, 2026Video Language Models (VideoLMs) empower AI systems to understand temporal dynamics in videos. To fit to the maximum context window constraint, current methods use keyframe sampling which can miss both macro-level events and micro-level details due to the sparse temporal coverage. Furthermore, processing full images and their tokens for each frame incurs substantial computational overhead. To address these limitations, we propose to leverage video codec primitives (specifically motion vectors and residuals) which natively encode video redundancy and sparsity without requiring expensive full-image encoding for most frames. To this end, we introduce lightweight transformer-based encoders that aggregate codec primitives and align their representations with image encoder embeddings through a pre-training strategy that accelerates convergence during end-to-end fine-tuning. Our approach reduces the time-to-first-token by up to $86\%$ and token usage by up to $93\%$ compared to standard VideoLMs. Moreover, by varying the keyframe and codec primitive densities we are able to maintain or exceed performance on $14$ diverse video understanding benchmarks spanning general question answering, temporal reasoning, long-form understanding, and spatial scene understanding.
ReScene4D: Temporally Consistent Semantic Instance Segmentation of Evolving Indoor 3D Scenes
Jan 16, 2026Indoor environments evolve as objects move, appear, or disappear. Capturing these dynamics requires maintaining temporally consistent instance identities across intermittently captured 3D scans, even when changes are unobserved. We introduce and formalize the task of temporally sparse 4D indoor semantic instance segmentation (SIS), which jointly segments, identifies, and temporally associates object instances. This setting poses a challenge for existing 3DSIS methods, which require a discrete matching step due to their lack of temporal reasoning, and for 4D LiDAR approaches, which perform poorly due to their reliance on high-frequency temporal measurements that are uncommon in the longer-horizon evolution of indoor environments. We propose ReScene4D, a novel method that adapts 3DSIS architectures for 4DSIS without needing dense observations. It explores strategies to share information across observations, demonstrating that this shared context not only enables consistent instance tracking but also improves standard 3DSIS quality. To evaluate this task, we define a new metric, t-mAP, that extends mAP to reward temporal identity consistency. ReScene4D achieves state-of-the-art performance on the 3RScan dataset, establishing a new benchmark for understanding evolving indoor scenes.
Rectified Point Flow: Generic Point Cloud Pose Estimation
Jun 05, 2025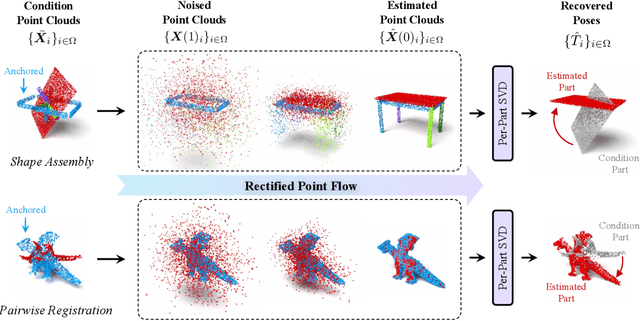
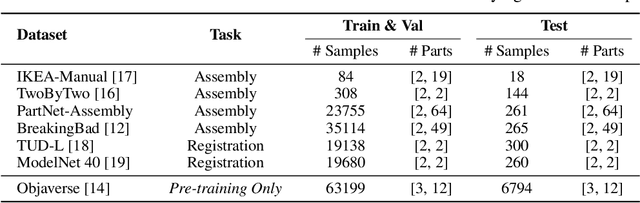
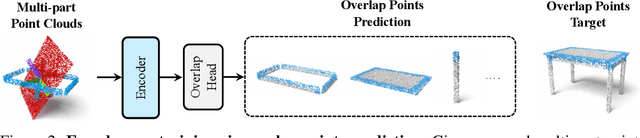
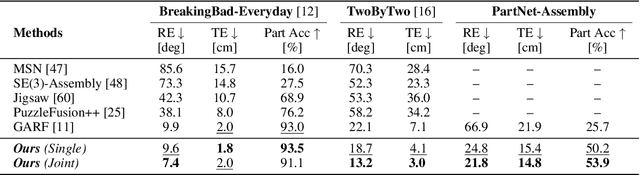
We introduce Rectified Point Flow, a unified parameterization that formulates pairwise point cloud registration and multi-part shape assembly as a single conditional generative problem. Given unposed point clouds, our method learns a continuous point-wise velocity field that transports noisy points toward their target positions, from which part poses are recovered. In contrast to prior work that regresses part-wise poses with ad-hoc symmetry handling, our method intrinsically learns assembly symmetries without symmetry labels. Together with a self-supervised encoder focused on overlapping points, our method achieves a new state-of-the-art performance on six benchmarks spanning pairwise registration and shape assembly. Notably, our unified formulation enables effective joint training on diverse datasets, facilitating the learning of shared geometric priors and consequently boosting accuracy. Project page: https://rectified-pointflow.github.io/.
WildGS-SLAM: Monocular Gaussian Splatting SLAM in Dynamic Environments
Apr 04, 2025We present WildGS-SLAM, a robust and efficient monocular RGB SLAM system designed to handle dynamic environments by leveraging uncertainty-aware geometric mapping. Unlike traditional SLAM systems, which assume static scenes, our approach integrates depth and uncertainty information to enhance tracking, mapping, and rendering performance in the presence of moving objects. We introduce an uncertainty map, predicted by a shallow multi-layer perceptron and DINOv2 features, to guide dynamic object removal during both tracking and mapping. This uncertainty map enhances dense bundle adjustment and Gaussian map optimization, improving reconstruction accuracy. Our system is evaluated on multiple datasets and demonstrates artifact-free view synthesis. Results showcase WildGS-SLAM's superior performance in dynamic environments compared to state-of-the-art methods.
CrossOver: 3D Scene Cross-Modal Alignment
Feb 20, 2025


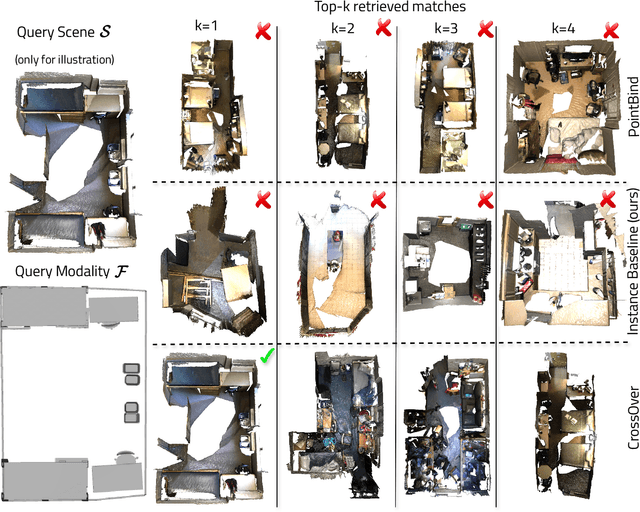
Multi-modal 3D object understanding has gained significant attention, yet current approaches often assume complete data availability and rigid alignment across all modalities. We present CrossOver, a novel framework for cross-modal 3D scene understanding via flexible, scene-level modality alignment. Unlike traditional methods that require aligned modality data for every object instance, CrossOver learns a unified, modality-agnostic embedding space for scenes by aligning modalities - RGB images, point clouds, CAD models, floorplans, and text descriptions - with relaxed constraints and without explicit object semantics. Leveraging dimensionality-specific encoders, a multi-stage training pipeline, and emergent cross-modal behaviors, CrossOver supports robust scene retrieval and object localization, even with missing modalities. Evaluations on ScanNet and 3RScan datasets show its superior performance across diverse metrics, highlighting adaptability for real-world applications in 3D scene understanding.
LoopSplat: Loop Closure by Registering 3D Gaussian Splats
Aug 20, 2024



Simultaneous Localization and Mapping (SLAM) based on 3D Gaussian Splats (3DGS) has recently shown promise towards more accurate, dense 3D scene maps. However, existing 3DGS-based methods fail to address the global consistency of the scene via loop closure and/or global bundle adjustment. To this end, we propose LoopSplat, which takes RGB-D images as input and performs dense mapping with 3DGS submaps and frame-to-model tracking. LoopSplat triggers loop closure online and computes relative loop edge constraints between submaps directly via 3DGS registration, leading to improvements in efficiency and accuracy over traditional global-to-local point cloud registration. It uses a robust pose graph optimization formulation and rigidly aligns the submaps to achieve global consistency. Evaluation on the synthetic Replica and real-world TUM-RGBD, ScanNet, and ScanNet++ datasets demonstrates competitive or superior tracking, mapping, and rendering compared to existing methods for dense RGB-D SLAM. Code is available at loopsplat.github.io.
MAP-ADAPT: Real-Time Quality-Adaptive Semantic 3D Maps
Jun 09, 2024



Creating 3D semantic reconstructions of environments is fundamental to many applications, especially when related to autonomous agent operation (e.g., goal-oriented navigation or object interaction and manipulation). Commonly, 3D semantic reconstruction systems capture the entire scene in the same level of detail. However, certain tasks (e.g., object interaction) require a fine-grained and high-resolution map, particularly if the objects to interact are of small size or intricate geometry. In recent practice, this leads to the entire map being in the same high-quality resolution, which results in increased computational and storage costs. To address this challenge, we propose MAP-ADAPT, a real-time method for quality-adaptive semantic 3D reconstruction using RGBD frames. MAP-ADAPT is the first adaptive semantic 3D mapping algorithm that, unlike prior work, generates directly a single map with regions of different quality based on both the semantic information and the geometric complexity of the scene. Leveraging a semantic SLAM pipeline for pose and semantic estimation, we achieve comparable or superior results to state-of-the-art methods on synthetic and real-world data, while significantly reducing storage and computation requirements.