 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReScene4D: Temporally Consistent Semantic Instance Segmentation of Evolving Indoor 3D Scenes
Jan 16, 2026Indoor environments evolve as objects move, appear, or disappear. Capturing these dynamics requires maintaining temporally consistent instance identities across intermittently captured 3D scans, even when changes are unobserved. We introduce and formalize the task of temporally sparse 4D indoor semantic instance segmentation (SIS), which jointly segments, identifies, and temporally associates object instances. This setting poses a challenge for existing 3DSIS methods, which require a discrete matching step due to their lack of temporal reasoning, and for 4D LiDAR approaches, which perform poorly due to their reliance on high-frequency temporal measurements that are uncommon in the longer-horizon evolution of indoor environments. We propose ReScene4D, a novel method that adapts 3DSIS architectures for 4DSIS without needing dense observations. It explores strategies to share information across observations, demonstrating that this shared context not only enables consistent instance tracking but also improves standard 3DSIS quality. To evaluate this task, we define a new metric, t-mAP, that extends mAP to reward temporal identity consistency. ReScene4D achieves state-of-the-art performance on the 3RScan dataset, establishing a new benchmark for understanding evolving indoor scenes.
WildGS-SLAM: Monocular Gaussian Splatting SLAM in Dynamic Environments
Apr 04, 2025We present WildGS-SLAM, a robust and efficient monocular RGB SLAM system designed to handle dynamic environments by leveraging uncertainty-aware geometric mapping. Unlike traditional SLAM systems, which assume static scenes, our approach integrates depth and uncertainty information to enhance tracking, mapping, and rendering performance in the presence of moving objects. We introduce an uncertainty map, predicted by a shallow multi-layer perceptron and DINOv2 features, to guide dynamic object removal during both tracking and mapping. This uncertainty map enhances dense bundle adjustment and Gaussian map optimization, improving reconstruction accuracy. Our system is evaluated on multiple datasets and demonstrates artifact-free view synthesis. Results showcase WildGS-SLAM's superior performance in dynamic environments compared to state-of-the-art methods.
MAP-ADAPT: Real-Time Quality-Adaptive Semantic 3D Maps
Jun 09, 2024



Creating 3D semantic reconstructions of environments is fundamental to many applications, especially when related to autonomous agent operation (e.g., goal-oriented navigation or object interaction and manipulation). Commonly, 3D semantic reconstruction systems capture the entire scene in the same level of detail. However, certain tasks (e.g., object interaction) require a fine-grained and high-resolution map, particularly if the objects to interact are of small size or intricate geometry. In recent practice, this leads to the entire map being in the same high-quality resolution, which results in increased computational and storage costs. To address this challenge, we propose MAP-ADAPT, a real-time method for quality-adaptive semantic 3D reconstruction using RGBD frames. MAP-ADAPT is the first adaptive semantic 3D mapping algorithm that, unlike prior work, generates directly a single map with regions of different quality based on both the semantic information and the geometric complexity of the scene. Leveraging a semantic SLAM pipeline for pose and semantic estimation, we achieve comparable or superior results to state-of-the-art methods on synthetic and real-world data, while significantly reducing storage and computation requirements.
TEAM: a parameter-free algorithm to teach collaborative robots motions from user demonstrations
Sep 14, 2022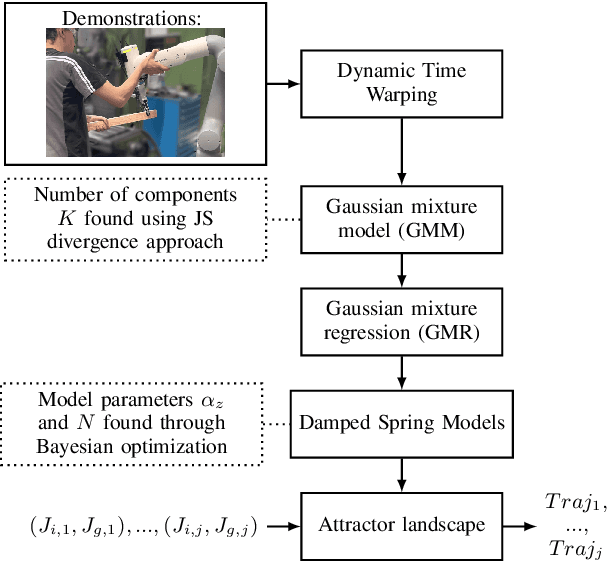
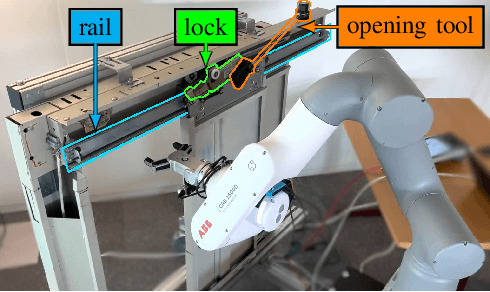
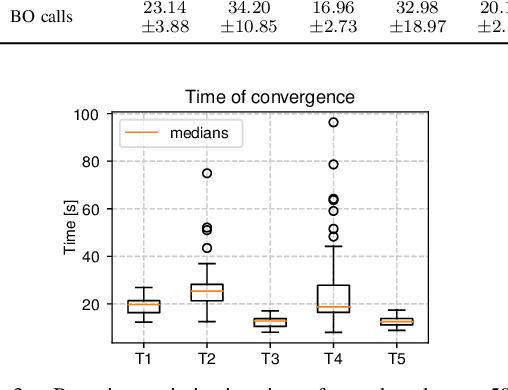

Collaborative robots (cobots) built to work alongside humans must be able to quickly learn new skills and adapt to new task configurations. Learning from demonstration (LfD) enables cobots to learn and adapt motions to different use conditions. However, state-of-the-art LfD methods require manually tuning intrinsic parameters and have rarely been used in industrial contexts without experts. In this paper, the development and implementation of a LfD framework for industrial applications with naive users is presented. We propose a parameter-free method based on probabilistic movement primitives, where all the parameters are pre-determined using Jensen-Shannon divergence and bayesian optimization; thus, users do not have to perform manual parameter tuning. This method learns motions from a small dataset of user demonstrations, and generalizes the motion to various scenarios and conditions. We evaluate the method extensively in two field tests: one where the cobot works on elevator door maintenance, and one where three Schindler workers teach the cobot tasks useful for their workflow. Errors between the cobot end-effector and target positions range from $0$ to $1.48\pm0.35$mm. For all tests, no task failures were reported. Questionnaires completed by the Schindler workers highlighted the method's ease of use, feeling of safety, and the accuracy of the reproduced motion. Our code and recorded trajectories are made available online for reproduction.
CrossLoc: Scalable Aerial Localization Assisted by Multimodal Synthetic Data
Dec 16, 2021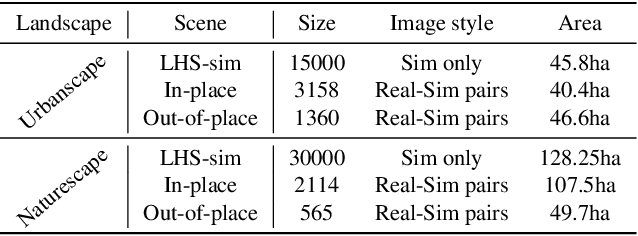

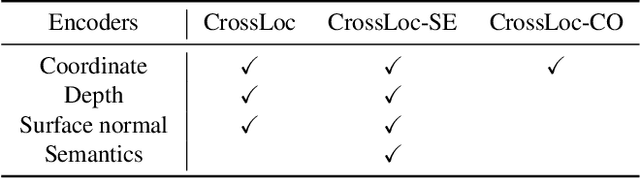
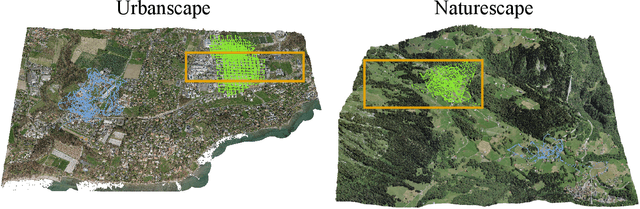
We present a visual localization system that learns to estimate camera poses in the real world with the help of synthetic data. Despite significant progress in recent years, most learning-based approaches to visual localization target at a single domain and require a dense database of geo-tagged images to function well. To mitigate the data scarcity issue and improve the scalability of the neural localization models, we introduce TOPO-DataGen, a versatile synthetic data generation tool that traverses smoothly between the real and virtual world, hinged on the geographic camera viewpoint. New large-scale sim-to-real benchmark datasets are proposed to showcase and evaluate the utility of the said synthetic data. Our experiments reveal that synthetic data generically enhances the neural network performance on real data. Furthermore, we introduce CrossLoc, a cross-modal visual representation learning approach to pose estimation that makes full use of the scene coordinate ground truth via self-supervision. Without any extra data, CrossLoc significantly outperforms the state-of-the-art methods and achieves substantially higher real-data sample efficiency. Our code is available at https://github.com/TOPO-EPFL/CrossLoc.