 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale visual SLAM for in-the-wild videos
Apr 29, 2025Accurate and robust 3D scene reconstruction from casual, in-the-wild videos can significantly simplify robot deployment to new environments. However, reliable camera pose estimation and scene reconstruction from such unconstrained videos remains an open challenge. Existing visual-only SLAM methods perform well on benchmark datasets but struggle with real-world footage which often exhibits uncontrolled motion including rapid rotations and pure forward movements, textureless regions, and dynamic objects. We analyze the limitations of current methods and introduce a robust pipeline designed to improve 3D reconstruction from casual videos. We build upon recent deep visual odometry methods but increase robustness in several ways. Camera intrinsics are automatically recovered from the first few frames using structure-from-motion. Dynamic objects and less-constrained areas are masked with a predictive model. Additionally, we leverage monocular depth estimates to regularize bundle adjustment, mitigating errors in low-parallax situations. Finally, we integrate place recognition and loop closure to reduce long-term drift and refine both intrinsics and pose estimates through global bundle adjustment. We demonstrate large-scale contiguous 3D models from several online videos in various environments. In contrast, baseline methods typically produce locally inconsistent results at several points, producing separate segments or distorted maps. In lieu of ground-truth pose data, we evaluate map consistency, execution time and visual accuracy of re-rendered NeRF models. Our proposed system establishes a new baseline for visual reconstruction from casual uncontrolled videos found online, demonstrating more consistent reconstructions over longer sequences of in-the-wild videos than previously achieved.
Thermoxels: a voxel-based method to generate simulation-ready 3D thermal models
Apr 06, 2025In the European Union, buildings account for 42% of energy use and 35% of greenhouse gas emissions. Since most existing buildings will still be in use by 2050, retrofitting is crucial for emissions reduction. However, current building assessment methods rely mainly on qualitative thermal imaging, which limits data-driven decisions for energy savings. On the other hand, quantitative assessments using finite element analysis (FEA) offer precise insights but require manual CAD design, which is tedious and error-prone. Recent advances in 3D reconstruction, such as Neural Radiance Fields (NeRF) and Gaussian Splatting, enable precise 3D modeling from sparse images but lack clearly defined volumes and the interfaces between them needed for FEA. We propose Thermoxels, a novel voxel-based method able to generate FEA-compatible models, including both geometry and temperature, from a sparse set of RGB and thermal images. Using pairs of RGB and thermal images as input, Thermoxels represents a scene's geometry as a set of voxels comprising color and temperature information. After optimization, a simple process is used to transform Thermoxels' models into tetrahedral meshes compatible with FEA. We demonstrate Thermoxels' capability to generate RGB+Thermal meshes of 3D scenes, surpassing other state-of-the-art methods. To showcase the practical applications of Thermoxels' models, we conduct a simple heat conduction simulation using FEA, achieving convergence from an initial state defined by Thermoxels' thermal reconstruction. Additionally, we compare Thermoxels' image synthesis abilities with current state-of-the-art methods, showing competitive results, and discuss the limitations of existing metrics in assessing mesh quality.
Exploiting Semantic Scene Reconstruction for Estimating Building Envelope Characteristics
Oct 29, 2024Achieving the EU's climate neutrality goal requires retrofitting existing buildings to reduce energy use and emissions. A critical step in this process is the precise assessment of geometric building envelope characteristics to inform retrofitting decisions. Previous methods for estimating building characteristics, such as window-to-wall ratio, building footprint area, and the location of architectural elements, have primarily relied on applying deep-learning-based detection or segmentation techniques on 2D images. However, these approaches tend to focus on planar facade properties, limiting their accuracy and comprehensiveness when analyzing complete building envelopes in 3D. While neural scene representations have shown exceptional performance in indoor scene reconstruction, they remain under-explored for external building envelope analysis. This work addresses this gap by leveraging cutting-edge neural surface reconstruction techniques based on signed distance function (SDF) representations for 3D building analysis. We propose BuildNet3D, a novel framework to estimate geometric building characteristics from 2D image inputs. By integrating SDF-based representation with semantic modality, BuildNet3D recovers fine-grained 3D geometry and semantics of building envelopes, which are then used to automatically extract building characteristics. Our framework is evaluated on a range of complex building structures, demonstrating high accuracy and generalizability in estimating window-to-wall ratio and building footprint. The results underscore the effectiveness of BuildNet3D for practical applications in building analysis and retrofitting.
High-Fidelity SLAM Using Gaussian Splatting with Rendering-Guided Densification and Regularized Optimization
Mar 19, 2024



We propose a dense RGBD SLAM system based on 3D Gaussian Splatting that provides metrically accurate pose tracking and visually realistic reconstruction. To this end, we first propose a Gaussian densification strategy based on the rendering loss to map unobserved areas and refine reobserved areas. Second, we introduce extra regularization parameters to alleviate the forgetting problem in the continuous mapping problem, where parameters tend to overfit the latest frame and result in decreasing rendering quality for previous frames. Both mapping and tracking are performed with Gaussian parameters by minimizing re-rendering loss in a differentiable way. Compared to recent neural and concurrently developed gaussian splatting RGBD SLAM baselines, our method achieves state-of-the-art results on the synthetic dataset Replica and competitive results on the real-world dataset TUM.
ThermoNeRF: Multimodal Neural Radiance Fields for Thermal Novel View Synthesis
Mar 18, 2024Thermal scene reconstruction exhibit great potential for applications across a broad spectrum of fields, including building energy consumption analysis and non-destructive testing. However, existing methods typically require dense scene measurements and often rely on RGB images for 3D geometry reconstruction, with thermal information being projected post-reconstruction. This two-step strategy, adopted due to the lack of texture in thermal images, can lead to disparities between the geometry and temperatures of the reconstructed objects and those of the actual scene. To address this challenge, we propose ThermoNeRF, a novel multimodal approach based on Neural Radiance Fields, capable of rendering new RGB and thermal views of a scene jointly. To overcome the lack of texture in thermal images, we use paired RGB and thermal images to learn scene density, while distinct networks estimate color and temperature information. Furthermore, we introduce ThermoScenes, a new dataset to palliate the lack of available RGB+thermal datasets for scene reconstruction. Experimental results validate that ThermoNeRF achieves accurate thermal image synthesis, with an average mean absolute error of 1.5$^\circ$C, an improvement of over 50% compared to using concatenated RGB+thermal data with Nerfacto, a state-of-the-art NeRF method.
3QFP: Efficient neural implicit surface reconstruction using Tri-Quadtrees and Fourier feature Positional encoding
Jan 13, 2024Neural implicit surface representations are currently receiving a lot of interest as a means to achieve high-fidelity surface reconstruction at a low memory cost, compared to traditional explicit representations.However, state-of-the-art methods still struggle with excessive memory usage and non-smooth surfaces. This is particularly problematic in large-scale applications with sparse inputs, as is common in robotics use cases. To address these issues, we first introduce a sparse structure, \emph{tri-quadtrees}, which represents the environment using learnable features stored in three planar quadtree projections. Secondly, we concatenate the learnable features with a Fourier feature positional encoding. The combined features are then decoded into signed distance values through a small multi-layer perceptron. We demonstrate that this approach facilitates smoother reconstruction with a higher completion ratio with fewer holes. Compared to two recent baselines, one implicit and one explicit, our approach requires only 10\%--50\% as much memory, while achieving competitive quality.
TEAM: a parameter-free algorithm to teach collaborative robots motions from user demonstrations
Sep 14, 2022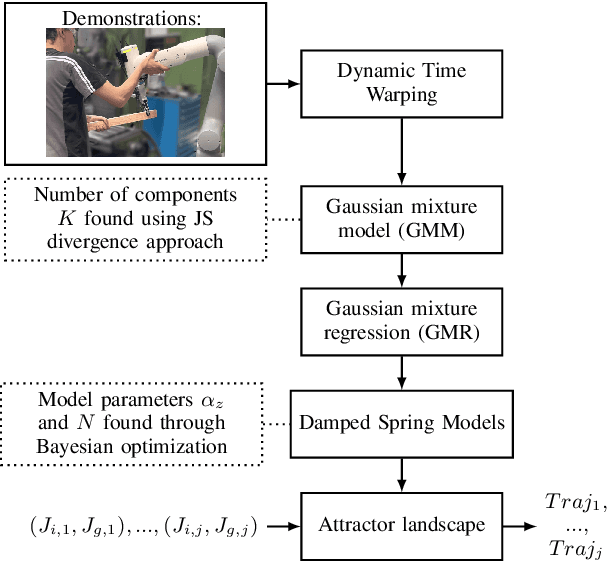
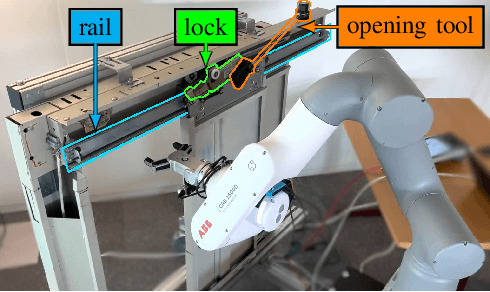
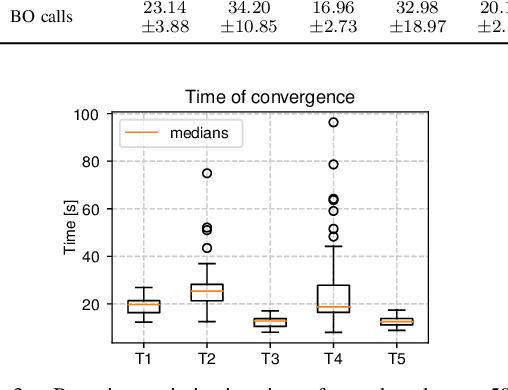

Collaborative robots (cobots) built to work alongside humans must be able to quickly learn new skills and adapt to new task configurations. Learning from demonstration (LfD) enables cobots to learn and adapt motions to different use conditions. However, state-of-the-art LfD methods require manually tuning intrinsic parameters and have rarely been used in industrial contexts without experts. In this paper, the development and implementation of a LfD framework for industrial applications with naive users is presented. We propose a parameter-free method based on probabilistic movement primitives, where all the parameters are pre-determined using Jensen-Shannon divergence and bayesian optimization; thus, users do not have to perform manual parameter tuning. This method learns motions from a small dataset of user demonstrations, and generalizes the motion to various scenarios and conditions. We evaluate the method extensively in two field tests: one where the cobot works on elevator door maintenance, and one where three Schindler workers teach the cobot tasks useful for their workflow. Errors between the cobot end-effector and target positions range from $0$ to $1.48\pm0.35$mm. For all tests, no task failures were reported. Questionnaires completed by the Schindler workers highlighted the method's ease of use, feeling of safety, and the accuracy of the reproduced motion. Our code and recorded trajectories are made available online for reproduction.
SLAM auto-complete: completing a robot map using an emergency map
Nov 08, 2017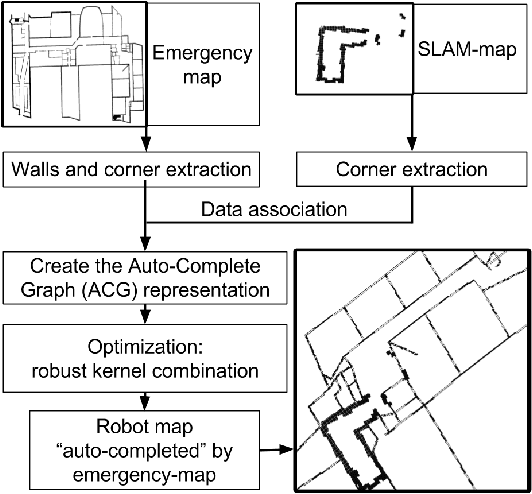

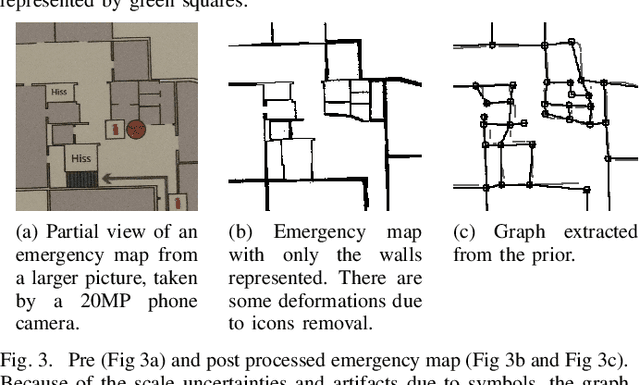

In search and rescue missions, time is an important factor; fast navigation and quickly acquiring situation awareness might be matters of life and death. Hence, the use of robots in such scenarios has been restricted by the time needed to explore and build a map. One way to speed up exploration and mapping is to reason about unknown parts of the environment using prior information. While previous research on using external priors for robot mapping mainly focused on accurate maps or aerial images, such data are not always possible to get, especially indoor. We focus on emergency maps as priors for robot mapping since they are easy to get and already extensively used by firemen in rescue missions. However, those maps can be outdated, information might be missing, and the scales of rooms are typically not consistent. We have developed a formulation of graph-based SLAM that incorporates information from an emergency map. The graph-SLAM is optimized using a combination of robust kernels, fusing the emergency map and the robot map into one map, even when faced with scale inaccuracies and inexact start poses. We typically have more than 50% of wrong correspondences in the settings studied in this paper, and the method we propose correctly handles them. Experiments in an office environment show that we can handle up to 70% of wrong correspondences and still get the expected result. The robot can navigate and explore while taking into account places it has not yet seen. We demonstrate this in a test scenario and also show that the emergency map is enhanced by adding information not represented such as closed doors or new walls.
* 6 pages, 9 figures
A method to segment maps from different modalities using free space layout - MAORIS : MAp Of RIpples Segmentation
Sep 28, 2017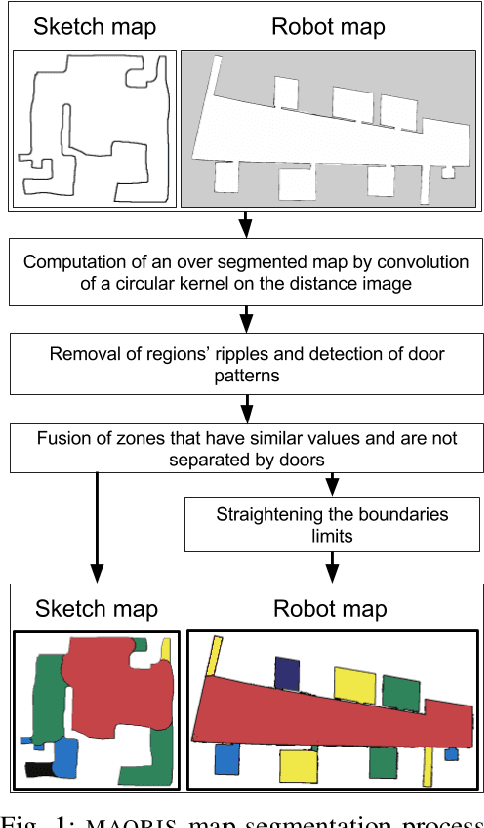
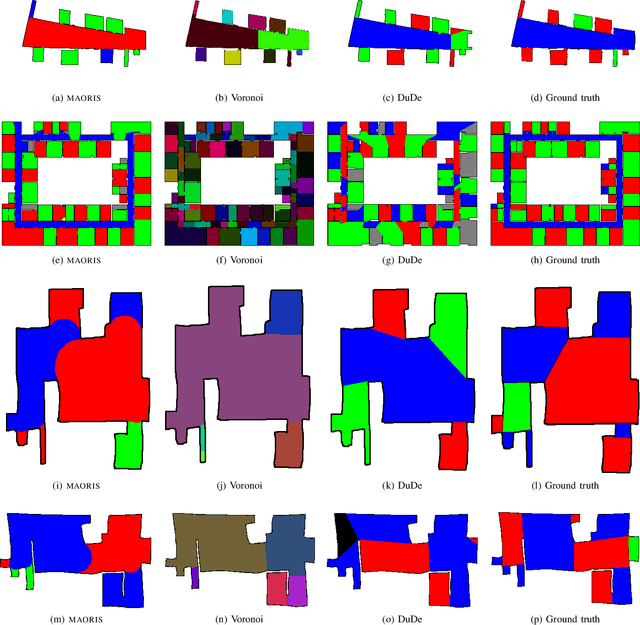
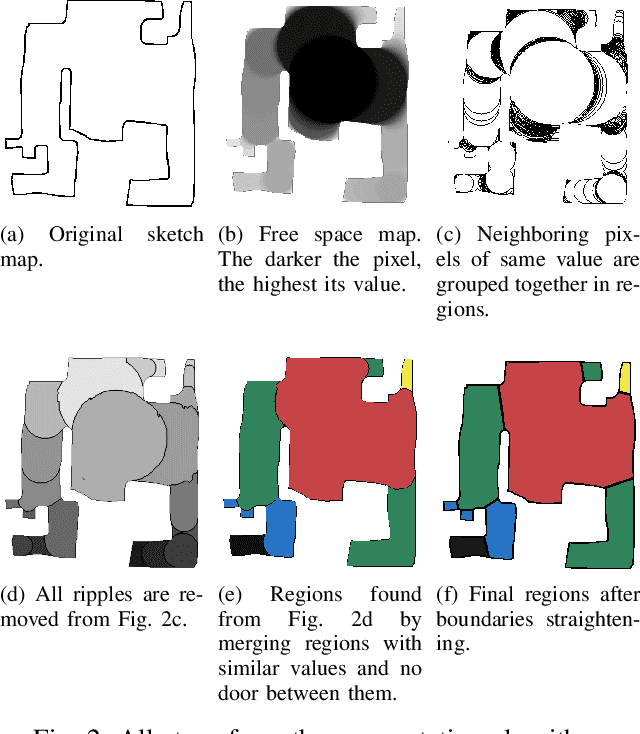
How to divide floor plans or navigation maps into a semantic representation, such as rooms and corridors, is an important research question in fields such as human-robot interaction, place categorization, or semantic mapping. While most algorithms focus on segmenting robot built maps, those are not the only types of map a robot, or its user, can use. We have developed a method for segmenting maps from different modalities, focusing on robot built maps and hand-drawn sketch maps, and show better results than state of the art for both types. Our method segments the map by doing a convolution between the distance image of the map and a circular kernel, and grouping pixels of the same value. Segmentation is done by detecting ripple like patterns where pixel values vary quickly, and merging neighboring regions with similar values. We identify a flaw in segmentation evaluation metric used in recent works and propose a more consistent metric. We compare our results to ground-truth segmentations of maps from a publicly available dataset, on which we obtain a better Matthews correlation coefficient (MCC) than state of the art with 0.98 compared to 0.85 for a recent Voronoi-based segmentation method and 0.78 for the DuDe segmentation method. We also provide a dataset of sketches of an indoor environment, with two possible sets of ground truth segmentations, on which our method obtains a MCC of 0.82 against 0.40 for the Voronoi-based segmentation method and 0.45 for DuDe.