 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Surface and Reflectance Modelling from 3D Radar Data with Neural Radiance Fields
Mar 26, 2026Robust scene representation is essential for autonomous systems to safely operate in challenging low-visibility environments. Radar has a clear advantage over cameras and lidars in these conditions due to its resilience to environmental factors such as fog, smoke, or dust. However, radar data is inherently sparse and noisy, making reliable 3D surface reconstruction challenging. To address these challenges, we propose a neural implicit approach for 3D mapping from radar point clouds, which jointly models scene geometry and view-dependent radar intensities. Our method leverages a memory-efficient hybrid feature encoding to learn a continuous Signed Distance Field (SDF) for surface reconstruction, while also capturing radar-specific reflective properties. We show that our approach produces smoother, more accurate 3D surface reconstructions compared to existing lidar-based reconstruction methods applied to radar data, and can reconstruct view-dependent radar intensities. We also show that in general, as input point clouds get sparser, neural implicit representations render more faithful surfaces, compared to traditional explicit SDFs and meshing techniques.
Conflict Mitigation in Shared Environments using Flow-Aware Multi-Agent Path Finding
Mar 13, 2026Deploying multi-robot systems in environments shared with dynamic and uncontrollable agents presents significant challenges, especially for large robot fleets. In such environments, individual robot operations can be delayed due to unforeseen conflicts with uncontrollable agents. While existing research primarily focuses on preserving the completeness of Multi-Agent Path Finding (MAPF) solutions considering delays, there is limited emphasis on utilizing additional environmental information to enhance solution quality in the presence of other dynamic agents. To this end, we propose Flow-Aware Multi-Agent Path Finding (FA-MAPF), a novel framework that integrates learned motion patterns of uncontrollable agents into centralized MAPF algorithms. Our evaluation, conducted on a diverse set of benchmark maps with simulated uncontrollable agents and on a real-world map with recorded human trajectories, demonstrates the effectiveness of FA-MAPF compared to state-of-the-art baselines. The experimental results show that FA-MAPF can consistently reduce conflicts with uncontrollable agents, up to 55%, without compromising task efficiency.
Dense Dynamic Scene Reconstruction and Camera Pose Estimation from Multi-View Videos
Mar 12, 2026We address the challenging problem of dense dynamic scene reconstruction and camera pose estimation from multiple freely moving cameras -- a setting that arises naturally when multiple observers capture a shared event. Prior approaches either handle only single-camera input or require rigidly mounted, pre-calibrated camera rigs, limiting their practical applicability. We propose a two-stage optimization framework that decouples the task into robust camera tracking and dense depth refinement. In the first stage, we extend single-camera visual SLAM to the multi-camera setting by constructing a spatiotemporal connection graph that exploits both intra-camera temporal continuity and inter-camera spatial overlap, enabling consistent scale and robust tracking. To ensure robustness under limited overlap, we introduce a wide-baseline initialization strategy using feed-forward reconstruction models. In the second stage, we refine depth and camera poses by optimizing dense inter- and intra-camera consistency using wide-baseline optical flow. Additionally, we introduce MultiCamRobolab, a new real-world dataset with ground-truth poses from a motion capture system. Finally, we demonstrate that our method significantly outperforms state-of-the-art feed-forward models on both synthetic and real-world benchmarks, while requiring less memory.
Digging for Data: Experiments in Rock Pile Characterization Using Only Proprioceptive Sensing in Excavation
Feb 11, 2026Characterization of fragmented rock piles is a fundamental task in the mining and quarrying industries, where rock is fragmented by blasting, transported using wheel loaders, and then sent for further processing. This field report studies a novel method for estimating the relative particle size of fragmented rock piles from only proprioceptive data collected while digging with a wheel loader. Rather than employ exteroceptive sensors (e.g., cameras or LiDAR sensors) to estimate rock particle sizes, the studied method infers rock fragmentation from an excavator's inertial response during excavation. This paper expands on research that postulated the use of wavelet analysis to construct a unique feature that is proportional to the level of rock fragmentation. We demonstrate through extensive field experiments that the ratio of wavelet features, constructed from data obtained by excavating in different rock piles with different size distributions, approximates the ratio of the mean particle size of the two rock piles. Full-scale excavation experiments were performed with a battery electric, 18-tonne capacity, load-haul-dump (LHD) machine in representative conditions in an operating quarry. The relative particle size estimates generated with the proposed sensing methodology are compared with those obtained from both a vision-based fragmentation analysis tool and from sieving of sampled materials.
HiCrowd: Hierarchical Crowd Flow Alignment for Dense Human Environments
Feb 05, 2026Navigating through dense human crowds remains a significant challenge for mobile robots. A key issue is the freezing robot problem, where the robot struggles to find safe motions and becomes stuck within the crowd. To address this, we propose HiCrowd, a hierarchical framework that integrates reinforcement learning (RL) with model predictive control (MPC). HiCrowd leverages surrounding pedestrian motion as guidance, enabling the robot to align with compatible crowd flows. A high-level RL policy generates a follow point to align the robot with a suitable pedestrian group, while a low-level MPC safely tracks this guidance with short horizon planning. The method combines long-term crowd aware decision making with safe short-term execution. We evaluate HiCrowd against reactive and learning-based baselines in offline setting (replaying recorded human trajectories) and online setting (human trajectories are updated to react to the robot in simulation). Experiments on a real-world dataset and a synthetic crowd dataset show that our method outperforms in navigation efficiency and safety, while reducing freezing behaviors. Our results suggest that leveraging human motion as guidance, rather than treating humans solely as dynamic obstacles, provides a powerful principle for safe and efficient robot navigation in crowds.
Large-scale visual SLAM for in-the-wild videos
Apr 29, 2025Accurate and robust 3D scene reconstruction from casual, in-the-wild videos can significantly simplify robot deployment to new environments. However, reliable camera pose estimation and scene reconstruction from such unconstrained videos remains an open challenge. Existing visual-only SLAM methods perform well on benchmark datasets but struggle with real-world footage which often exhibits uncontrolled motion including rapid rotations and pure forward movements, textureless regions, and dynamic objects. We analyze the limitations of current methods and introduce a robust pipeline designed to improve 3D reconstruction from casual videos. We build upon recent deep visual odometry methods but increase robustness in several ways. Camera intrinsics are automatically recovered from the first few frames using structure-from-motion. Dynamic objects and less-constrained areas are masked with a predictive model. Additionally, we leverage monocular depth estimates to regularize bundle adjustment, mitigating errors in low-parallax situations. Finally, we integrate place recognition and loop closure to reduce long-term drift and refine both intrinsics and pose estimates through global bundle adjustment. We demonstrate large-scale contiguous 3D models from several online videos in various environments. In contrast, baseline methods typically produce locally inconsistent results at several points, producing separate segments or distorted maps. In lieu of ground-truth pose data, we evaluate map consistency, execution time and visual accuracy of re-rendered NeRF models. Our proposed system establishes a new baseline for visual reconstruction from casual uncontrolled videos found online, demonstrating more consistent reconstructions over longer sequences of in-the-wild videos than previously achieved.
Multimodal Interaction and Intention Communication for Industrial Robots
Feb 25, 2025

Successful adoption of industrial robots will strongly depend on their ability to safely and efficiently operate in human environments, engage in natural communication, understand their users, and express intentions intuitively while avoiding unnecessary distractions. To achieve this advanced level of Human-Robot Interaction (HRI), robots need to acquire and incorporate knowledge of their users' tasks and environment and adopt multimodal communication approaches with expressive cues that combine speech, movement, gazes, and other modalities. This paper presents several methods to design, enhance, and evaluate expressive HRI systems for non-humanoid industrial robots. We present the concept of a small anthropomorphic robot communicating as a proxy for its non-humanoid host, such as a forklift. We developed a multimodal and LLM-enhanced communication framework for this robot and evaluated it in several lab experiments, using gaze tracking and motion capture to quantify how users perceive the robot and measure the task progress.
Evaluating Efficiency and Engagement in Scripted and LLM-Enhanced Human-Robot Interactions
Jan 21, 2025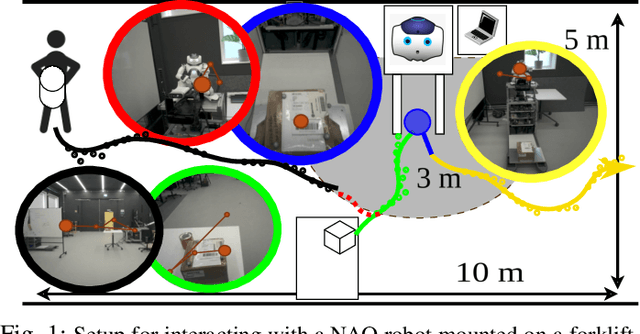
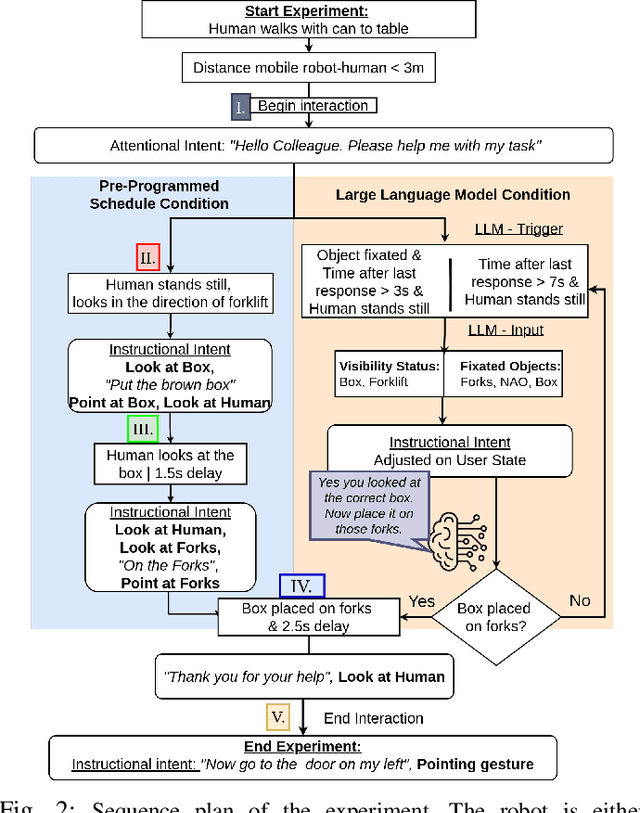

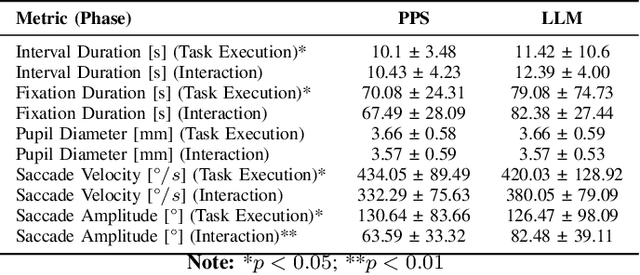
To achieve natural and intuitive interaction with people, HRI frameworks combine a wide array of methods for human perception, intention communication, human-aware navigation and collaborative action. In practice, when encountering unpredictable behavior of people or unexpected states of the environment, these frameworks may lack the ability to dynamically recognize such states, adapt and recover to resume the interaction. Large Language Models (LLMs), owing to their advanced reasoning capabilities and context retention, present a promising solution for enhancing robot adaptability. This potential, however, may not directly translate to improved interaction metrics. This paper considers a representative interaction with an industrial robot involving approach, instruction, and object manipulation, implemented in two conditions: (1) fully scripted and (2) including LLM-enhanced responses. We use gaze tracking and questionnaires to measure the participants' task efficiency, engagement, and robot perception. The results indicate higher subjective ratings for the LLM condition, but objective metrics show that the scripted condition performs comparably, particularly in efficiency and focus during simple tasks. We also note that the scripted condition may have an edge over LLM-enhanced responses in terms of response latency and energy consumption, especially for trivial and repetitive interactions.
Fast Online Learning of CLiFF-maps in Changing Environments
Oct 16, 2024
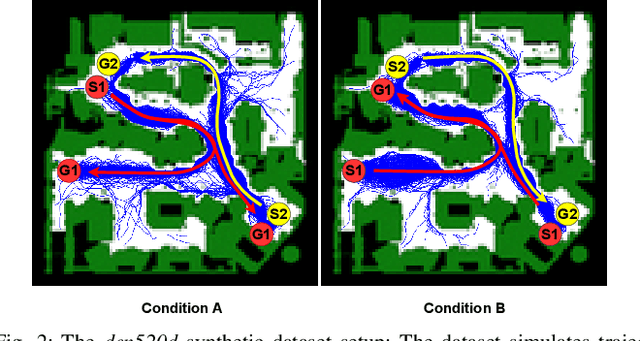
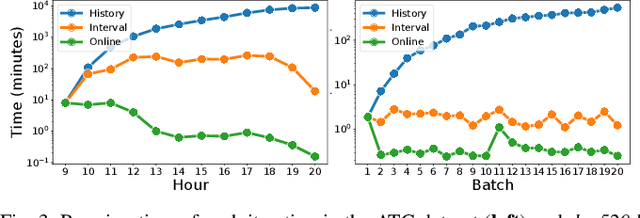

Maps of dynamics are effective representations of motion patterns learned from prior observations, with recent research demonstrating their ability to enhance performance in various downstream tasks such as human-aware robot navigation, long-term human motion prediction, and robot localization. Current advancements have primarily concentrated on methods for learning maps of human flow in environments where the flow is static, i.e., not assumed to change over time. In this paper we propose a method to update the CLiFF-map, one type of map of dynamics, for achieving efficient life-long robot operation. As new observations are collected, our goal is to update a CLiFF-map to effectively and accurately integrate new observations, while retaining relevant historic motion patterns. The proposed online update method maintains a probabilistic representation in each observed location, updating parameters by continuously tracking sufficient statistics. In experiments using both synthetic and real-world datasets, we show that our method is able to maintain accurate representations of human motion dynamics, contributing to high performance flow-compliant planning downstream tasks, while being orders of magnitude faster than the comparable baselines.
Human Gaze and Head Rotation during Navigation, Exploration and Object Manipulation in Shared Environments with Robots
Jun 10, 2024
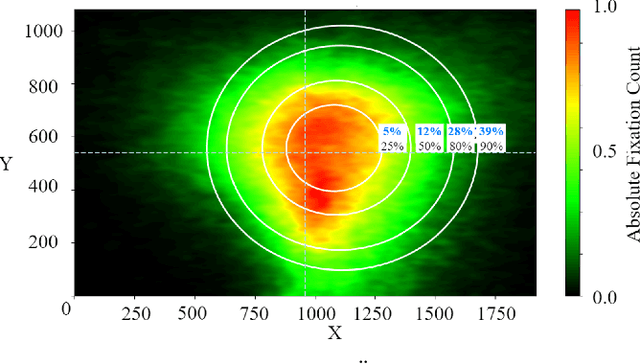
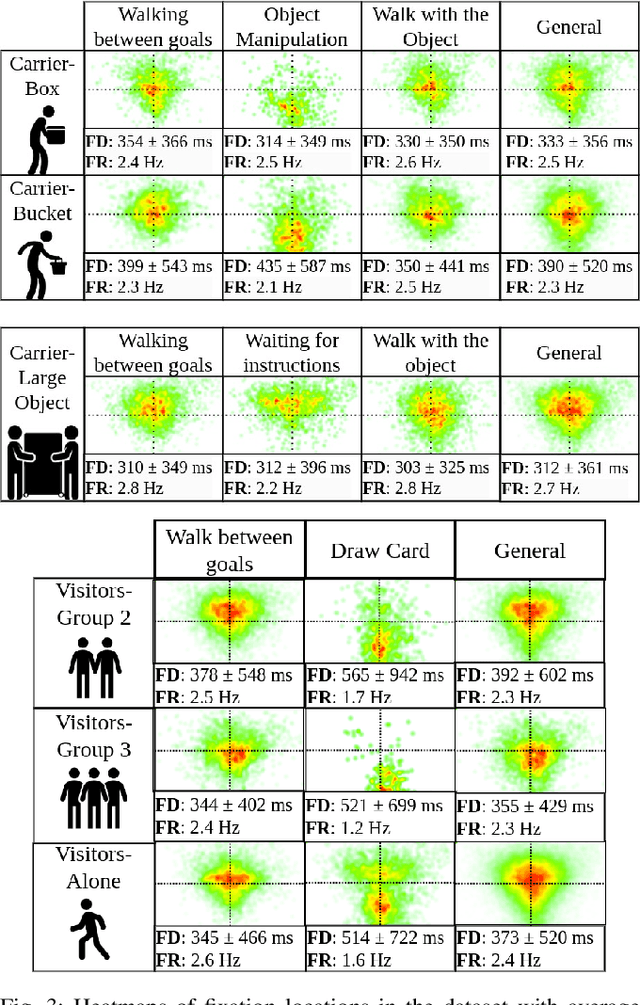
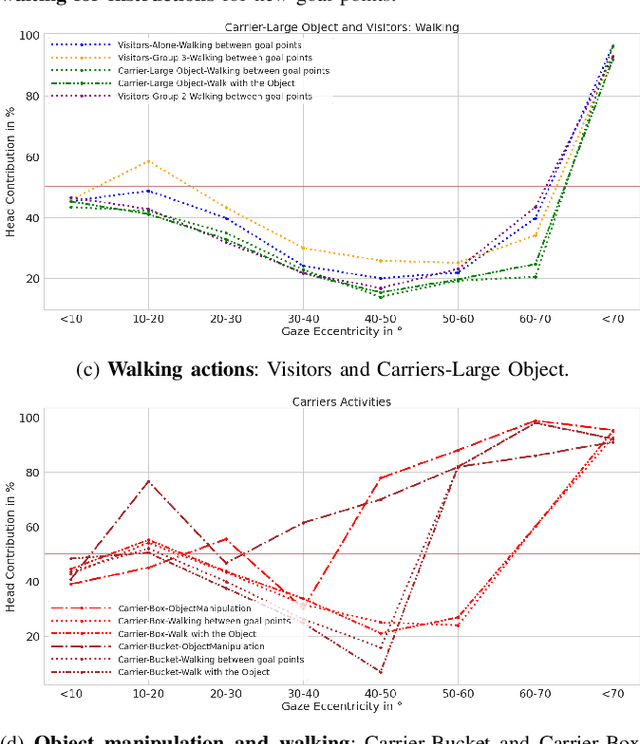
The human gaze is an important cue to signal intention, attention, distraction, and the regions of interest in the immediate surroundings. Gaze tracking can transform how robots perceive, understand, and react to people, enabling new modes of robot control, interaction, and collaboration. In this paper, we use gaze tracking data from a rich dataset of human motion (TH\"OR-MAGNI) to investigate the coordination between gaze direction and head rotation of humans engaged in various indoor activities involving navigation, interaction with objects, and collaboration with a mobile robot. In particular, we study the spread and central bias of fixations in diverse activities and examine the correlation between gaze direction and head rotation. We introduce various human motion metrics to enhance the understanding of gaze behavior in dynamic interactions. Finally, we apply semantic object labeling to decompose the gaze distribution into activity-relevant regions.
* This is the final version of the accepted version of the manuscript that will be published in the 2024 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN). Copyright 2024 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses