 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHÖR-MAGNI: A Large-scale Indoor Motion Capture Recording of Human Movement and Robot Interaction
Mar 14, 2024



We present a new large dataset of indoor human and robot navigation and interaction, called TH\"OR-MAGNI, that is designed to facilitate research on social navigation: e.g., modelling and predicting human motion, analyzing goal-oriented interactions between humans and robots, and investigating visual attention in a social interaction context. TH\"OR-MAGNI was created to fill a gap in available datasets for human motion analysis and HRI. This gap is characterized by a lack of comprehensive inclusion of exogenous factors and essential target agent cues, which hinders the development of robust models capable of capturing the relationship between contextual cues and human behavior in different scenarios. Unlike existing datasets, TH\"OR-MAGNI includes a broader set of contextual features and offers multiple scenario variations to facilitate factor isolation. The dataset includes many social human-human and human-robot interaction scenarios, rich context annotations, and multi-modal data, such as walking trajectories, gaze tracking data, and lidar and camera streams recorded from a mobile robot. We also provide a set of tools for visualization and processing of the recorded data. TH\"OR-MAGNI is, to the best of our knowledge, unique in the amount and diversity of sensor data collected in a contextualized and socially dynamic environment, capturing natural human-robot interactions.
CLiFF-LHMP: Using Spatial Dynamics Patterns for Long-Term Human Motion Prediction
Sep 13, 2023



Human motion prediction is important for mobile service robots and intelligent vehicles to operate safely and smoothly around people. The more accurate predictions are, particularly over extended periods of time, the better a system can, e.g., assess collision risks and plan ahead. In this paper, we propose to exploit maps of dynamics (MoDs, a class of general representations of place-dependent spatial motion patterns, learned from prior observations) for long-term human motion prediction (LHMP). We present a new MoD-informed human motion prediction approach, named CLiFF-LHMP, which is data efficient, explainable, and insensitive to errors from an upstream tracking system. Our approach uses CLiFF-map, a specific MoD trained with human motion data recorded in the same environment. We bias a constant velocity prediction with samples from the CLiFF-map to generate multi-modal trajectory predictions. In two public datasets we show that this algorithm outperforms the state of the art for predictions over very extended periods of time, achieving 45% more accurate prediction performance at 50s compared to the baseline.
A Data-Efficient Approach for Long-Term Human Motion Prediction Using Maps of Dynamics
Jun 06, 2023Human motion prediction is essential for the safe and smooth operation of mobile service robots and intelligent vehicles around people. Commonly used neural network-based approaches often require large amounts of complete trajectories to represent motion dynamics in complex semantically-rich spaces. This requirement may complicate deployment of physical systems in new environments, especially when the data is being collected online from onboard sensors. In this paper we explore a data-efficient alternative using maps of dynamics (MoD) to represent place-dependent multi-modal spatial motion patterns, learned from prior observations. Our approach can perform efficient human motion prediction in the long-term perspective of up to 60 seconds. We quantitatively evaluate its accuracy with limited amount of training data in comparison to an LSTM-based baseline, and qualitatively show that the predicted trajectories reflect the natural semantic properties of the environment, e.g. the locations of short- and long-term goals, navigation in narrow passages, around obstacles, etc.
The Magni Human Motion Dataset: Accurate, Complex, Multi-Modal, Natural, Semantically-Rich and Contextualized
Aug 31, 2022
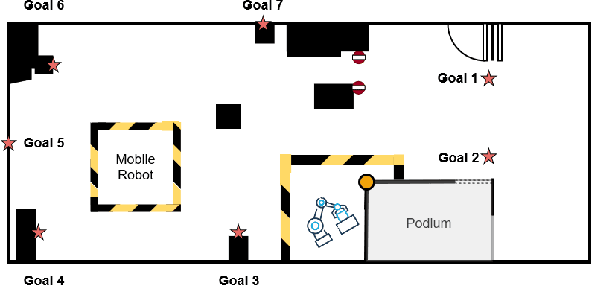


Rapid development of social robots stimulates active research in human motion modeling, interpretation and prediction, proactive collision avoidance, human-robot interaction and co-habitation in shared spaces. Modern approaches to this end require high quality datasets for training and evaluation. However, the majority of available datasets suffers from either inaccurate tracking data or unnatural, scripted behavior of the tracked people. This paper attempts to fill this gap by providing high quality tracking information from motion capture, eye-gaze trackers and on-board robot sensors in a semantically-rich environment. To induce natural behavior of the recorded participants, we utilise loosely scripted task assignment, which induces the participants navigate through the dynamic laboratory environment in a natural and purposeful way. The motion dataset, presented in this paper, sets a high quality standard, as the realistic and accurate data is enhanced with semantic information, enabling development of new algorithms which rely not only on the tracking information but also on contextual cues of the moving agents, static and dynamic environment.
THÖR: Human-Robot Indoor Navigation Experiment and Accurate Motion Trajectories Dataset
Sep 10, 2019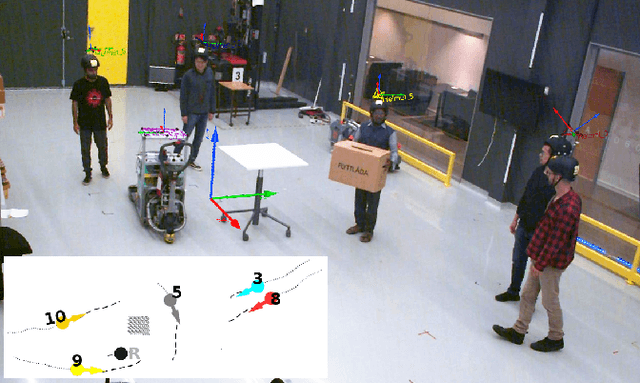
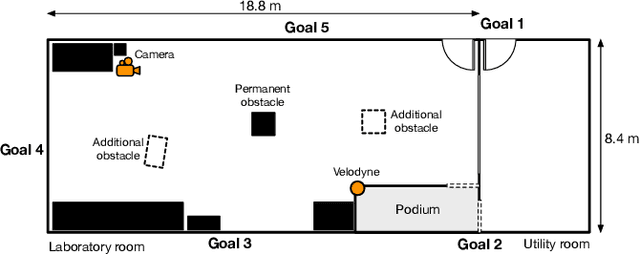

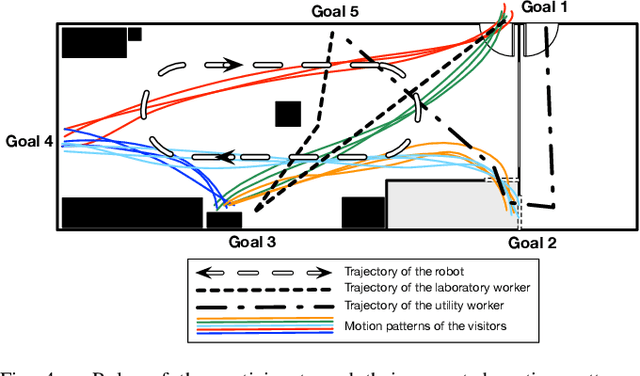
Understanding human behavior is key for robots and intelligent systems that share a space with people. Accordingly, research that enables such systems to perceive, track, learn and predict human behavior as well as to plan and interact with humans has received increasing attention over the last years. The availability of large human motion datasets that contain relevant levels of difficulty is fundamental to this research. Existing datasets are often limited in terms of information content, annotation quality or variability of human behavior. In this paper, we present TH\"OR, a new dataset with human motion trajectory and eye gaze data collected in an indoor environment with accurate ground truth for position, head orientation, gaze direction, social grouping, obstacles map and goal coordinates. TH\"OR also contains sensor data collected by a 3D lidar and involves a mobile robot navigating the space. We propose a set of metrics to quantitatively analyze motion trajectory datasets such as the average tracking duration, ground truth noise, curvature and speed variation of the trajectories. In comparison to prior art, our dataset has a larger variety in human motion behavior, is less noisy, and contains annotations at higher frequencies.