 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHÖR-MAGNI: A Large-scale Indoor Motion Capture Recording of Human Movement and Robot Interaction
Mar 14, 2024



We present a new large dataset of indoor human and robot navigation and interaction, called TH\"OR-MAGNI, that is designed to facilitate research on social navigation: e.g., modelling and predicting human motion, analyzing goal-oriented interactions between humans and robots, and investigating visual attention in a social interaction context. TH\"OR-MAGNI was created to fill a gap in available datasets for human motion analysis and HRI. This gap is characterized by a lack of comprehensive inclusion of exogenous factors and essential target agent cues, which hinders the development of robust models capable of capturing the relationship between contextual cues and human behavior in different scenarios. Unlike existing datasets, TH\"OR-MAGNI includes a broader set of contextual features and offers multiple scenario variations to facilitate factor isolation. The dataset includes many social human-human and human-robot interaction scenarios, rich context annotations, and multi-modal data, such as walking trajectories, gaze tracking data, and lidar and camera streams recorded from a mobile robot. We also provide a set of tools for visualization and processing of the recorded data. TH\"OR-MAGNI is, to the best of our knowledge, unique in the amount and diversity of sensor data collected in a contextualized and socially dynamic environment, capturing natural human-robot interactions.
Advantages of Multimodal versus Verbal-Only Robot-to-Human Communication with an Anthropomorphic Robotic Mock Driver
Jul 03, 2023



Robots are increasingly used in shared environments with humans, making effective communication a necessity for successful human-robot interaction. In our work, we study a crucial component: active communication of robot intent. Here, we present an anthropomorphic solution where a humanoid robot communicates the intent of its host robot acting as an "Anthropomorphic Robotic Mock Driver" (ARMoD). We evaluate this approach in two experiments in which participants work alongside a mobile robot on various tasks, while the ARMoD communicates a need for human attention, when required, or gives instructions to collaborate on a joint task. The experiments feature two interaction styles of the ARMoD: a verbal-only mode using only speech and a multimodal mode, additionally including robotic gaze and pointing gestures to support communication and register intent in space. Our results show that the multimodal interaction style, including head movements and eye gaze as well as pointing gestures, leads to more natural fixation behavior. Participants naturally identified and fixated longer on the areas relevant for intent communication, and reacted faster to instructions in collaborative tasks. Our research further indicates that the ARMoD intent communication improves engagement and social interaction with mobile robots in workplace settings.
The Effect of Anthropomorphism on Trust in an Industrial Human-Robot Interaction
Sep 01, 2022
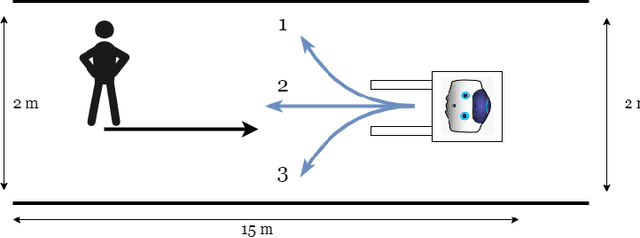
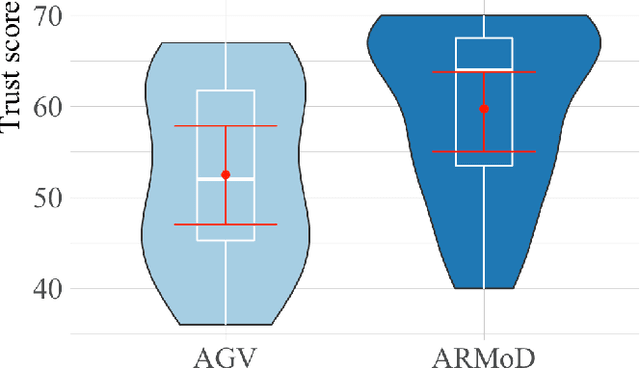

Robots are increasingly deployed in spaces shared with humans, including home settings and industrial environments. In these environments, the interaction between humans and robots (HRI) is crucial for safety, legibility, and efficiency. A key factor in HRI is trust, which modulates the acceptance of the system. Anthropomorphism has been shown to modulate trust development in a robot, but robots in industrial environments are not usually anthropomorphic. We designed a simple interaction in an industrial environment in which an anthropomorphic mock driver (ARMoD) robot simulates to drive an autonomous guided vehicle (AGV). The task consisted of a human crossing paths with the AGV, with or without the ARMoD mounted on the top, in a narrow corridor. The human and the system needed to negotiate trajectories when crossing paths, meaning that the human had to attend to the trajectory of the robot to avoid a collision with it. There was a significant increment in the reported trust scores in the condition where the ARMoD was present, showing that the presence of an anthropomorphic robot is enough to modulate the trust, even in limited interactions as the one we present here.
The Magni Human Motion Dataset: Accurate, Complex, Multi-Modal, Natural, Semantically-Rich and Contextualized
Aug 31, 2022
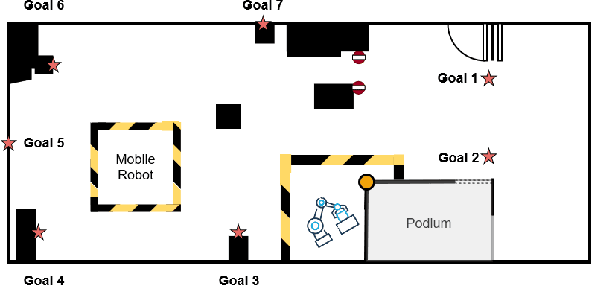


Rapid development of social robots stimulates active research in human motion modeling, interpretation and prediction, proactive collision avoidance, human-robot interaction and co-habitation in shared spaces. Modern approaches to this end require high quality datasets for training and evaluation. However, the majority of available datasets suffers from either inaccurate tracking data or unnatural, scripted behavior of the tracked people. This paper attempts to fill this gap by providing high quality tracking information from motion capture, eye-gaze trackers and on-board robot sensors in a semantically-rich environment. To induce natural behavior of the recorded participants, we utilise loosely scripted task assignment, which induces the participants navigate through the dynamic laboratory environment in a natural and purposeful way. The motion dataset, presented in this paper, sets a high quality standard, as the realistic and accurate data is enhanced with semantic information, enabling development of new algorithms which rely not only on the tracking information but also on contextual cues of the moving agents, static and dynamic environment.