 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Expressive Motion Generation Using Dynamic Movement Primitives
Apr 09, 2025Our goal is to enable social robots to interact autonomously with humans in a realistic, engaging, and expressive manner. The 12 Principles of Animation [1] are a well-established framework animators use to create movements that make characters appear convincing, dynamic, and emotionally expressive. This paper proposes a novel approach that leverages Dynamic Movement Primitives (DMPs) to implement key animation principles, providing a learnable, explainable, modulable, online adaptable and composable model for automatic expressive motion generation. DMPs, originally developed for general imitation learning in robotics and grounded in a spring-damper system design, offer mathematical properties that make them particularly suitable for this task. Specifically, they enable modulation of the intensities of individual principles and facilitate the decomposition of complex, expressive motion sequences into learnable and parametrizable primitives. We present the mathematical formulation of the parameterized animation principles and demonstrate the effectiveness of our framework through experiments and application on three robotic platforms with different kinematic configurations, in simulation, on actual robots and in a user study. Our results show that the approach allows for creating diverse and nuanced expressions using a single base model.
Long-Term Planning Around Humans in Domestic Environments with 3D Scene Graphs
Mar 12, 2025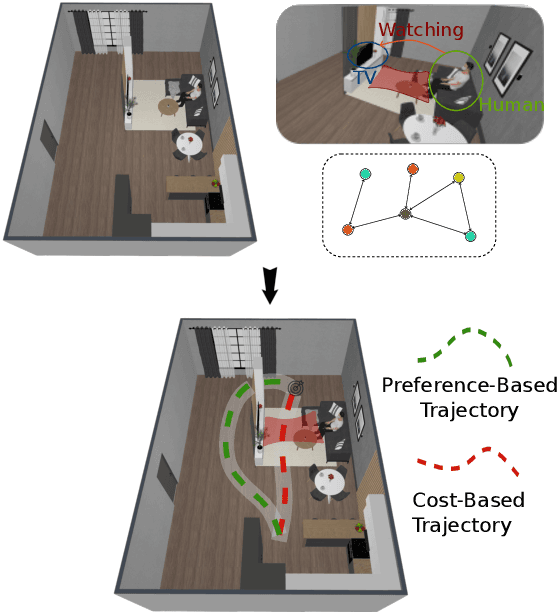
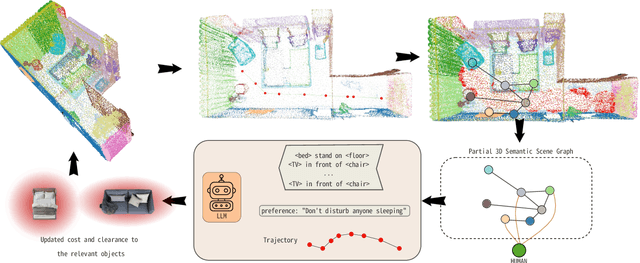
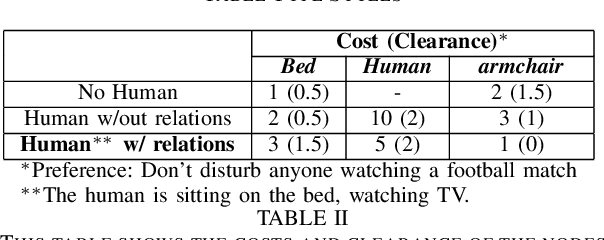
Long-term planning for robots operating in domestic environments poses unique challenges due to the interactions between humans, objects, and spaces. Recent advancements in trajectory planning have leveraged vision-language models (VLMs) to extract contextual information for robots operating in real-world environments. While these methods achieve satisfying performance, they do not explicitly model human activities. Such activities influence surrounding objects and reshape spatial constraints. This paper presents a novel approach to trajectory planning that integrates human preferences, activities, and spatial context through an enriched 3D scene graph (3DSG) representation. By incorporating activity-based relationships, our method captures the spatial impact of human actions, leading to more context-sensitive trajectory adaptation. Preliminary results demonstrate that our approach effectively assigns costs to spaces influenced by human activities, ensuring that the robot trajectory remains contextually appropriate and sensitive to the ongoing environment. This balance between task efficiency and social appropriateness enhances context-aware human-robot interactions in domestic settings. Future work includes implementing a full planning pipeline and conducting user studies to evaluate trajectory acceptability.
FunGraph: Functionality Aware 3D Scene Graphs for Language-Prompted Scene Interaction
Mar 10, 2025The concept of 3D scene graphs is increasingly recognized as a powerful semantic and hierarchical representation of the environment. Current approaches often address this at a coarse, object-level resolution. In contrast, our goal is to develop a representation that enables robots to directly interact with their environment by identifying both the location of functional interactive elements and how these can be used. To achieve this, we focus on detecting and storing objects at a finer resolution, focusing on affordance-relevant parts. The primary challenge lies in the scarcity of data that extends beyond instance-level detection and the inherent difficulty of capturing detailed object features using robotic sensors. We leverage currently available 3D resources to generate 2D data and train a detector, which is then used to augment the standard 3D scene graph generation pipeline. Through our experiments, we demonstrate that our approach achieves functional element segmentation comparable to state-of-the-art 3D models and that our augmentation enables task-driven affordance grounding with higher accuracy than the current solutions.
The Child Factor in Child-Robot Interaction: Discovering the Impact of Developmental Stage and Individual Characteristics
Apr 20, 2024
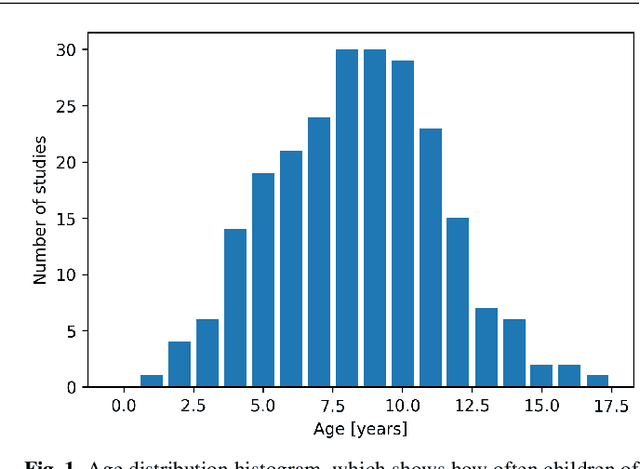
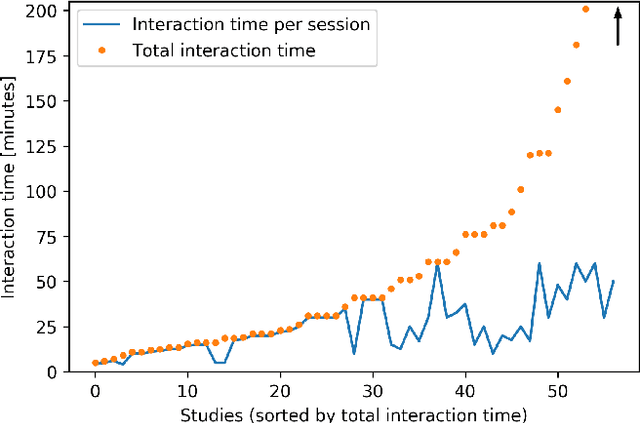
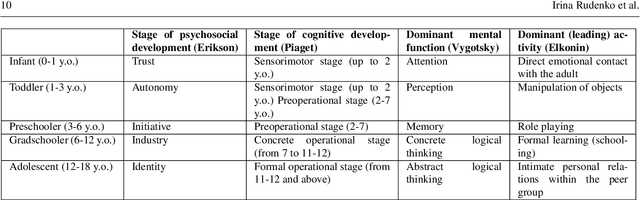
Social robots, owing to their embodied physical presence in human spaces and the ability to directly interact with the users and their environment, have a great potential to support children in various activities in education, healthcare and daily life. Child-Robot Interaction (CRI), as any domain involving children, inevitably faces the major challenge of designing generalized strategies to work with unique, turbulent and very diverse individuals. Addressing this challenging endeavor requires to combine the standpoint of the robot-centered perspective, i.e. what robots technically can and are best positioned to do, with that of the child-centered perspective, i.e. what children may gain from the robot and how the robot should act to best support them in reaching the goals of the interaction. This article aims to help researchers bridge the two perspectives and proposes to address the development of CRI scenarios with insights from child psychology and child development theories. To that end, we review the outcomes of the CRI studies, outline common trends and challenges, and identify two key factors from child psychology that impact child-robot interactions, especially in a long-term perspective: developmental stage and individual characteristics. For both of them we discuss prospective experiment designs which support building naturally engaging and sustainable interactions.
CLiFF-LHMP: Using Spatial Dynamics Patterns for Long-Term Human Motion Prediction
Sep 13, 2023



Human motion prediction is important for mobile service robots and intelligent vehicles to operate safely and smoothly around people. The more accurate predictions are, particularly over extended periods of time, the better a system can, e.g., assess collision risks and plan ahead. In this paper, we propose to exploit maps of dynamics (MoDs, a class of general representations of place-dependent spatial motion patterns, learned from prior observations) for long-term human motion prediction (LHMP). We present a new MoD-informed human motion prediction approach, named CLiFF-LHMP, which is data efficient, explainable, and insensitive to errors from an upstream tracking system. Our approach uses CLiFF-map, a specific MoD trained with human motion data recorded in the same environment. We bias a constant velocity prediction with samples from the CLiFF-map to generate multi-modal trajectory predictions. In two public datasets we show that this algorithm outperforms the state of the art for predictions over very extended periods of time, achieving 45% more accurate prediction performance at 50s compared to the baseline.
Advantages of Multimodal versus Verbal-Only Robot-to-Human Communication with an Anthropomorphic Robotic Mock Driver
Jul 03, 2023



Robots are increasingly used in shared environments with humans, making effective communication a necessity for successful human-robot interaction. In our work, we study a crucial component: active communication of robot intent. Here, we present an anthropomorphic solution where a humanoid robot communicates the intent of its host robot acting as an "Anthropomorphic Robotic Mock Driver" (ARMoD). We evaluate this approach in two experiments in which participants work alongside a mobile robot on various tasks, while the ARMoD communicates a need for human attention, when required, or gives instructions to collaborate on a joint task. The experiments feature two interaction styles of the ARMoD: a verbal-only mode using only speech and a multimodal mode, additionally including robotic gaze and pointing gestures to support communication and register intent in space. Our results show that the multimodal interaction style, including head movements and eye gaze as well as pointing gestures, leads to more natural fixation behavior. Participants naturally identified and fixated longer on the areas relevant for intent communication, and reacted faster to instructions in collaborative tasks. Our research further indicates that the ARMoD intent communication improves engagement and social interaction with mobile robots in workplace settings.
The e-Bike Motor Assembly: Towards Advanced Robotic Manipulation for Flexible Manufacturing
Apr 20, 2023



Robotic manipulation is currently undergoing a profound paradigm shift due to the increasing needs for flexible manufacturing systems, and at the same time, because of the advances in enabling technologies such as sensing, learning, optimization, and hardware. This demands for robots that can observe and reason about their workspace, and that are skillfull enough to complete various assembly processes in weakly-structured settings. Moreover, it remains a great challenge to enable operators for teaching robots on-site, while managing the inherent complexity of perception, control, motion planning and reaction to unexpected situations. Motivated by real-world industrial applications, this paper demonstrates the potential of such a paradigm shift in robotics on the industrial case of an e-Bike motor assembly. The paper presents a concept for teaching and programming adaptive robots on-site and demonstrates their potential for the named applications. The framework includes: (i) a method to teach perception systems onsite in a self-supervised manner, (ii) a general representation of object-centric motion skills and force-sensitive assembly skills, both learned from demonstration, (iii) a sequencing approach that exploits a human-designed plan to perform complex tasks, and (iv) a system solution for adapting and optimizing skills online. The aforementioned components are interfaced through a four-layer software architecture that makes our framework a tangible industrial technology. To demonstrate the generality of the proposed framework, we provide, in addition to the motivating e-Bike motor assembly, a further case study on dense box packing for logistics automation.
The Magni Human Motion Dataset: Accurate, Complex, Multi-Modal, Natural, Semantically-Rich and Contextualized
Aug 31, 2022


Rapid development of social robots stimulates active research in human motion modeling, interpretation and prediction, proactive collision avoidance, human-robot interaction and co-habitation in shared spaces. Modern approaches to this end require high quality datasets for training and evaluation. However, the majority of available datasets suffers from either inaccurate tracking data or unnatural, scripted behavior of the tracked people. This paper attempts to fill this gap by providing high quality tracking information from motion capture, eye-gaze trackers and on-board robot sensors in a semantically-rich environment. To induce natural behavior of the recorded participants, we utilise loosely scripted task assignment, which induces the participants navigate through the dynamic laboratory environment in a natural and purposeful way. The motion dataset, presented in this paper, sets a high quality standard, as the realistic and accurate data is enhanced with semantic information, enabling development of new algorithms which rely not only on the tracking information but also on contextual cues of the moving agents, static and dynamic environment.
The Atlas Benchmark: an Automated Evaluation Framework for Human Motion Prediction
Jul 20, 2022
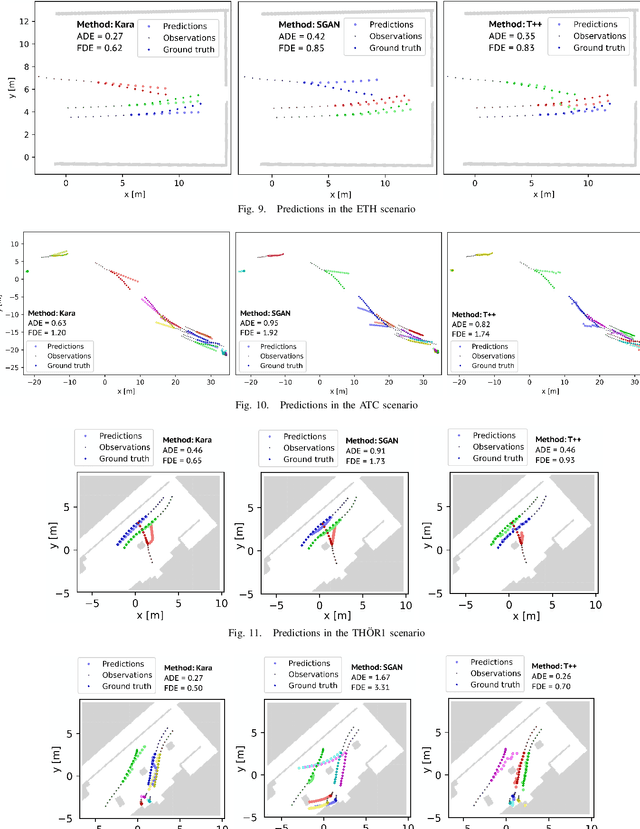
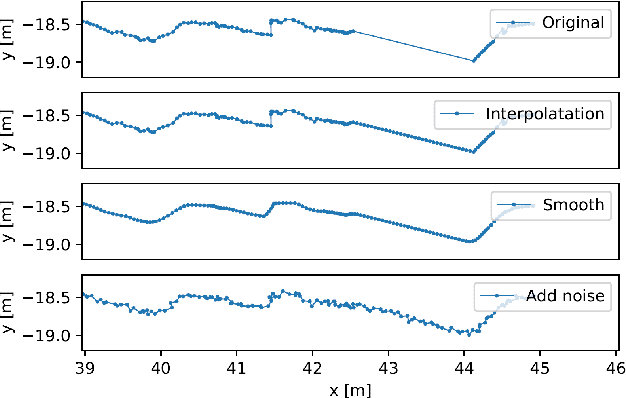
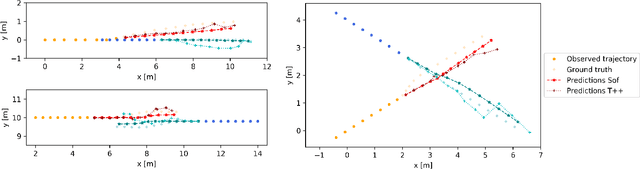
Human motion trajectory prediction, an essential task for autonomous systems in many domains, has been on the rise in recent years. With a multitude of new methods proposed by different communities, the lack of standardized benchmarks and objective comparisons is increasingly becoming a major limitation to assess progress and guide further research. Existing benchmarks are limited in their scope and flexibility to conduct relevant experiments and to account for contextual cues of agents and environments. In this paper we present Atlas, a benchmark to systematically evaluate human motion trajectory prediction algorithms in a unified framework. Atlas offers data preprocessing functions, hyperparameter optimization, comes with popular datasets and has the flexibility to setup and conduct underexplored yet relevant experiments to analyze a method's accuracy and robustness. In an example application of Atlas, we compare five popular model- and learning-based predictors and find that, when properly applied, early physics-based approaches are still remarkably competitive. Such results confirm the necessity of benchmarks like Atlas.
Cross-Modal Analysis of Human Detection for Robotics: An Industrial Case Study
Aug 03, 2021
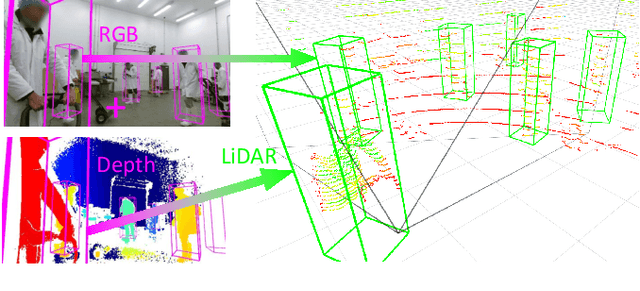
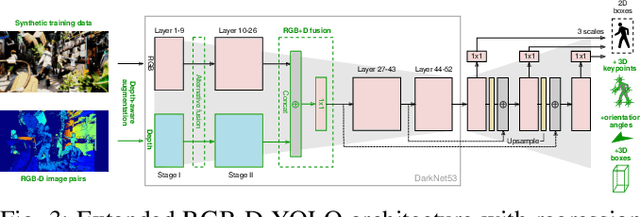
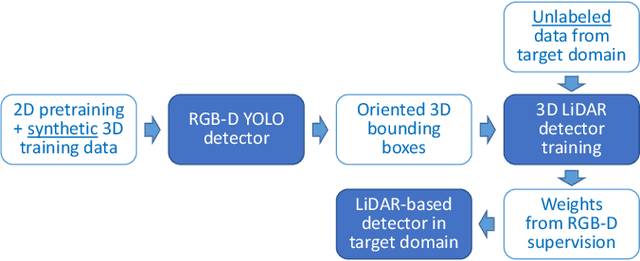
Advances in sensing and learning algorithms have led to increasingly mature solutions for human detection by robots, particularly in selected use-cases such as pedestrian detection for self-driving cars or close-range person detection in consumer settings. Despite this progress, the simple question "which sensor-algorithm combination is best suited for a person detection task at hand?" remains hard to answer. In this paper, we tackle this issue by conducting a systematic cross-modal analysis of sensor-algorithm combinations typically used in robotics. We compare the performance of state-of-the-art person detectors for 2D range data, 3D lidar, and RGB-D data as well as selected combinations thereof in a challenging industrial use-case. We further address the related problems of data scarcity in the industrial target domain, and that recent research on human detection in 3D point clouds has mostly focused on autonomous driving scenarios. To leverage these methodological advances for robotics applications, we utilize a simple, yet effective multi-sensor transfer learning strategy by extending a strong image-based RGB-D detector to provide cross-modal supervision for lidar detectors in the form of weak 3D bounding box labels. Our results show a large variance among the different approaches in terms of detection performance, generalization, frame rates and computational requirements. As our use-case contains difficulties representative for a wide range of service robot applications, we believe that these results point to relevant open challenges for further research and provide valuable support to practitioners for the design of their robot system.