 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSplat3D: Open-Vocabulary 3D Instance Segmentation using Gaussian Splatting
Jun 09, 2025
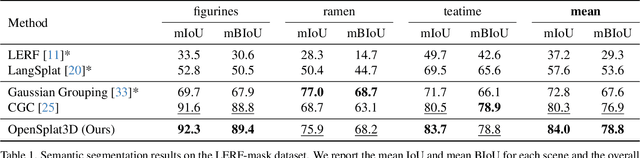

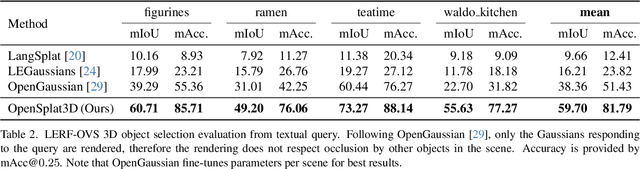
3D Gaussian Splatting (3DGS) has emerged as a powerful representation for neural scene reconstruction, offering high-quality novel view synthesis while maintaining computational efficiency. In this paper, we extend the capabilities of 3DGS beyond pure scene representation by introducing an approach for open-vocabulary 3D instance segmentation without requiring manual labeling, termed OpenSplat3D. Our method leverages feature-splatting techniques to associate semantic information with individual Gaussians, enabling fine-grained scene understanding. We incorporate Segment Anything Model instance masks with a contrastive loss formulation as guidance for the instance features to achieve accurate instance-level segmentation. Furthermore, we utilize language embeddings of a vision-language model, allowing for flexible, text-driven instance identification. This combination enables our system to identify and segment arbitrary objects in 3D scenes based on natural language descriptions. We show results on LERF-mask and LERF-OVS as well as the full ScanNet++ validation set, demonstrating the effectiveness of our approach.
GraphEQA: Using 3D Semantic Scene Graphs for Real-time Embodied Question Answering
Dec 19, 2024



In Embodied Question Answering (EQA), agents must explore and develop a semantic understanding of an unseen environment in order to answer a situated question with confidence. This remains a challenging problem in robotics, due to the difficulties in obtaining useful semantic representations, updating these representations online, and leveraging prior world knowledge for efficient exploration and planning. Aiming to address these limitations, we propose GraphEQA, a novel approach that utilizes real-time 3D metric-semantic scene graphs (3DSGs) and task relevant images as multi-modal memory for grounding Vision-Language Models (VLMs) to perform EQA tasks in unseen environments. We employ a hierarchical planning approach that exploits the hierarchical nature of 3DSGs for structured planning and semantic-guided exploration. Through experiments in simulation on the HM-EQA dataset and in the real world in home and office environments, we demonstrate that our method outperforms key baselines by completing EQA tasks with higher success rates and fewer planning steps.
RelationField: Relate Anything in Radiance Fields
Dec 18, 2024



Neural radiance fields are an emerging 3D scene representation and recently even been extended to learn features for scene understanding by distilling open-vocabulary features from vision-language models. However, current method primarily focus on object-centric representations, supporting object segmentation or detection, while understanding semantic relationships between objects remains largely unexplored. To address this gap, we propose RelationField, the first method to extract inter-object relationships directly from neural radiance fields. RelationField represents relationships between objects as pairs of rays within a neural radiance field, effectively extending its formulation to include implicit relationship queries. To teach RelationField complex, open-vocabulary relationships, relationship knowledge is distilled from multi-modal LLMs. To evaluate RelationField, we solve open-vocabulary 3D scene graph generation tasks and relationship-guided instance segmentation, achieving state-of-the-art performance in both tasks. See the project website at https://relationfield.github.io.
The Surprising Ineffectiveness of Pre-Trained Visual Representations for Model-Based Reinforcement Learning
Nov 15, 2024
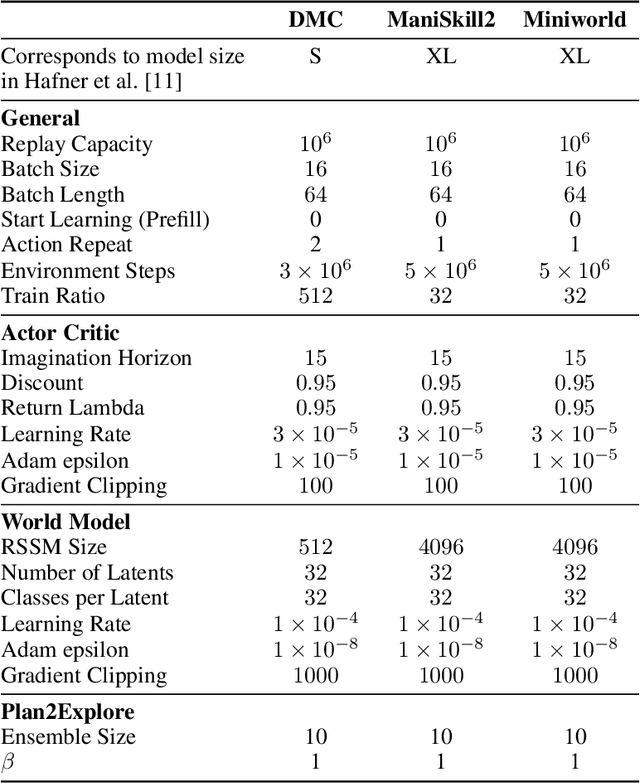

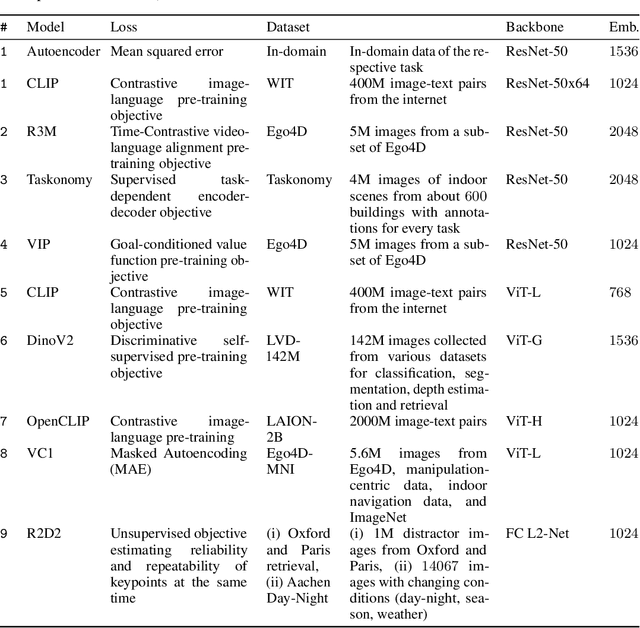
Visual Reinforcement Learning (RL) methods often require extensive amounts of data. As opposed to model-free RL, model-based RL (MBRL) offers a potential solution with efficient data utilization through planning. Additionally, RL lacks generalization capabilities for real-world tasks. Prior work has shown that incorporating pre-trained visual representations (PVRs) enhances sample efficiency and generalization. While PVRs have been extensively studied in the context of model-free RL, their potential in MBRL remains largely unexplored. In this paper, we benchmark a set of PVRs on challenging control tasks in a model-based RL setting. We investigate the data efficiency, generalization capabilities, and the impact of different properties of PVRs on the performance of model-based agents. Our results, perhaps surprisingly, reveal that for MBRL current PVRs are not more sample efficient than learning representations from scratch, and that they do not generalize better to out-of-distribution (OOD) settings. To explain this, we analyze the quality of the trained dynamics model. Furthermore, we show that data diversity and network architecture are the most important contributors to OOD generalization performance.
Open3DSG: Open-Vocabulary 3D Scene Graphs from Point Clouds with Queryable Objects and Open-Set Relationships
Feb 19, 2024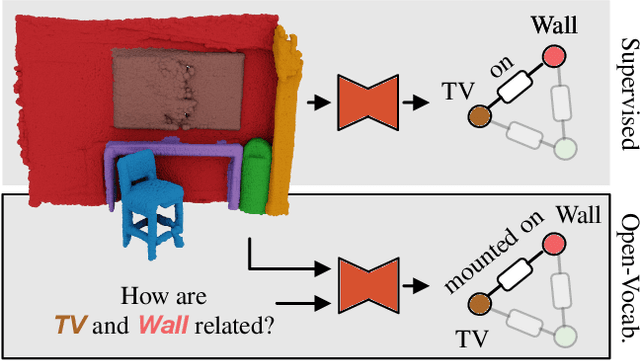



Current approaches for 3D scene graph prediction rely on labeled datasets to train models for a fixed set of known object classes and relationship categories. We present Open3DSG, an alternative approach to learn 3D scene graph prediction in an open world without requiring labeled scene graph data. We co-embed the features from a 3D scene graph prediction backbone with the feature space of powerful open world 2D vision language foundation models. This enables us to predict 3D scene graphs from 3D point clouds in a zero-shot manner by querying object classes from an open vocabulary and predicting the inter-object relationships from a grounded LLM with scene graph features and queried object classes as context. Open3DSG is the first 3D point cloud method to predict not only explicit open-vocabulary object classes, but also open-set relationships that are not limited to a predefined label set, making it possible to express rare as well as specific objects and relationships in the predicted 3D scene graph. Our experiments show that Open3DSG is effective at predicting arbitrary object classes as well as their complex inter-object relationships describing spatial, supportive, semantic and comparative relationships.
Lang3DSG: Language-based contrastive pre-training for 3D Scene Graph prediction
Oct 25, 2023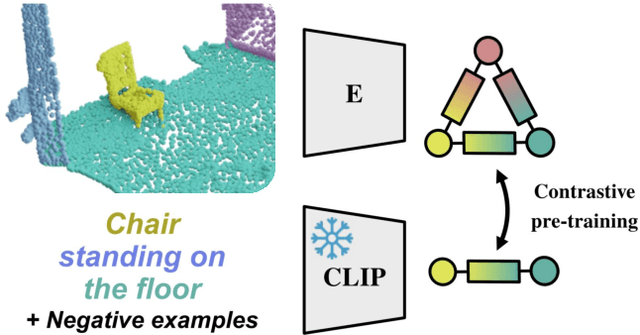


D scene graphs are an emerging 3D scene representation, that models both the objects present in the scene as well as their relationships. However, learning 3D scene graphs is a challenging task because it requires not only object labels but also relationship annotations, which are very scarce in datasets. While it is widely accepted that pre-training is an effective approach to improve model performance in low data regimes, in this paper, we find that existing pre-training methods are ill-suited for 3D scene graphs. To solve this issue, we present the first language-based pre-training approach for 3D scene graphs, whereby we exploit the strong relationship between scene graphs and language. To this end, we leverage the language encoder of CLIP, a popular vision-language model, to distill its knowledge into our graph-based network. We formulate a contrastive pre-training, which aligns text embeddings of relationships (subject-predicate-object triplets) and predicted 3D graph features. Our method achieves state-of-the-art results on the main semantic 3D scene graph benchmark by showing improved effectiveness over pre-training baselines and outperforming all the existing fully supervised scene graph prediction methods by a significant margin. Furthermore, since our scene graph features are language-aligned, it allows us to query the language space of the features in a zero-shot manner. In this paper, we show an example of utilizing this property of the features to predict the room type of a scene without further training.
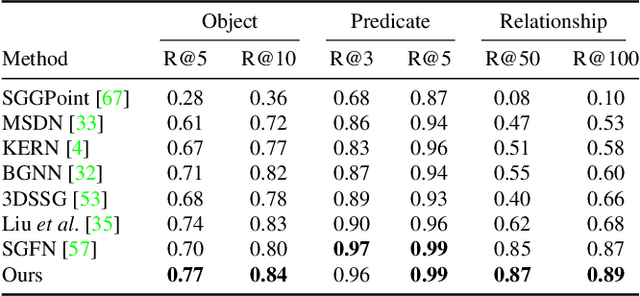
SGRec3D: Self-Supervised 3D Scene Graph Learning via Object-Level Scene Reconstruction
Sep 27, 2023



In the field of 3D scene understanding, 3D scene graphs have emerged as a new scene representation that combines geometric and semantic information about objects and their relationships. However, learning semantic 3D scene graphs in a fully supervised manner is inherently difficult as it requires not only object-level annotations but also relationship labels. While pre-training approaches have helped to boost the performance of many methods in various fields, pre-training for 3D scene graph prediction has received little attention. Furthermore, we find in this paper that classical contrastive point cloud-based pre-training approaches are ineffective for 3D scene graph learning. To this end, we present SGRec3D, a novel self-supervised pre-training method for 3D scene graph prediction. We propose to reconstruct the 3D input scene from a graph bottleneck as a pretext task. Pre-training SGRec3D does not require object relationship labels, making it possible to exploit large-scale 3D scene understanding datasets, which were off-limits for 3D scene graph learning before. Our experiments demonstrate that in contrast to recent point cloud-based pre-training approaches, our proposed pre-training improves the 3D scene graph prediction considerably, which results in SOTA performance, outperforming other 3D scene graph models by +10% on object prediction and +4% on relationship prediction. Additionally, we show that only using a small subset of 10% labeled data during fine-tuning is sufficient to outperform the same model without pre-training.
Predicting Dense and Context-aware Cost Maps for Semantic Robot Navigation
Oct 17, 2022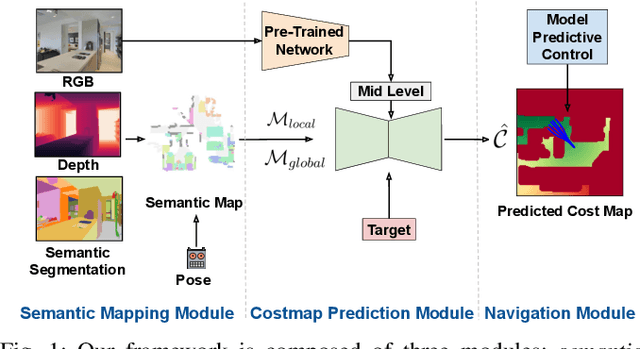
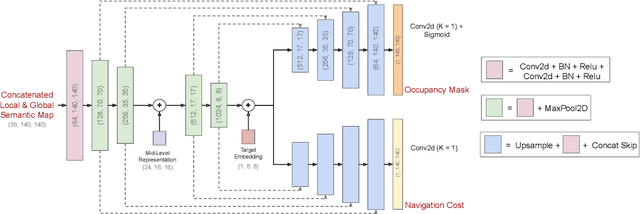
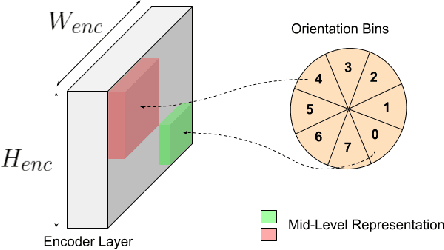
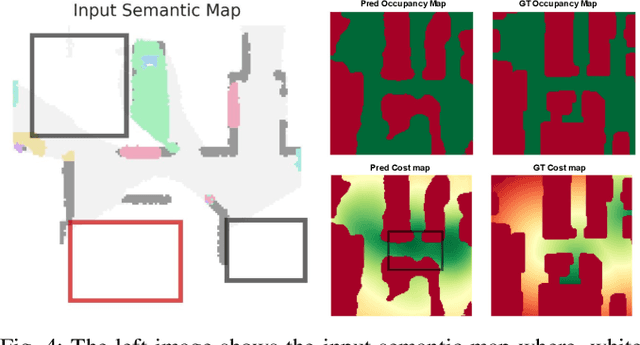
We investigate the task of object goal navigation in unknown environments where the target is specified by a semantic label (e.g. find a couch). Such a navigation task is especially challenging as it requires understanding of semantic context in diverse settings. Most of the prior work tackles this problem under the assumption of a discrete action policy whereas we present an approach with continuous control which brings it closer to real world applications. We propose a deep neural network architecture and loss function to predict dense cost maps that implicitly contain semantic context and guide the robot towards the semantic goal. We also present a novel way of fusing mid-level visual representations in our architecture to provide additional semantic cues for cost map prediction. The estimated cost maps are then used by a sampling-based model predictive controller (MPC) for generating continuous robot actions. The preliminary experiments suggest that the cost maps generated by our network are suitable for the MPC and can guide the agent to the semantic goal more efficiently than a baseline approach. The results also indicate the importance of mid-level representations for navigation by improving the success rate by 7 percentage points.
Cross-Modal Analysis of Human Detection for Robotics: An Industrial Case Study
Aug 03, 2021
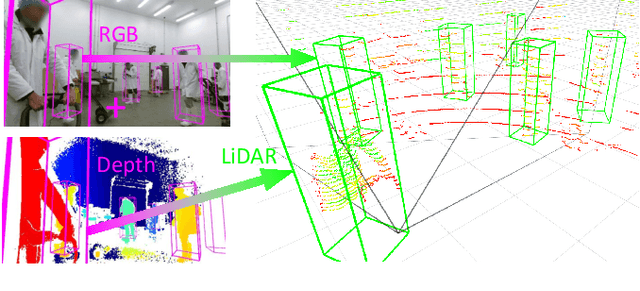
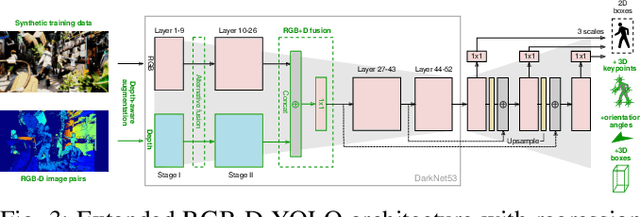
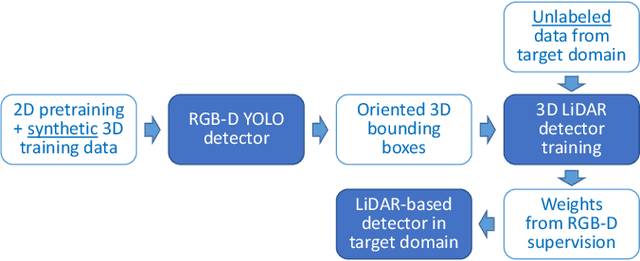
Advances in sensing and learning algorithms have led to increasingly mature solutions for human detection by robots, particularly in selected use-cases such as pedestrian detection for self-driving cars or close-range person detection in consumer settings. Despite this progress, the simple question "which sensor-algorithm combination is best suited for a person detection task at hand?" remains hard to answer. In this paper, we tackle this issue by conducting a systematic cross-modal analysis of sensor-algorithm combinations typically used in robotics. We compare the performance of state-of-the-art person detectors for 2D range data, 3D lidar, and RGB-D data as well as selected combinations thereof in a challenging industrial use-case. We further address the related problems of data scarcity in the industrial target domain, and that recent research on human detection in 3D point clouds has mostly focused on autonomous driving scenarios. To leverage these methodological advances for robotics applications, we utilize a simple, yet effective multi-sensor transfer learning strategy by extending a strong image-based RGB-D detector to provide cross-modal supervision for lidar detectors in the form of weak 3D bounding box labels. Our results show a large variance among the different approaches in terms of detection performance, generalization, frame rates and computational requirements. As our use-case contains difficulties representative for a wide range of service robot applications, we believe that these results point to relevant open challenges for further research and provide valuable support to practitioners for the design of their robot system.
Knowledge-Enabled Robotic Agents for Shelf Replenishment in Cluttered Retail Environments
May 13, 2016
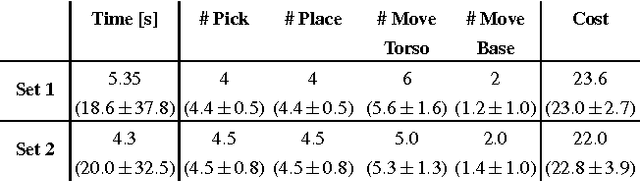
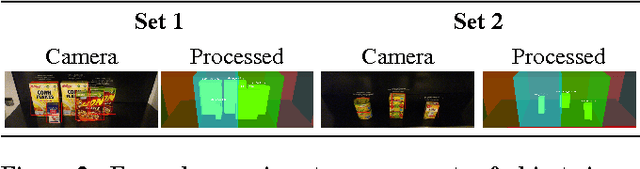
Autonomous robots in unstructured and dynamically changing retail environments have to master complex perception, knowledgeprocessing, and manipulation tasks. To enable them to act competently, we propose a framework based on three core components: (o) a knowledge-enabled perception system, capable of combining diverse information sources to cope with occlusions and stacked objects with a variety of textures and shapes, (o) knowledge processing methods produce strategies for tidying up supermarket racks, and (o) the necessary manipulation skills in confined spaces to arrange objects in semi-accessible rack shelves. We demonstrate our framework in an simulated environment as well as on a real shopping rack using a PR2 robot. Typical supermarket products are detected and rearranged in the retail rack, tidying up what was found to be misplaced items.
* published in the proceedings of AAMAS 2016 as an extended abstract