 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multi-Object-Tracking with Radar on a Fast Moving Vehicle: On the Potential of Processing Radar in the Frequency Domain
Apr 15, 2026We promote in this paper the processing of radar data in the frequency domain to achieve higher robustness against noise and structural errors, especially in comparison to feature-based methods. This holds also for high dynamics in the scene, i.e., ego-motion of the vehicle with the sensor plus the presence of an unknown number of other moving objects. In addition to the high robustness, the processing in the frequency domain has the so far neglected advantage that the underlying correlation based methods used for, e.g., registration, provide information about all moving structures in the scene. A typical automotive application case is overtaking maneuvers, which in the context of autonomous racing are used here as a motivating example. Initial experiments and results with Fourier SOFT in 2D (FS2D) are presented that use the Boreas dataset to demonstrate radar-only-odometry, i.e., radar-odometry without sensor-fusion, to support our arguments.
SmileyNet -- Towards the Prediction of the Lottery by Reading Tea Leaves with AI
Jul 31, 2024



We introduce SmileyNet, a novel neural network with psychic abilities. It is inspired by the fact that a positive mood can lead to improved cognitive capabilities including classification tasks. The network is hence presented in a first phase with smileys and an encouraging loss function is defined to bias it into a good mood. SmileyNet is then used to forecast the flipping of a coin based on an established method of Tasseology, namely by reading tea leaves. Training and testing in this second phase are done with a high-fidelity simulation based on real-world pixels sampled from a professional tea-reading cup. SmileyNet has an amazing accuracy of 72% to correctly predict the flip of a coin. Resnet-34, respectively YOLOv5 achieve only 49%, respectively 53%. It is then shown how multiple SmileyNets can be combined to win the lottery.
From Multi-modal Property Dataset to Robot-centric Conceptual Knowledge About Household Objects
Jun 26, 2019
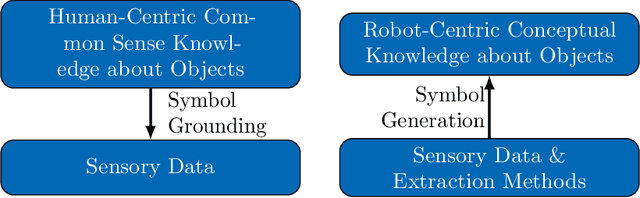
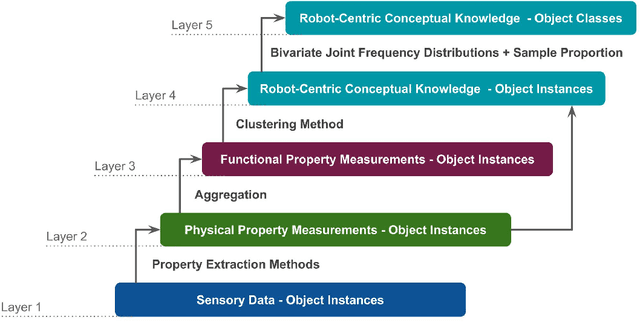
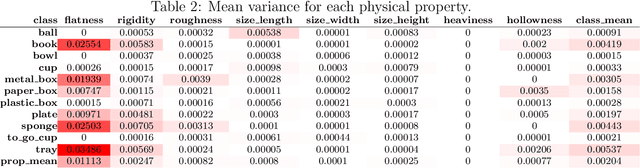
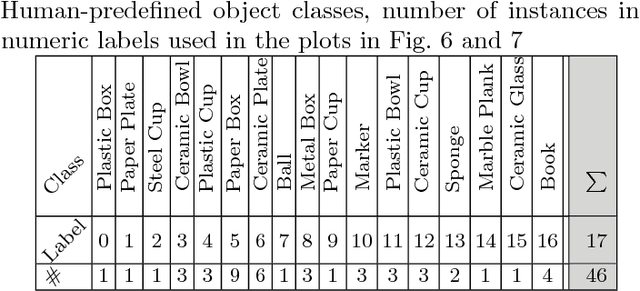
Tool-use applications in robotics require conceptual knowledge about objects for informed decision making and object interactions. State-of-the-art methods employ hand-crafted symbolic knowledge which is defined from a human perspective and grounded into sensory data afterwards. However, due to different sensing and acting capabilities of robots, their conceptual understanding of objects must be generated from a robot's perspective entirely, which asks for robot-centric conceptual knowledge about objects. With this goal in mind, this article motivates that such knowledge should be based on physical and functional properties of objects. Consequently, a selection of ten properties is defined and corresponding extraction methods are proposed. This multi-modal property extraction forms the basis on which our second contribution, a robot-centric knowledge generation is build on. It employs unsupervised clustering methods to transform numerical property data into symbols, and Bivariate Joint Frequency Distributions and Sample Proportion to generate conceptual knowledge about objects using the robot-centric symbols. A preliminary implementation of the proposed framework is employed to acquire a dataset comprising physical and functional property data of 110 houshold objects. This Robot-Centric dataSet (RoCS) is used to evaluate the framework regarding the property extraction methods, the semantics of the considered properties within the dataset and its usefulness in real-world applications such as tool substitution.
Adaptive Navigation Scheme for Optimal Deep-Sea Localization Using Multimodal Perception Cues
Jun 12, 2019
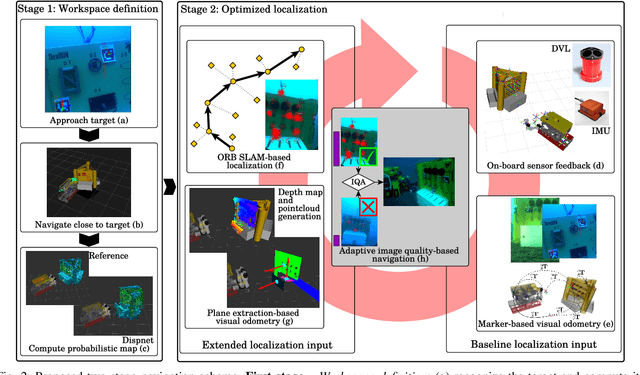
Underwater robot interventions require a high level of safety and reliability. A major challenge to address is a robust and accurate acquisition of localization estimates, as it is a prerequisite to enable more complex tasks, e.g. floating manipulation and mapping. State-of-the-art navigation in commercial operations, such as oil & gas production (OGP), rely on costly instrumentation. These can be partially replaced or assisted by visual navigation methods, especially in deep-sea scenarios where equipment deployment has high costs and risks. Our work presents a multimodal approach that adapts state-of-the-art methods from on-land robotics, i.e., dense point cloud generation in combination with plane representation and registration, to boost underwater localization performance. A two-stage navigation scheme is proposed that initially generates a coarse probabilistic map of the workspace, which is used to filter noise from computed point clouds and planes in the second stage. Furthermore, an adaptive decision-making approach is introduced that determines which perception cues to incorporate into the localization filter to optimize accuracy and computation performance. Our approach is investigated first in simulation and then validated with data from field trials in OGP monitoring and maintenance scenarios.
Improved Fourier Mellin Invariant for Robust Rotation Estimation with Omni-cameras
Feb 12, 2019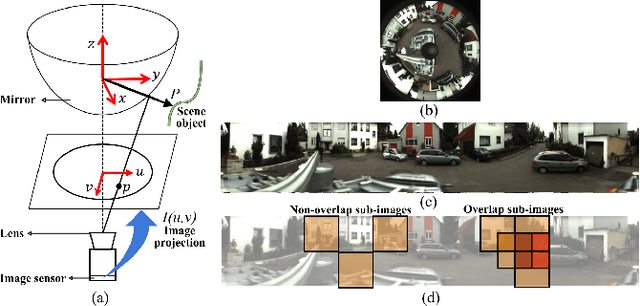
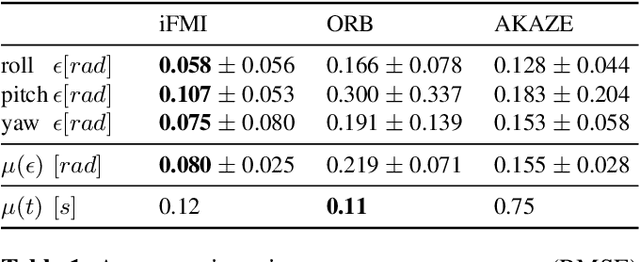


Spectral methods such as the improved Fourier Mellin Invariant (iFMI) transform have proved faster, more robust and accurate than feature based methods on image registration. However, iFMI is restricted to work only when the camera moves in 2D space and has not been applied on omni-cameras images so far. In this work, we extend the iFMI method and apply a motion model to estimate an omni-camera's pose when it moves in 3D space. This is particularly useful in field robotics applications to get a rapid and comprehensive view of unstructured environments, and to estimate robustly the robot pose. In the experiment section, we compared the extended iFMI method against ORB and AKAZE feature based approaches on three datasets showing different type of environments: office, lawn and urban scenery (MPI-omni dataset). The results show that our method boosts the accuracy of the robot pose estimation two to four times with respect to the feature registration techniques, while offering lower processing times. Furthermore, the iFMI approach presents the best performance against motion blur typically present in mobile robotics.
Conceptualization of Object Compositions Using Persistent Homology
Nov 20, 2018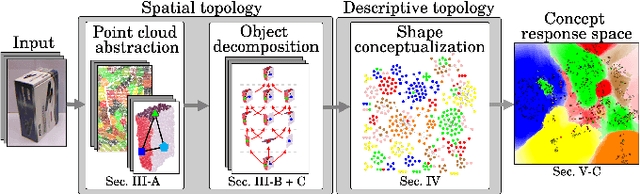
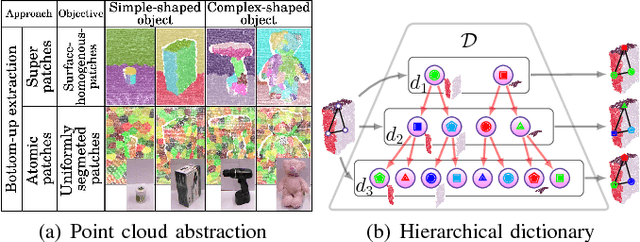
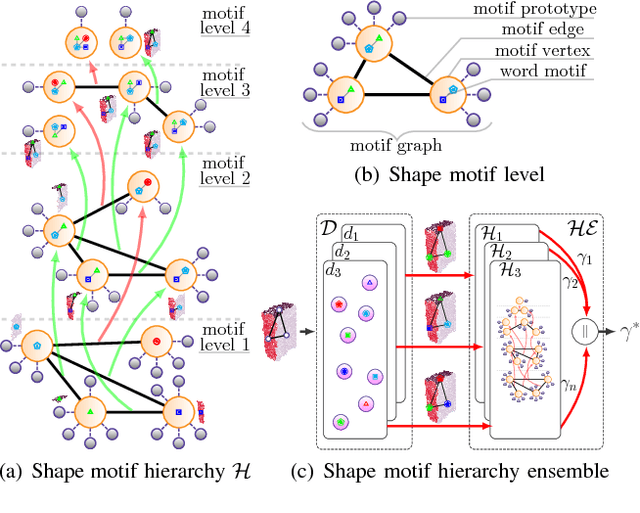

A topological shape analysis is proposed and utilized to learn concepts that reflect shape commonalities. Our approach is two-fold: i) a spatial topology analysis of point cloud segment constellations within objects. Therein constellations are decomposed and described in an hierarchical manner - from single segments to segment groups until a single group reflects an entire object. ii) a topology analysis of the description space in which segment decompositions are exposed in. Inspired by Persistent Homology, hidden groups of shape commonalities are revealed from object segment decompositions. Experiments show that extracted persistent groups of commonalities can represent semantically meaningful shape concepts. We also show the generalization capability of the proposed approach considering samples of external datasets.
Unsupervised Learning of Shape Concepts - From Real-World Objects to Mental Simulation
Nov 20, 2018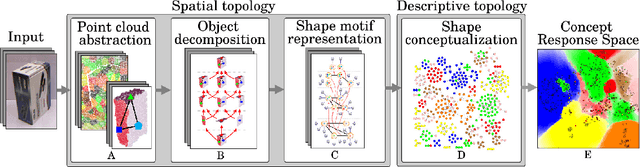
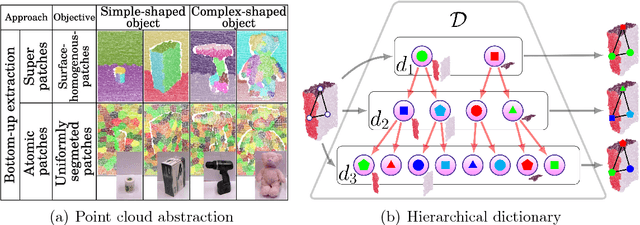
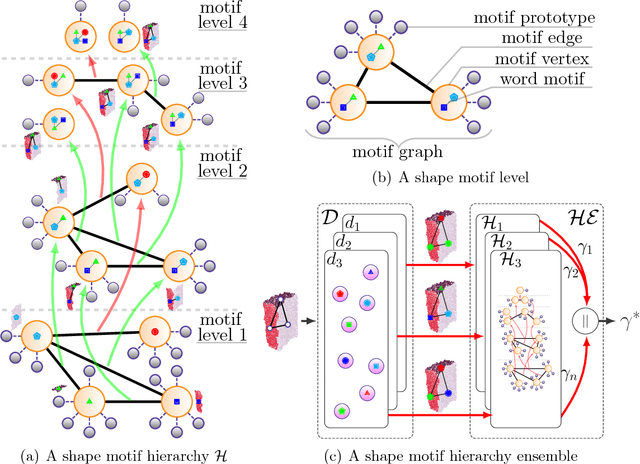
An unsupervised shape analysis is proposed to learn concepts reflecting shape commonalities. Our approach is two-fold: i) a spatial topology analysis of point cloud segment constellations within objects is used in which constellations are decomposed and described in a hierarchical and symbolic manner. ii) A topology analysis of the description space is used in which segment decompositions are exposed in. Inspired by Persistent Homology, groups of shape commonality are revealed. Experiments show that extracted persistent commonality groups can feature semantically meaningful shape concepts; the generalization of the proposed approach is evaluated by different real-world datasets. We extend this by not only learning shape concepts using real-world data, but by also using mental simulation of artificial abstract objects for training purposes. This extended approach is unsupervised in two respects: label-agnostic (no label information is used) and instance-agnostic (no instances preselected by human supervision are used for training). Experiments show that concepts generated with mental simulation, generalize and discriminate real object observations. Consequently, a robot may train and learn its own internal representation of concepts regarding shape appearance in a self-driven and machine-centric manner while omitting the tedious process of supervised dataset generation including the ambiguity in instance labeling and selection.
Robust Gesture-Based Communication for Underwater Human-Robot Interaction in the context of Search and Rescue Diver Missions
Oct 16, 2018
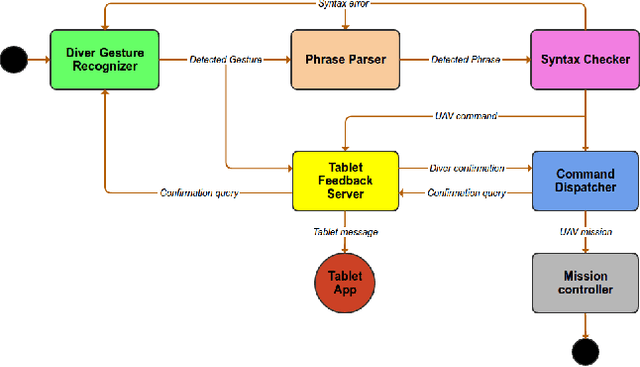
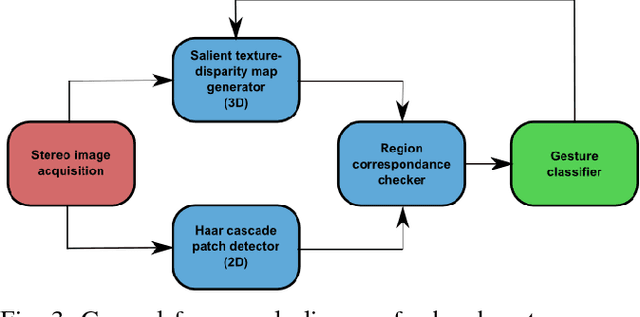
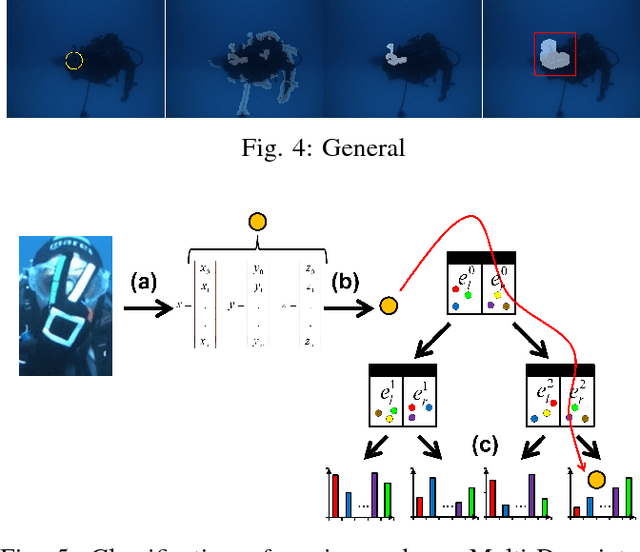
We propose a robust gesture-based communication pipeline for divers to instruct an Autonomous Underwater Vehicle (AUV) to assist them in performing high-risk tasks and helping in case of emergency. A gesture communication language (CADDIAN) is developed, based on consolidated and standardized diver gestures, including an alphabet, syntax and semantics, ensuring a logical consistency. A hierarchical classification approach is introduced for hand gesture recognition based on stereo imagery and multi-descriptor aggregation to specifically cope with underwater image artifacts, e.g. light backscatter or color attenuation. Once the classification task is finished, a syntax check is performed to filter out invalid command sequences sent by the diver or generated by errors in the classifier. Throughout this process, the diver receives constant feedback from an underwater tablet to acknowledge or abort the mission at any time. The objective is to prevent the AUV from executing unnecessary, infeasible or potentially harmful motions. Experimental results under different environmental conditions in archaeological exploration and bridge inspection applications show that the system performs well in the field.
Towards Robot-Centric Conceptual Knowledge Acquisition
Oct 08, 2018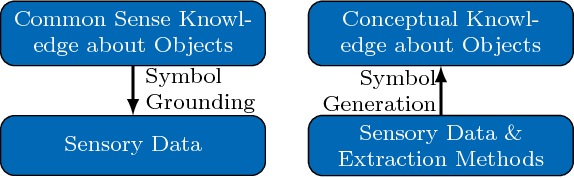
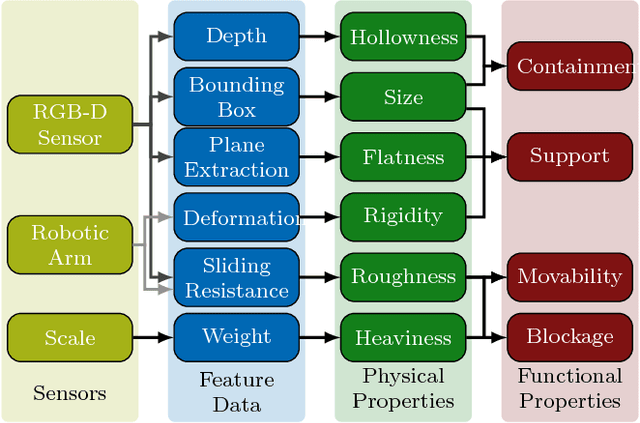
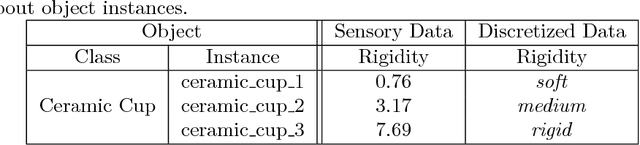
Robots require knowledge about objects in order to efficiently perform various household tasks involving objects. The existing knowledge bases for robots acquire symbolic knowledge about objects from manually-coded external common sense knowledge bases such as ConceptNet, Word-Net etc. The problem with such approaches is the discrepancy between human-centric symbolic knowledge and robot-centric object perception due to its limited perception capabilities. Ultimately, significant portion of knowledge in the knowledge base remains ungrounded into robot's perception. To overcome this discrepancy, we propose an approach to enable robots to generate robot-centric symbolic knowledge about objects from their own sensory data, thus, allowing them to assemble their own conceptual understanding of objects. With this goal in mind, the presented paper elaborates on the work-in-progress of the proposed approach followed by the preliminary results.
Robust Continuous System Integration for Critical Deep-Sea Robot Operations Using Knowledge-Enabled Simulation in the Loop
Jul 18, 2018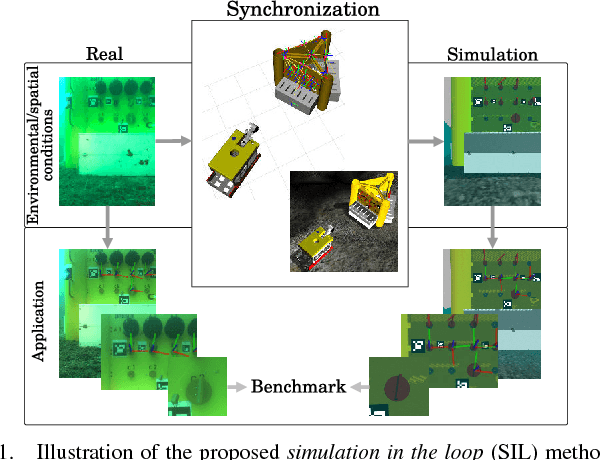
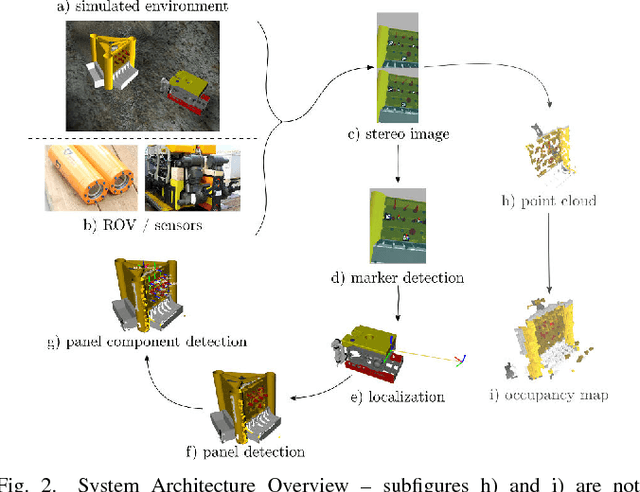
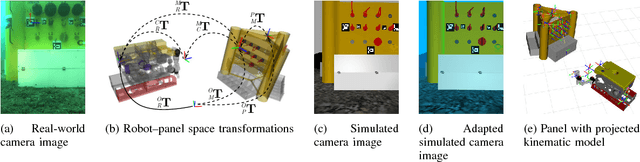
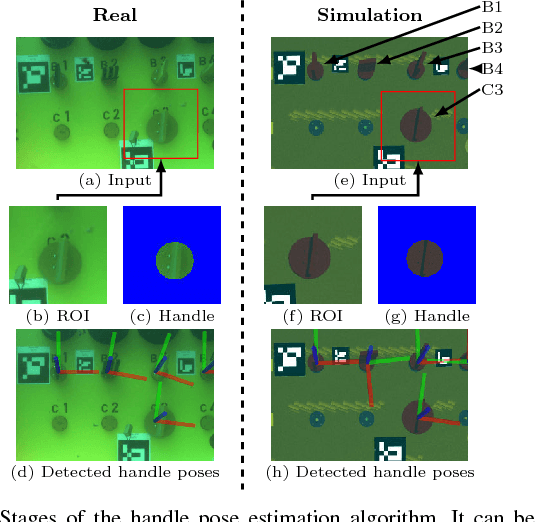
Deep-sea robot operations demand a high level of safety, efficiency and reliability. As a consequence, measures within the development stage have to be implemented to extensively evaluate and benchmark system components ranging from data acquisition, perception and localization to control. We present an approach based on high-fidelity simulation that embeds spatial and environmental conditions from recorded real-world data. This simulation in the loop (SIL) methodology allows for mitigating the discrepancy between simulation and real-world conditions, e.g. regarding sensor noise. As a result, this work provides a platform to thoroughly investigate and benchmark behaviors of system components concurrently under real and simulated conditions. The conducted evaluation shows the benefit of the proposed work in tasks related to perception and self-localization under changing spatial and environmental conditions.
* published on IROS 2018