 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayful DoggyBot: Learning Agile and Precise Quadrupedal Locomotion
Sep 30, 2024Quadrupedal animals have the ability to perform agile while accurate tasks: a trained dog can chase and catch a flying frisbee before it touches the ground; a cat alone at home can jump and grab the door handle accurately. However, agility and precision are usually a trade-off in robotics problems. Recent works in quadruped robots either focus on agile but not-so-accurate tasks, such as locomotion in challenging terrain, or accurate but not-so-fast tasks, such as using an additional manipulator to interact with objects. In this work, we aim at an accurate and agile task, catching a small object hanging above the robot. We mount a passive gripper in front of the robot chassis, so that the robot has to jump and catch the object with extreme precision. Our experiment shows that our system is able to jump and successfully catch the ball at 1.05m high in simulation and 0.8m high in the real world, while the robot is 0.3m high when standing.
Robot Parkour Learning
Sep 12, 2023



Parkour is a grand challenge for legged locomotion that requires robots to overcome various obstacles rapidly in complex environments. Existing methods can generate either diverse but blind locomotion skills or vision-based but specialized skills by using reference animal data or complex rewards. However, autonomous parkour requires robots to learn generalizable skills that are both vision-based and diverse to perceive and react to various scenarios. In this work, we propose a system for learning a single end-to-end vision-based parkour policy of diverse parkour skills using a simple reward without any reference motion data. We develop a reinforcement learning method inspired by direct collocation to generate parkour skills, including climbing over high obstacles, leaping over large gaps, crawling beneath low barriers, squeezing through thin slits, and running. We distill these skills into a single vision-based parkour policy and transfer it to a quadrupedal robot using its egocentric depth camera. We demonstrate that our system can empower two different low-cost robots to autonomously select and execute appropriate parkour skills to traverse challenging real-world environments.
osmAG: Hierarchical Semantic Topometric Area Graph Maps in the OSM Format for Mobile Robotics
Sep 09, 2023Maps are essential to mobile robotics tasks like localization and planning. We propose the open street map (osm) XML based Area Graph file format to store hierarchical, topometric semantic multi-floor maps of indoor and outdoor environments, since currently no such format is popular within the robotics community. Building on-top of osm we leverage the available open source editing tools and libraries of osm, while adding the needed mobile robotics aspect with building-level obstacle representation yet very compact, topometric data that facilitates planning algorithms. Through the use of common osm keys as well as custom ones we leverage the power of semantic annotation to enable various applications. For example, we support planning based on robot capabilities, to take the locomotion mode and attributes in conjunction with the environment information into account. The provided C++ library is integrated into ROS. We evaluate the performance of osmAG using real data in a global path planning application on a very big osmAG map, demonstrating its convenience and effectiveness for mobile robots.
Improved Fourier Mellin Invariant for Robust Rotation Estimation with Omni-cameras
Feb 12, 2019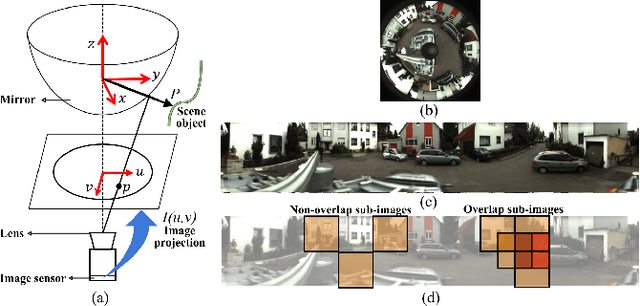
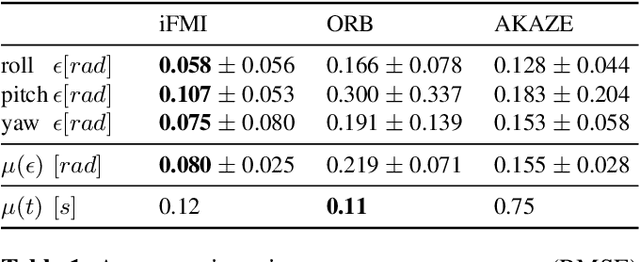


Spectral methods such as the improved Fourier Mellin Invariant (iFMI) transform have proved faster, more robust and accurate than feature based methods on image registration. However, iFMI is restricted to work only when the camera moves in 2D space and has not been applied on omni-cameras images so far. In this work, we extend the iFMI method and apply a motion model to estimate an omni-camera's pose when it moves in 3D space. This is particularly useful in field robotics applications to get a rapid and comprehensive view of unstructured environments, and to estimate robustly the robot pose. In the experiment section, we compared the extended iFMI method against ORB and AKAZE feature based approaches on three datasets showing different type of environments: office, lawn and urban scenery (MPI-omni dataset). The results show that our method boosts the accuracy of the robot pose estimation two to four times with respect to the feature registration techniques, while offering lower processing times. Furthermore, the iFMI approach presents the best performance against motion blur typically present in mobile robotics.