 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextFlow: Hierarchical Task-State Alignment for Long-Horizon Embodied Agents
May 19, 2026Long-horizon embodied agents increasingly delegate navigation, search, approach, and manipulation to specialist executors. As these executors become stronger, the main bottleneck shifts from local skill execution to maintaining a coherent task frontier across planning, monitoring, memory, and execution. We study task-state misalignment, a task-level consistency failure in which the planner's active stage, runtime evidence, remembered context, and delegated executor no longer justify the same next-step decision. This failure can lead to unsupported handoffs, stage lock, executor-context mismatch, and unnecessary replanning. We propose ContextFlow, an inspectable alignment framework that represents stages as explicit contracts, converts runtime observations into evidence packets, and applies scoped updates including continue, refine, transfer, promote, and repair. ContextFlow keeps specialist executors responsible for local closed-loop control while making task-frontier alignment explicit and auditable. Experiments and demonstration traces on long-horizon embodied tasks illustrate how evidence-grounded scoped updates diagnose and mitigate recurring task-state failures.
From Instance Selection to Fixed-Pool Data Recipe Search for Supervised Fine-Tuning
May 13, 2026Supervised fine-tuning (SFT) data selection is commonly formulated as instance ranking: score each example and retain a top-$k$ subset. However, effective SFT training subsets are often produced through ordered curation recipes, where filtering, mixing, and deduplication operators jointly shape the final data distribution. We formulate this problem as fixed-pool data recipe search: given a raw instruction pool and a library of grounded operators, the goal is to discover an executable recipe that constructs a high-quality selected subset under a limited budget of full SFT evaluations, without generating, rewriting, or augmenting training samples. We introduce AutoSelection, a two-layer solver that decouples fixed-pool materialization based on cached task-, data-, and model-side signals from expensive full evaluation, using warmup probes, realized subset states, local recipe edits, Gaussian-process-assisted ranking, and stagnation-triggered reseeding. Experiments on a 90K instruction pool show that AutoSelection achieves the strongest in-distribution reasoning average across three base models, outperforming full-data training, random recipe search, random top-$k$, and single-operator selectors. Additional Out-of-distribution graph-reasoning results, search-stability analyses, structural ablations, and 1.5B-to-7B transfer checks further show that recipe structure matters beyond individual selection operators. Code is available at https://github.com/w253/AutoSelection.
Rethinking Token-Level Credit Assignment in RLVR: A Polarity-Entropy Analysis
Apr 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has substantially improved the reasoning ability of Large Language Models (LLMs). However, its sparse outcome-based rewards pose a fundamental credit assignment problem. We analyze this problem through the joint lens of reward polarity and token entropy. Our diagnostic tool, the Four Quadrant Decomposition, isolates token updates by polarity and entropy, and controlled ablations show that reasoning improvements concentrate in the high-entropy quadrants. To justify this observation theoretically, we adapt Conditional Mutual Information to the autoregressive RLVR setting and prove that the credit a token can carry is upper-bounded by its entropy. This view yields testable predictions that reasoning gains arise primarily from high-entropy tokens, with unique roles for positive and negative updates. A gradient analysis of GRPO further reveals how uniform reward broadcast dilutes signal at high-entropy positions while over-crediting deterministic tokens. Grounded in these insights, we propose Entropy-Aware Policy Optimization (EAPO) that modulates token-level learning signals accordingly. Extensive experiments demonstrate that EAPO outperforms strong baselines across two model families.
osmAG-Nav: A Hierarchical Semantic Topometric Navigation Stack for Robust Lifelong Indoor Autonomy
Mar 30, 2026The deployment of mobile robots in large-scale, multi-floor environments demands navigation systems that achieve spatial scalability without compromising local kinematic precision. Traditional navigation stacks, reliant on monolithic occupancy grid maps, face severe bottlenecks in storage efficiency, cross-floor reasoning, and long-horizon planning. To address these limitations, this paper presents osmAG-Nav, a complete, open-source ROS2 navigation stack built upon the hierarchical semantic topometric OpenStreetMap Area Graph (osmAG) map standard. The system follows a "System of Systems" architecture that decouples global topological reasoning from local metric execution. A Hierarchical osmAG planner replaces dense grid searches with an LCA-anchored pipeline on a passage-centric graph whose edge costs derive from local raster traversability rather than Euclidean distance, yielding low-millisecond planning on long campus-scale routes. A Rolling Window mechanism rasterizes a fixed-size local metric grid around the robot, keeping the local costmap memory footprint independent of the total mapped area, while a Segmented Execution strategy dispatches intermediate goals to standard ROS2 controllers for smooth handoffs. System robustness is reinforced by a structure-aware LiDAR localization framework that filters dynamic clutter against permanent architectural priors. Extensive experiments on a real-world multi-story indoor-outdoor campus (>11,025 m^2) show that, on the same-floor benchmark subset, osmAG-Nav delivers up to 7816x lower planning latency than a grid-based baseline on long routes while maintaining low path-length overhead and lifelong localization stability. A single-floor long-range robot mission further validates the integrated stack reliability. The full stack is released as modular ROS2 Lifecycle Nodes.
Janus-Q: End-to-End Event-Driven Trading via Hierarchical-Gated Reward Modeling
Feb 23, 2026Financial market movements are often driven by discrete financial events conveyed through news, whose impacts are heterogeneous, abrupt, and difficult to capture under purely numerical prediction objectives. These limitations have motivated growing interest in using textual information as the primary source of trading signals in learning-based systems. Two key challenges hinder existing approaches: (1) the absence of large-scale, event-centric datasets that jointly model news semantics and statistically grounded market reactions, and (2) the misalignment between language model reasoning and financially valid trading behavior under dynamic market conditions. To address these challenges, we propose Janus-Q, an end-to-end event-driven trading framework that elevates financial news events from auxiliary signals to primary decision units. Janus-Q unifies event-centric data construction and model optimization under a two-stage paradigm. Stage I focuses on event-centric data construction, building a large-scale financial news event dataset comprising 62,400 articles annotated with 10 fine-grained event types, associated stocks, sentiment labels, and event-driven cumulative abnormal return (CAR). Stage II performs decision-oriented fine-tuning, combining supervised learning with reinforcement learning guided by a Hierarchical Gated Reward Model (HGRM), which explicitly captures trade-offs among multiple trading objectives. Extensive experiments demonstrate that Janus-Q achieves more consistent, interpretable, and profitable trading decisions than market indices and LLM baselines, improving the Sharpe Ratio by up to 102.0% while increasing direction accuracy by over 17.5% compared to the strongest competing strategies.
Mixture of Length and Pruning Experts for Knowledge Graphs Reasoning
Jul 28, 2025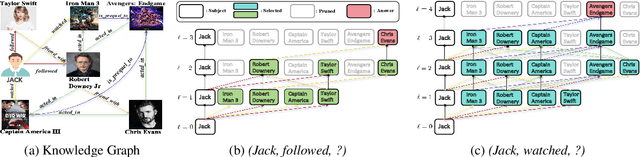
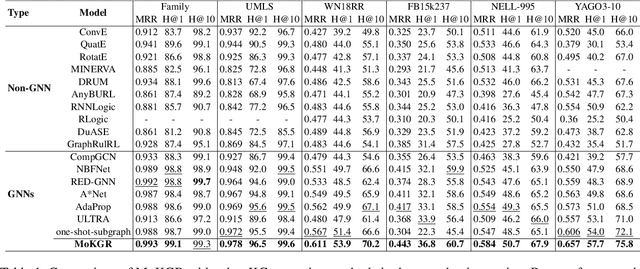
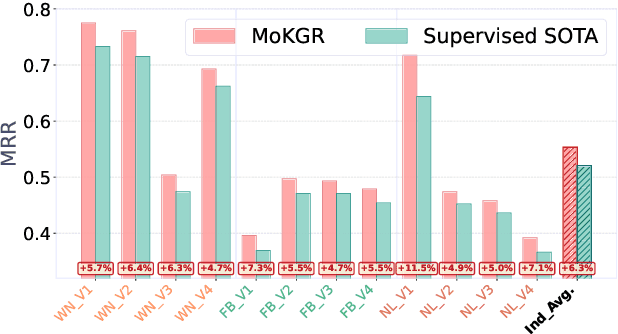
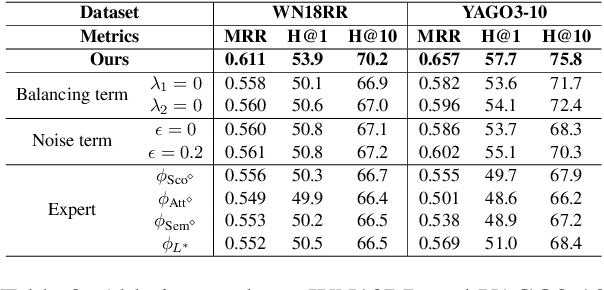
Knowledge Graph (KG) reasoning, which aims to infer new facts from structured knowledge repositories, plays a vital role in Natural Language Processing (NLP) systems. Its effectiveness critically depends on constructing informative and contextually relevant reasoning paths. However, existing graph neural networks (GNNs) often adopt rigid, query-agnostic path-exploration strategies, limiting their ability to adapt to diverse linguistic contexts and semantic nuances. To address these limitations, we propose \textbf{MoKGR}, a mixture-of-experts framework that personalizes path exploration through two complementary components: (1) a mixture of length experts that adaptively selects and weights candidate path lengths according to query complexity, providing query-specific reasoning depth; and (2) a mixture of pruning experts that evaluates candidate paths from a complementary perspective, retaining the most informative paths for each query. Through comprehensive experiments on diverse benchmark, MoKGR demonstrates superior performance in both transductive and inductive settings, validating the effectiveness of personalized path exploration in KGs reasoning.
Case-Based Reasoning Enhances the Predictive Power of LLMs in Drug-Drug Interaction
May 29, 2025Drug-drug interaction (DDI) prediction is critical for treatment safety. While large language models (LLMs) show promise in pharmaceutical tasks, their effectiveness in DDI prediction remains challenging. Inspired by the well-established clinical practice where physicians routinely reference similar historical cases to guide their decisions through case-based reasoning (CBR), we propose CBR-DDI, a novel framework that distills pharmacological principles from historical cases to improve LLM reasoning for DDI tasks. CBR-DDI constructs a knowledge repository by leveraging LLMs to extract pharmacological insights and graph neural networks (GNNs) to model drug associations. A hybrid retrieval mechanism and dual-layer knowledge-enhanced prompting allow LLMs to effectively retrieve and reuse relevant cases. We further introduce a representative sampling strategy for dynamic case refinement. Extensive experiments demonstrate that CBR-DDI achieves state-of-the-art performance, with a significant 28.7% accuracy improvement over both popular LLMs and CBR baseline, while maintaining high interpretability and flexibility.
GraphOracle: A Foundation Model for Knowledge Graph Reasoning
May 16, 2025
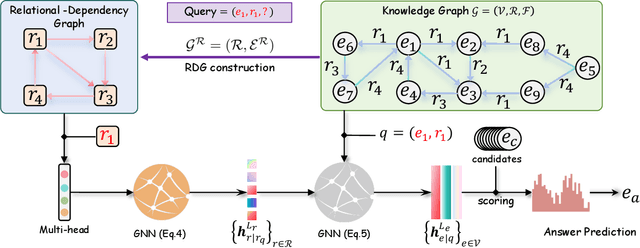
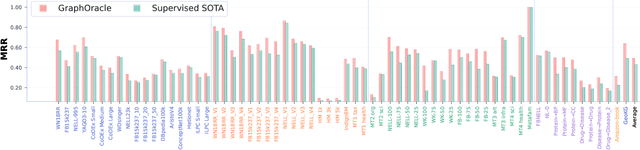

Foundation models have demonstrated remarkable capabilities across various domains, but developing analogous models for knowledge graphs presents unique challenges due to their dynamic nature and the need for cross-domain reasoning. To address these issues, we introduce \textbf{\textsc{GraphOracle}}, a relation-centric foundation model that unifies reasoning across knowledge graphs by converting them into Relation-Dependency Graphs (RDG), explicitly encoding compositional patterns with fewer edges than prior methods. A query-dependent attention mechanism is further developed to learn inductive representations for both relations and entities. Pre-training on diverse knowledge graphs, followed by minutes-level fine-tuning, enables effective generalization to unseen entities, relations, and entire graphs. Through comprehensive experiments on 31 diverse benchmarks spanning transductive, inductive, and cross-domain settings, we demonstrate consistent state-of-the-art performance with minimal adaptation, improving the prediction performance by up to 35\% compared to the strongest baselines.
An LLM-enabled Multi-Agent Autonomous Mechatronics Design Framework
Apr 20, 2025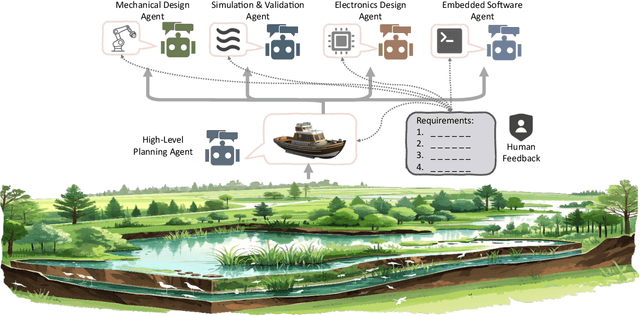

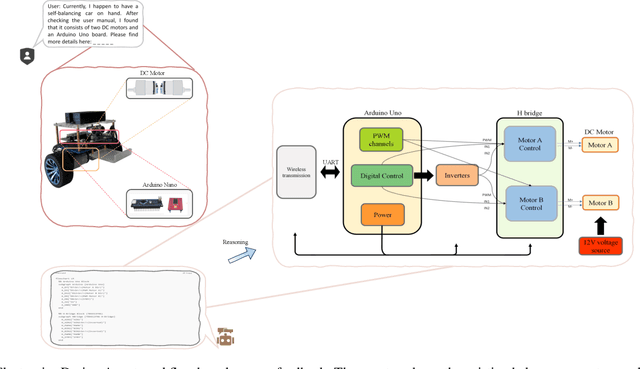
Existing LLM-enabled multi-agent frameworks are predominantly limited to digital or simulated environments and confined to narrowly focused knowledge domain, constraining their applicability to complex engineering tasks that require the design of physical embodiment, cross-disciplinary integration, and constraint-aware reasoning. This work proposes a multi-agent autonomous mechatronics design framework, integrating expertise across mechanical design, optimization, electronics, and software engineering to autonomously generate functional prototypes with minimal direct human design input. Operating primarily through a language-driven workflow, the framework incorporates structured human feedback to ensure robust performance under real-world constraints. To validate its capabilities, the framework is applied to a real-world challenge involving autonomous water-quality monitoring and sampling, where traditional methods are labor-intensive and ecologically disruptive. Leveraging the proposed system, a fully functional autonomous vessel was developed with optimized propulsion, cost-effective electronics, and advanced control. The design process was carried out by specialized agents, including a high-level planning agent responsible for problem abstraction and dedicated agents for structural, electronics, control, and software development. This approach demonstrates the potential of LLM-based multi-agent systems to automate real-world engineering workflows and reduce reliance on extensive domain expertise.
Activation-aware Probe-Query: Effective Key-Value Retrieval for Long-Context LLMs Inference
Feb 19, 2025Recent advances in large language models (LLMs) have showcased exceptional performance in long-context tasks, while facing significant inference efficiency challenges with limited GPU memory. Existing solutions first proposed the sliding-window approach to accumulate a set of historical \textbf{key-value} (KV) pairs for reuse, then further improvements selectively retain its subsets at each step. However, due to the sparse attention distribution across a long context, it is hard to identify and recall relevant KV pairs, as the attention is distracted by massive candidate pairs. Additionally, we found it promising to select representative tokens as probe-Query in each sliding window to effectively represent the entire context, which is an approach overlooked by existing methods. Thus, we propose \textbf{ActQKV}, a training-free, \textbf{Act}ivation-aware approach that dynamically determines probe-\textbf{Q}uery and leverages it to retrieve the relevant \textbf{KV} pairs for inference. Specifically, ActQKV monitors a token-level indicator, Activation Bias, within each context window, enabling the proper construction of probe-Query for retrieval at pre-filling stage. To accurately recall the relevant KV pairs and minimize the irrelevant ones, we design a dynamic KV cut-off mechanism guided by information density across layers at the decoding stage. Experiments on the Long-Bench and $\infty$ Benchmarks demonstrate its state-of-the-art performance with competitive inference quality and resource efficiency.