 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEDformer: Event-Synchronous Spiking Transformers for Irregular Telemetry Time Series Forecasting
Feb 03, 2026Telemetry streams from large-scale Internet-connected systems (e.g., IoT deployments and online platforms) naturally form an irregular multivariate time series (IMTS) whose accurate forecasting is operationally vital. A closer examination reveals a defining Sparsity-Event Duality (SED) property of IMTS, i.e., long stretches with sparse or no observations are punctuated by short, dense bursts where most semantic events (observations) occur. However, existing Graph- and Transformer-based forecasters ignore SED: pre-alignment to uniform grids with heavy padding violates sparsity by inflating sequences and forcing computation at non-informative steps, while relational recasting weakens event semantics by disrupting local temporal continuity. These limitations motivate a more faithful and natural modeling paradigm for IMTS that aligns with its SED property. We find that Spiking Neural Networks meet this requirement, as they communicate via sparse binary spikes and update in an event-driven manner, aligning naturally with the SED nature of IMTS. Therefore, we present SEDformer, an SED-enhanced Spiking Transformer for telemetry IMTS forecasting that couples: (1) a SED-based Spike Encoder converts raw observations into event synchronous spikes using an Event-Aligned LIF neuron, (2) an Event-Preserving Temporal Downsampling module compresses long gaps while retaining salient firings and (3) a stack of SED-based Spike Transformer blocks enable intra-series dependency modeling with a membrane-based linear attention driven by EA-LIF spiking features. Experiments on public telemetry IMTS datasets show that SEDformer attains state-of-the-art forecasting accuracy while reducing energy and memory usage, providing a natural and efficient path for modeling IMTS.
Alternating Training-based Label Smoothing Enhances Prompt Generalization
Aug 25, 2025



Recent advances in pre-trained vision-language models have demonstrated remarkable zero-shot generalization capabilities. To further enhance these models' adaptability to various downstream tasks, prompt tuning has emerged as a parameter-efficient fine-tuning method. However, despite its efficiency, the generalization ability of prompt remains limited. In contrast, label smoothing (LS) has been widely recognized as an effective regularization technique that prevents models from becoming over-confident and improves their generalization. This inspires us to explore the integration of LS with prompt tuning. However, we have observed that the vanilla LS even weakens the generalization ability of prompt tuning. To address this issue, we propose the Alternating Training-based Label Smoothing (ATLaS) method, which alternately trains with standard one-hot labels and soft labels generated by LS to supervise the prompt tuning. Moreover, we introduce two types of efficient offline soft labels, including Class-wise Soft Labels (CSL) and Instance-wise Soft Labels (ISL), to provide inter-class or instance-class relationships for prompt tuning. The theoretical properties of the proposed ATLaS method are analyzed. Extensive experiments demonstrate that the proposed ATLaS method, combined with CSL and ISL, consistently enhances the generalization performance of prompt tuning. Moreover, the proposed ATLaS method exhibits high compatibility with prevalent prompt tuning methods, enabling seamless integration into existing methods.
Open the Eyes of MPNN: Vision Enhances MPNN in Link Prediction
May 13, 2025Message-passing graph neural networks (MPNNs) and structural features (SFs) are cornerstones for the link prediction task. However, as a common and intuitive mode of understanding, the potential of visual perception has been overlooked in the MPNN community. For the first time, we equip MPNNs with vision structural awareness by proposing an effective framework called Graph Vision Network (GVN), along with a more efficient variant (E-GVN). Extensive empirical results demonstrate that with the proposed frameworks, GVN consistently benefits from the vision enhancement across seven link prediction datasets, including challenging large-scale graphs. Such improvements are compatible with existing state-of-the-art (SOTA) methods and GVNs achieve new SOTA results, thereby underscoring a promising novel direction for link prediction.
Alignment of Diffusion Models: Fundamentals, Challenges, and Future
Sep 12, 2024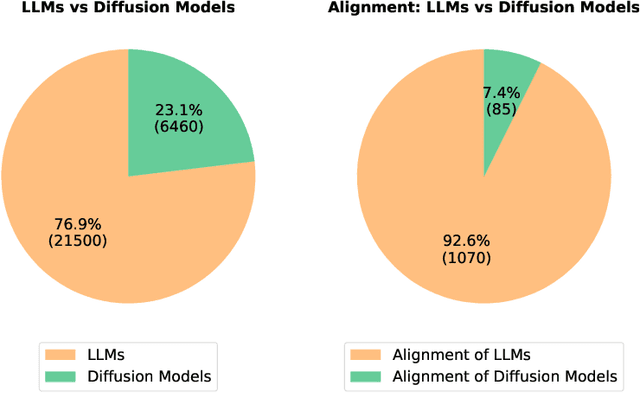
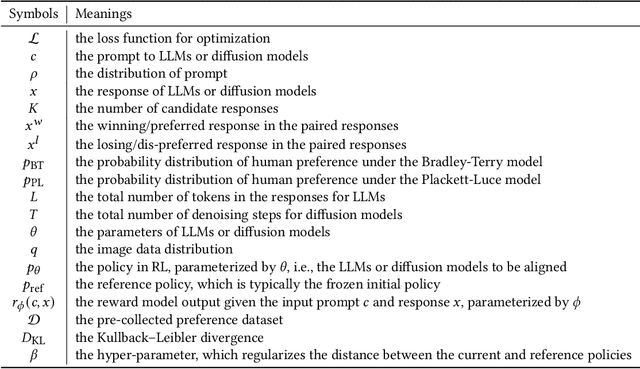
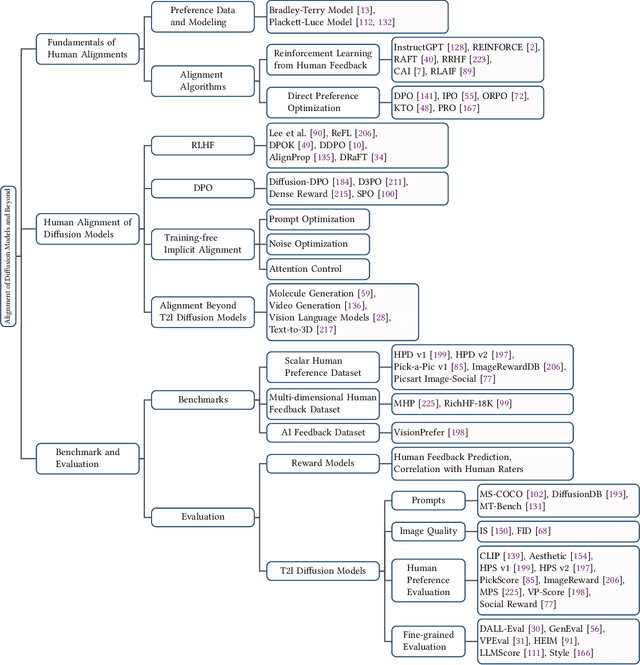
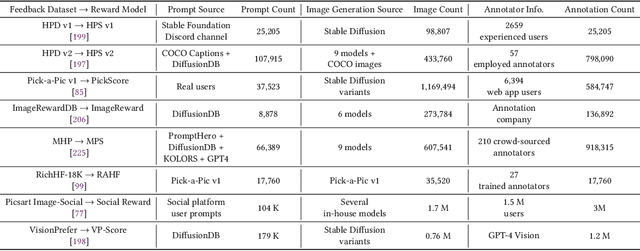
Diffusion models have emerged as the leading paradigm in generative modeling, excelling in various applications. Despite their success, these models often misalign with human intentions, generating outputs that may not match text prompts or possess desired properties. Inspired by the success of alignment in tuning large language models, recent studies have investigated aligning diffusion models with human expectations and preferences. This work mainly reviews alignment of diffusion models, covering advancements in fundamentals of alignment, alignment techniques of diffusion models, preference benchmarks, and evaluation for diffusion models. Moreover, we discuss key perspectives on current challenges and promising future directions on solving the remaining challenges in alignment of diffusion models. To the best of our knowledge, our work is the first comprehensive review paper for researchers and engineers to comprehend, practice, and research alignment of diffusion models.
CodeGraph: Enhancing Graph Reasoning of LLMs with Code
Aug 25, 2024
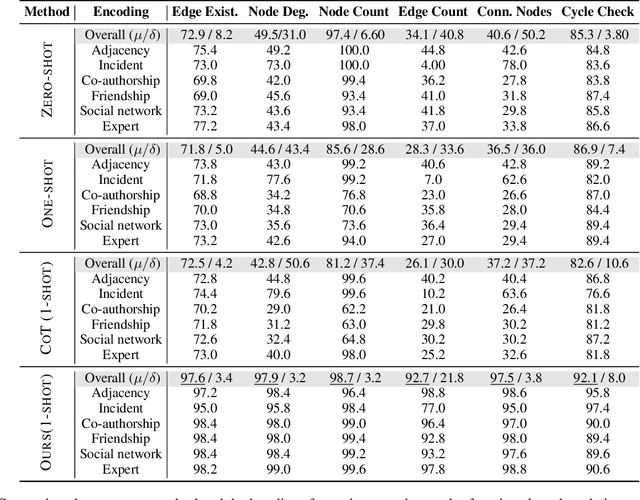


With the increasing popularity of large language models (LLMs), reasoning on basic graph algorithm problems is an essential intermediate step in assessing their abilities to process and infer complex graph reasoning tasks. Existing methods usually convert graph-structured data to textual descriptions and then use LLMs for reasoning and computation. However, LLMs often produce computation errors on arithmetic parts in basic graph algorithm problems, such as counting number of edges. In addition, they struggle to control or understand the output of the reasoning process, raising concerns about whether LLMs are simply guessing. In this paper, we introduce CodeGraph, a method that encodes graph problem solutions as code. The methods solve new graph problems by learning from exemplars, generating programs, and executing them via a program interpreter. Using the few-shot setting, we evaluate CodeGraph with the base LLM being GPT-3.5 Turbo, Llama3-70B Instruct, Mixtral-8x22B Instruct, and Mixtral-8x7B Instruct. Experimental results on six tasks with six graph encoding methods in the GraphQA dataset demonstrate that CodeGraph can boost performance on graph reasoning tasks inside LLMs by 1.3% to 58.6%, depending on the task. Compared to the existing methods, CodeGraph demonstrates strong performance on arithmetic problems in graph tasks and offers a more controllable and interpretable approach to the reasoning process.
You Only Merge Once: Learning the Pareto Set of Preference-Aware Model Merging
Aug 22, 2024Model merging, which combines multiple models into a single model, has gained increasing popularity in recent years. By efficiently integrating the capabilities of various models without their original training data, this significantly reduces the parameter count and memory usage. However, current methods can only produce one single merged model. This necessitates a performance trade-off due to conflicts among the various models, and the resultant one-size-fits-all model may not align with the preferences of different users who may prioritize certain models over others. To address this issue, we propose preference-aware model merging, and formulate this as a multi-objective optimization problem in which the performance of the merged model on each base model's task is treated as an objective. In only one merging process, the proposed parameter-efficient structure can generate the whole Pareto set of merged models, each representing the Pareto-optimal model for a given user-specified preference. Merged models can also be selected from the learned Pareto set that are tailored to different user preferences. Experimental results on a number of benchmark datasets demonstrate that the proposed preference-aware Pareto Merging can obtain a diverse set of trade-off models and outperforms state-of-the-art model merging baselines.
Knowledge-Aware Parsimony Learning: A Perspective from Relational Graphs
Jun 29, 2024The scaling law, a strategy that involves the brute-force scaling of the training dataset and learnable parameters, has become a prevalent approach for developing stronger learning models. In this paper, we examine its rationale in terms of learning from relational graphs. We demonstrate that directly adhering to such a scaling law does not necessarily yield stronger models due to architectural incompatibility and representation bottlenecks. To tackle this challenge, we propose a novel framework for learning from relational graphs via knowledge-aware parsimony learning. Our method draws inspiration from the duality between data and knowledge inherent in these graphs. Specifically, we first extract knowledge (like symbolic logic and physical laws) during the learning process, and then apply combinatorial generalization to the task at hand. This extracted knowledge serves as the ``building blocks'' for achieving parsimony learning. By applying this philosophy to architecture, parameters, and inference, we can effectively achieve versatile, sample-efficient, and interpretable learning. Experimental results show that our proposed framework surpasses methods that strictly follow the traditional scaling-up roadmap. This highlights the importance of incorporating knowledge in the development of next-generation learning technologies.
Nonparametric Teaching for Multiple Learners
Nov 17, 2023We study the problem of teaching multiple learners simultaneously in the nonparametric iterative teaching setting, where the teacher iteratively provides examples to the learner for accelerating the acquisition of a target concept. This problem is motivated by the gap between current single-learner teaching setting and the real-world scenario of human instruction where a teacher typically imparts knowledge to multiple students. Under the new problem formulation, we introduce a novel framework -- Multi-learner Nonparametric Teaching (MINT). In MINT, the teacher aims to instruct multiple learners, with each learner focusing on learning a scalar-valued target model. To achieve this, we frame the problem as teaching a vector-valued target model and extend the target model space from a scalar-valued reproducing kernel Hilbert space used in single-learner scenarios to a vector-valued space. Furthermore, we demonstrate that MINT offers significant teaching speed-up over repeated single-learner teaching, particularly when the multiple learners can communicate with each other. Lastly, we conduct extensive experiments to validate the practicality and efficiency of MINT.
Positive-Unlabeled Node Classification with Structure-aware Graph Learning
Oct 20, 2023Node classification on graphs is an important research problem with many applications. Real-world graph data sets may not be balanced and accurate as assumed by most existing works. A challenging setting is positive-unlabeled (PU) node classification, where labeled nodes are restricted to positive nodes. It has diverse applications, e.g., pandemic prediction or network anomaly detection. Existing works on PU node classification overlook information in the graph structure, which can be critical. In this paper, we propose to better utilize graph structure for PU node classification. We first propose a distance-aware PU loss that uses homophily in graphs to introduce more accurate supervision. We also propose a regularizer to align the model with graph structure. Theoretical analysis shows that minimizing the proposed loss also leads to minimizing the expected loss with both positive and negative labels. Extensive empirical evaluation on diverse graph data sets demonstrates its superior performance over existing state-of-the-art methods.
PixArt-$α$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Oct 16, 2023



The most advanced text-to-image (T2I) models require significant training costs (e.g., millions of GPU hours), seriously hindering the fundamental innovation for the AIGC community while increasing CO2 emissions. This paper introduces PIXART-$\alpha$, a Transformer-based T2I diffusion model whose image generation quality is competitive with state-of-the-art image generators (e.g., Imagen, SDXL, and even Midjourney), reaching near-commercial application standards. Additionally, it supports high-resolution image synthesis up to 1024px resolution with low training cost, as shown in Figure 1 and 2. To achieve this goal, three core designs are proposed: (1) Training strategy decomposition: We devise three distinct training steps that separately optimize pixel dependency, text-image alignment, and image aesthetic quality; (2) Efficient T2I Transformer: We incorporate cross-attention modules into Diffusion Transformer (DiT) to inject text conditions and streamline the computation-intensive class-condition branch; (3) High-informative data: We emphasize the significance of concept density in text-image pairs and leverage a large Vision-Language model to auto-label dense pseudo-captions to assist text-image alignment learning. As a result, PIXART-$\alpha$'s training speed markedly surpasses existing large-scale T2I models, e.g., PIXART-$\alpha$ only takes 10.8% of Stable Diffusion v1.5's training time (675 vs. 6,250 A100 GPU days), saving nearly \$300,000 (\$26,000 vs. \$320,000) and reducing 90% CO2 emissions. Moreover, compared with a larger SOTA model, RAPHAEL, our training cost is merely 1%. Extensive experiments demonstrate that PIXART-$\alpha$ excels in image quality, artistry, and semantic control. We hope PIXART-$\alpha$ will provide new insights to the AIGC community and startups to accelerate building their own high-quality yet low-cost generative models from scratch.