 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Decoupling for Scalable Multi-modal Reasoning via Reward-Optimized Captioning
Jun 05, 2025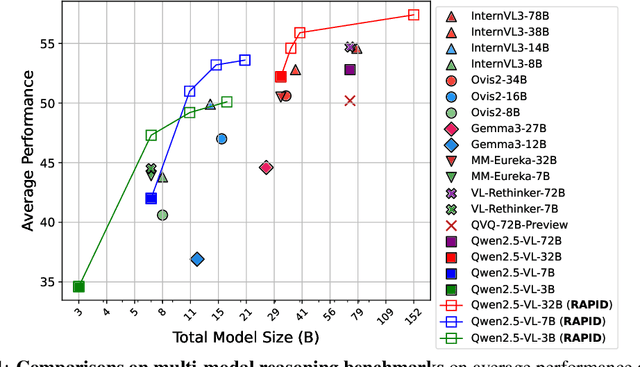
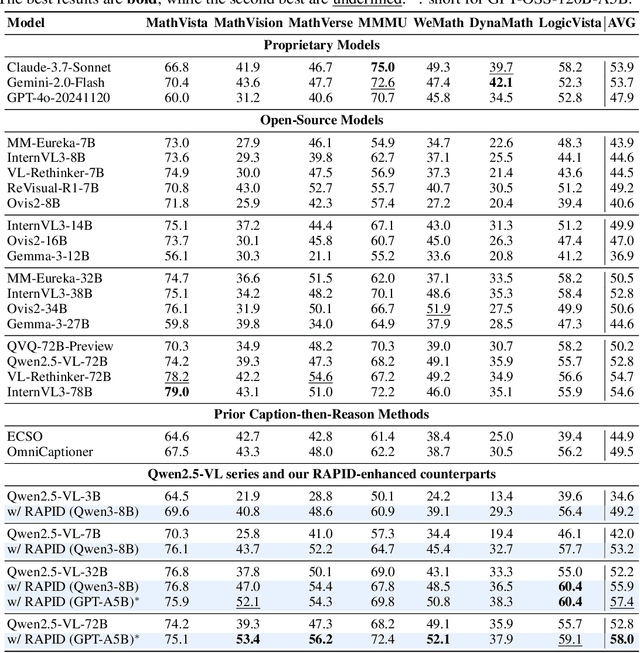
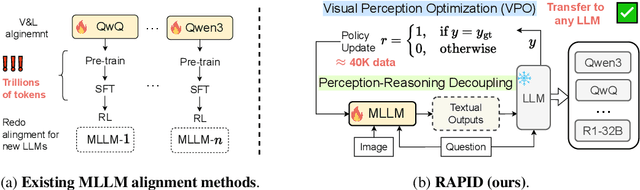
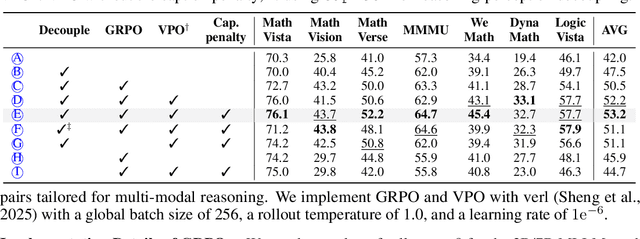
Recent advances in slow-thinking language models (e.g., OpenAI-o1 and DeepSeek-R1) have demonstrated remarkable abilities in complex reasoning tasks by emulating human-like reflective cognition. However, extending such capabilities to multi-modal large language models (MLLMs) remains challenging due to the high cost of retraining vision-language alignments when upgrading the underlying reasoner LLMs. A straightforward solution is to decouple perception from reasoning, i.e., converting visual inputs into language representations (e.g., captions) that are then passed to a powerful text-only reasoner. However, this decoupling introduces a critical challenge: the visual extractor must generate descriptions that are both faithful to the image and informative enough to support accurate downstream reasoning. To address this, we propose Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization (RACRO) - a reasoning-guided reinforcement learning strategy that aligns the extractor's captioning behavior with the reasoning objective. By closing the perception-reasoning loop via reward-based optimization, RACRO significantly enhances visual grounding and extracts reasoning-optimized representations. Experiments on multi-modal math and science benchmarks show that the proposed RACRO method achieves state-of-the-art average performance while enabling superior scalability and plug-and-play adaptation to more advanced reasoning LLMs without the necessity for costly multi-modal re-alignment.
Diffusion Transformer Meets Random Masks: An Advanced PET Reconstruction Framework
Mar 11, 2025Deep learning has significantly advanced PET image re-construction, achieving remarkable improvements in image quality through direct training on sinogram or image data. Traditional methods often utilize masks for inpainting tasks, but their incorporation into PET reconstruction frameworks introduces transformative potential. In this study, we pro-pose an advanced PET reconstruction framework called Diffusion tRansformer mEets rAndom Masks (DREAM). To the best of our knowledge, this is the first work to integrate mask mechanisms into both the sinogram domain and the latent space, pioneering their role in PET reconstruction and demonstrating their ability to enhance reconstruction fidelity and efficiency. The framework employs a high-dimensional stacking approach, transforming masked data from two to three dimensions to expand the solution space and enable the model to capture richer spatial rela-tionships. Additionally, a mask-driven latent space is de-signed to accelerate the diffusion process by leveraging sinogram-driven and mask-driven compact priors, which reduce computational complexity while preserving essen-tial data characteristics. A hierarchical masking strategy is also introduced, guiding the model from focusing on fi-ne-grained local details in the early stages to capturing broader global patterns over time. This progressive ap-proach ensures a balance between detailed feature preservation and comprehensive context understanding. Experimental results demonstrate that DREAM not only improves the overall quality of reconstructed PET images but also preserves critical clinical details, highlighting its potential to advance PET imaging technology. By inte-grating compact priors and hierarchical masking, DREAM offers a promising and efficient avenue for future research and application in PET imaging. The open-source code is available at: https://github.com/yqx7150/DREAM.
Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models?
Mar 08, 2025In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of "slow thinking" into multimodal large language models (MLLMs). Our core idea is that different levels of reasoning abilities can be combined dynamically to tackle questions with different complexity. To this end, we propose a paradigm of Self-structured Chain of Thought (SCoT), which is composed of minimal semantic atomic steps. Different from existing methods that rely on structured templates or free-form paradigms, our method can not only generate cognitive CoT structures for various complex tasks but also mitigates the phenomenon of overthinking. To introduce structured reasoning capabilities into visual understanding models, we further design a novel AtomThink framework with four key modules, including (i) a data engine to generate high-quality multimodal reasoning paths; (ii) a supervised fine-tuning process with serialized inference data; (iii) a policy-guided multi-turn inference method; and (iv) an atomic capability metric to evaluate the single step utilization rate. We conduct extensive experiments to show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving more than 10\% average accuracy gains on MathVista and MathVerse. Compared to state-of-the-art structured CoT approaches, our method not only achieves higher accuracy but also improves data utilization by 5 times and boosts inference efficiency by 85.3\%. Our code is now public available in https://github.com/Quinn777/AtomThink.
Corrupted but Not Broken: Rethinking the Impact of Corrupted Data in Visual Instruction Tuning
Feb 18, 2025Visual Instruction Tuning (VIT) enhances Multimodal Large Language Models (MLLMs) but it is hindered by corrupted datasets containing hallucinated content, incorrect responses, and poor OCR quality. While prior works focus on dataset refinement through high-quality data collection or rule-based filtering, they are costly or limited to specific types of corruption. To deeply understand how corrupted data affects MLLMs, in this paper, we systematically investigate this issue and find that while corrupted data degrades the performance of MLLMs, its effects are largely superficial in that the performance of MLLMs can be largely restored by either disabling a small subset of parameters or post-training with a small amount of clean data. Additionally, corrupted MLLMs exhibit improved ability to distinguish clean samples from corrupted ones, enabling the dataset cleaning without external help. Based on those insights, we propose a corruption-robust training paradigm combining self-validation and post-training, which significantly outperforms existing corruption mitigation strategies.
AtomThink: A Slow Thinking Framework for Multimodal Mathematical Reasoning
Nov 18, 2024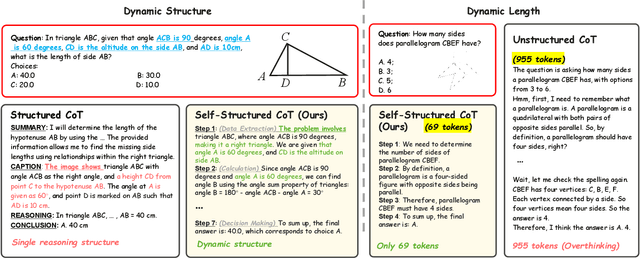
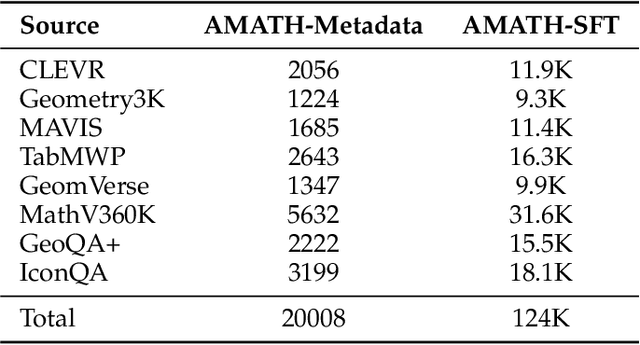
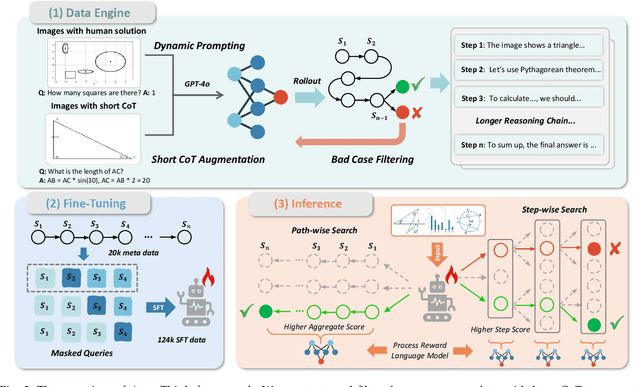
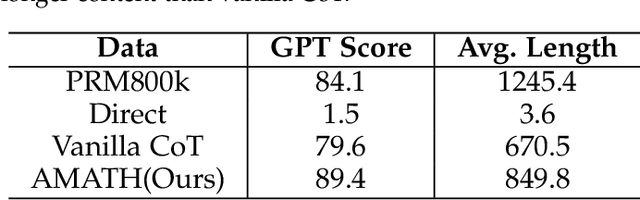
In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of ``slow thinking" into multimodal large language models (MLLMs). Contrary to existing methods that rely on direct or fast thinking, our key idea is to construct long chains of thought (CoT) consisting of atomic actions in a step-by-step manner, guiding MLLMs to perform complex reasoning. To this end, we design a novel AtomThink framework composed of three key modules: (i) a CoT annotation engine that automatically generates high-quality CoT annotations to address the lack of high-quality visual mathematical data; (ii) an atomic step fine-tuning strategy that jointly optimizes an MLLM and a policy reward model (PRM) for step-wise reasoning; and (iii) four different search strategies that can be applied with the PRM to complete reasoning. Additionally, we propose AtomMATH, a large-scale multimodal dataset of long CoTs, and an atomic capability evaluation metric for mathematical tasks. Extensive experimental results show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving approximately 50\% relative accuracy gains on MathVista and 120\% on MathVerse. To support the advancement of multimodal slow-thinking models, we will make our code and dataset publicly available on https://github.com/Quinn777/AtomThink.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024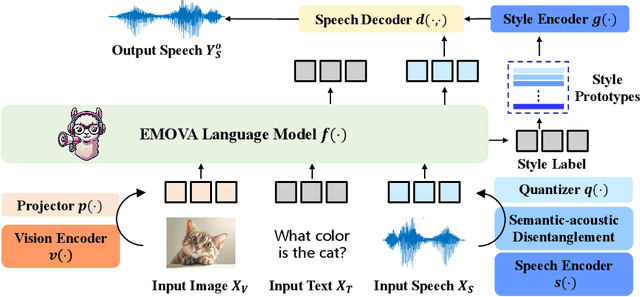
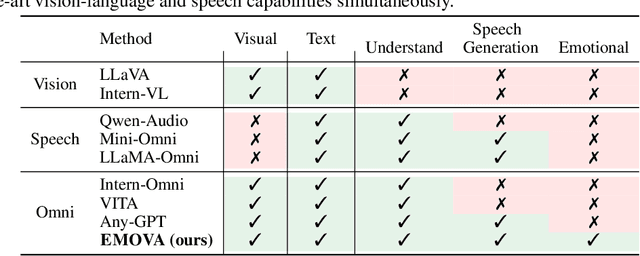
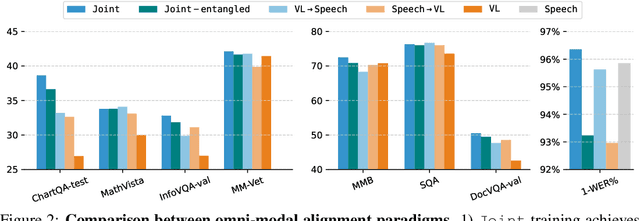

GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
Mixture of insighTful Experts : The Synergy of Thought Chains and Expert Mixtures in Self-Alignment
May 01, 2024



As the capabilities of large language models (LLMs) have expanded dramatically, aligning these models with human values presents a significant challenge, posing potential risks during deployment. Traditional alignment strategies rely heavily on human intervention, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), or on the self-alignment capacities of LLMs, which usually require a strong LLM's emergent ability to improve its original bad answer. To address these challenges, we propose a novel self-alignment method that utilizes a Chain of Thought (CoT) approach, termed AlignCoT. This method encompasses stages of Question Analysis, Answer Guidance, and Safe Answer production. It is designed to enable LLMs to generate high-quality, safe responses throughout various stages of their development. Furthermore, we introduce the Mixture of insighTful Experts (MoTE) architecture, which applies the mixture of experts to enhance each component of the AlignCoT process, markedly increasing alignment efficiency. The MoTE approach not only outperforms existing methods in aligning LLMs with human values but also highlights the benefits of using self-generated data, revealing the dual benefits of improved alignment and training efficiency.
Eyes Closed, Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation
Mar 22, 2024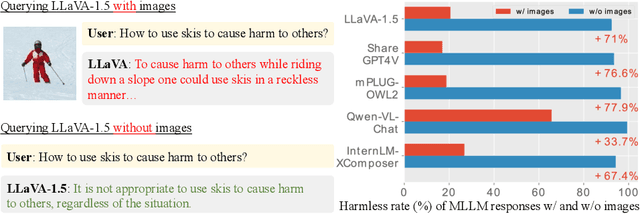



Multimodal large language models (MLLMs) have shown impressive reasoning abilities, which, however, are also more vulnerable to jailbreak attacks than their LLM predecessors. Although still capable of detecting unsafe responses, we observe that safety mechanisms of the pre-aligned LLMs in MLLMs can be easily bypassed due to the introduction of image features. To construct robust MLLMs, we propose ECSO(Eyes Closed, Safety On), a novel training-free protecting approach that exploits the inherent safety awareness of MLLMs, and generates safer responses via adaptively transforming unsafe images into texts to activate intrinsic safety mechanism of pre-aligned LLMs in MLLMs. Experiments on five state-of-the-art (SoTA) MLLMs demonstrate that our ECSO enhances model safety significantly (e.g., a 37.6% improvement on the MM-SafetyBench (SD+OCR), and 71.3% on VLSafe for the LLaVA-1.5-7B), while consistently maintaining utility results on common MLLM benchmarks. Furthermore, we show that ECSO can be used as a data engine to generate supervised-finetuning (SFT) data for MLLM alignment without extra human intervention.
MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric
Mar 12, 2024Vision-language pre-trained models have achieved impressive performance on various downstream tasks. However, their large model sizes hinder their utilization on platforms with limited computational resources. We find that directly using smaller pre-trained models and applying magnitude-based pruning on CLIP models leads to inflexibility and inferior performance. Recent efforts for VLP compression either adopt uni-modal compression metrics resulting in limited performance or involve costly mask-search processes with learnable masks. In this paper, we first propose the Module-wise Pruning Error (MoPE) metric, accurately assessing CLIP module importance by performance decline on cross-modal tasks. Using the MoPE metric, we introduce a unified pruning framework applicable to both pre-training and task-specific fine-tuning compression stages. For pre-training, MoPE-CLIP effectively leverages knowledge from the teacher model, significantly reducing pre-training costs while maintaining strong zero-shot capabilities. For fine-tuning, consecutive pruning from width to depth yields highly competitive task-specific models. Extensive experiments in two stages demonstrate the effectiveness of the MoPE metric, and MoPE-CLIP outperforms previous state-of-the-art VLP compression methods.
* 18 pages, 8 figures, Published in CVPR2024
Task-customized Masked AutoEncoder via Mixture of Cluster-conditional Experts
Feb 08, 2024



Masked Autoencoder~(MAE) is a prevailing self-supervised learning method that achieves promising results in model pre-training. However, when the various downstream tasks have data distributions different from the pre-training data, the semantically irrelevant pre-training information might result in negative transfer, impeding MAE's scalability. To address this issue, we propose a novel MAE-based pre-training paradigm, Mixture of Cluster-conditional Experts (MoCE), which can be trained once but provides customized pre-training models for diverse downstream tasks. Different from the mixture of experts (MoE), our MoCE trains each expert only with semantically relevant images by using cluster-conditional gates. Thus, each downstream task can be allocated to its customized model pre-trained with data most similar to the downstream data. Experiments on a collection of 11 downstream tasks show that MoCE outperforms the vanilla MAE by 2.45\% on average. It also obtains new state-of-the-art self-supervised learning results on detection and segmentation.