 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodePivot: Bootstrapping Multilingual Transpilation in LLMs via Reinforcement Learning without Parallel Corpora
Apr 20, 2026Transpilation, or code translation, aims to convert source code from one programming language (PL) to another. It is beneficial for many downstream applications, from modernizing large legacy codebases to augmenting data for low-resource PLs. Recent large language model (LLM)-based approaches have demonstrated immense potential for code translation. Among these approaches, training-based methods are particularly important because LLMs currently do not effectively adapt to domain-specific settings that suffer from a lack of knowledge without targeted training. This limitation is evident in transpilation tasks involving low-resource PLs. However, existing training-based approaches rely on a pairwise transpilation paradigm, making it impractical to support a diverse range of PLs. This limitation is particularly prominent for low-resource PLs due to a scarcity of training data. Furthermore, these methods suffer from suboptimal reinforcement learning (RL) reward formulations. To address these limitations, we propose CodePivot, a training framework that leverages Python as an intermediate representation (IR), augmented by a novel RL reward mechanism, Aggressive-Partial-Functional reward, to bootstrap the model's multilingual transpilation ability without requiring parallel corpora. Experiments involving 10 PLs show that the resulting 7B model, trained on Python-to-Others tasks, consistently improves performance across both general and low-resource PL-related transpilation tasks. It outperforms substantially larger mainstream models with hundreds of billions more parameters, such as Deepseek-R1 and Qwen3-235B-A22B-Instruct-2507, on Python-to-Others tasks and Others-to-All tasks, respectively. In addition, it outperforms its counterpart trained directly on Any-to-Any tasks on general transpilation tasks. The code and data are available at https://github.com/lishangyu-hkust/CodePivot.
Perceptual Decoupling for Scalable Multi-modal Reasoning via Reward-Optimized Captioning
Jun 05, 2025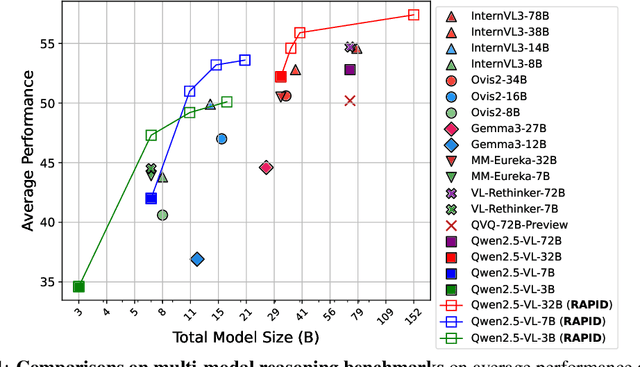
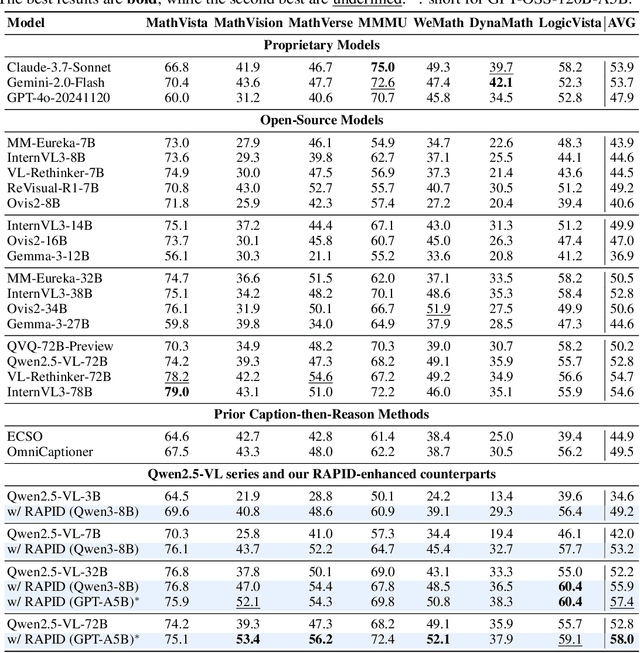
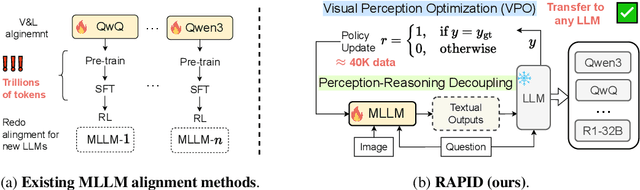
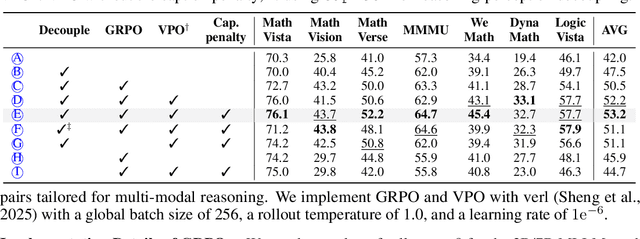
Recent advances in slow-thinking language models (e.g., OpenAI-o1 and DeepSeek-R1) have demonstrated remarkable abilities in complex reasoning tasks by emulating human-like reflective cognition. However, extending such capabilities to multi-modal large language models (MLLMs) remains challenging due to the high cost of retraining vision-language alignments when upgrading the underlying reasoner LLMs. A straightforward solution is to decouple perception from reasoning, i.e., converting visual inputs into language representations (e.g., captions) that are then passed to a powerful text-only reasoner. However, this decoupling introduces a critical challenge: the visual extractor must generate descriptions that are both faithful to the image and informative enough to support accurate downstream reasoning. To address this, we propose Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization (RACRO) - a reasoning-guided reinforcement learning strategy that aligns the extractor's captioning behavior with the reasoning objective. By closing the perception-reasoning loop via reward-based optimization, RACRO significantly enhances visual grounding and extracts reasoning-optimized representations. Experiments on multi-modal math and science benchmarks show that the proposed RACRO method achieves state-of-the-art average performance while enabling superior scalability and plug-and-play adaptation to more advanced reasoning LLMs without the necessity for costly multi-modal re-alignment.
Corrupted but Not Broken: Rethinking the Impact of Corrupted Data in Visual Instruction Tuning
Feb 18, 2025Visual Instruction Tuning (VIT) enhances Multimodal Large Language Models (MLLMs) but it is hindered by corrupted datasets containing hallucinated content, incorrect responses, and poor OCR quality. While prior works focus on dataset refinement through high-quality data collection or rule-based filtering, they are costly or limited to specific types of corruption. To deeply understand how corrupted data affects MLLMs, in this paper, we systematically investigate this issue and find that while corrupted data degrades the performance of MLLMs, its effects are largely superficial in that the performance of MLLMs can be largely restored by either disabling a small subset of parameters or post-training with a small amount of clean data. Additionally, corrupted MLLMs exhibit improved ability to distinguish clean samples from corrupted ones, enabling the dataset cleaning without external help. Based on those insights, we propose a corruption-robust training paradigm combining self-validation and post-training, which significantly outperforms existing corruption mitigation strategies.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024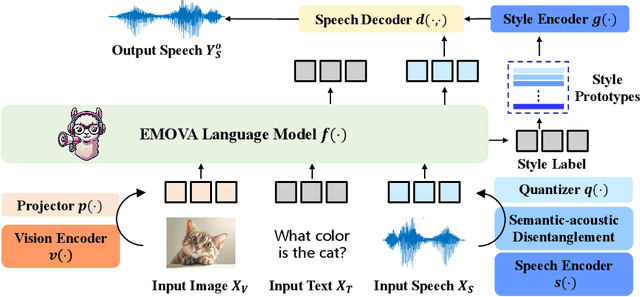
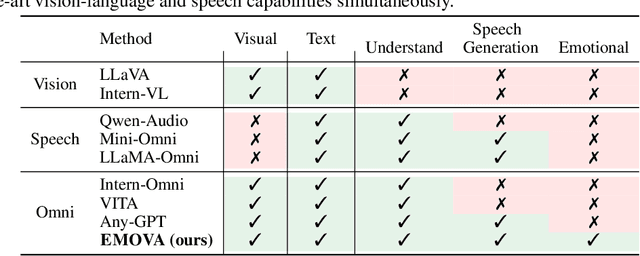
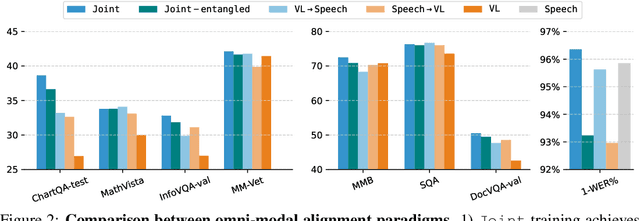

GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
Mixture of insighTful Experts : The Synergy of Thought Chains and Expert Mixtures in Self-Alignment
May 01, 2024



As the capabilities of large language models (LLMs) have expanded dramatically, aligning these models with human values presents a significant challenge, posing potential risks during deployment. Traditional alignment strategies rely heavily on human intervention, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), or on the self-alignment capacities of LLMs, which usually require a strong LLM's emergent ability to improve its original bad answer. To address these challenges, we propose a novel self-alignment method that utilizes a Chain of Thought (CoT) approach, termed AlignCoT. This method encompasses stages of Question Analysis, Answer Guidance, and Safe Answer production. It is designed to enable LLMs to generate high-quality, safe responses throughout various stages of their development. Furthermore, we introduce the Mixture of insighTful Experts (MoTE) architecture, which applies the mixture of experts to enhance each component of the AlignCoT process, markedly increasing alignment efficiency. The MoTE approach not only outperforms existing methods in aligning LLMs with human values but also highlights the benefits of using self-generated data, revealing the dual benefits of improved alignment and training efficiency.
Eyes Closed, Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation
Mar 22, 2024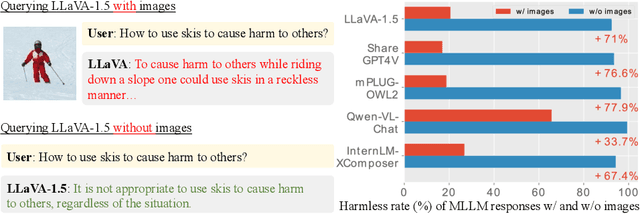



Multimodal large language models (MLLMs) have shown impressive reasoning abilities, which, however, are also more vulnerable to jailbreak attacks than their LLM predecessors. Although still capable of detecting unsafe responses, we observe that safety mechanisms of the pre-aligned LLMs in MLLMs can be easily bypassed due to the introduction of image features. To construct robust MLLMs, we propose ECSO(Eyes Closed, Safety On), a novel training-free protecting approach that exploits the inherent safety awareness of MLLMs, and generates safer responses via adaptively transforming unsafe images into texts to activate intrinsic safety mechanism of pre-aligned LLMs in MLLMs. Experiments on five state-of-the-art (SoTA) MLLMs demonstrate that our ECSO enhances model safety significantly (e.g., a 37.6% improvement on the MM-SafetyBench (SD+OCR), and 71.3% on VLSafe for the LLaVA-1.5-7B), while consistently maintaining utility results on common MLLM benchmarks. Furthermore, we show that ECSO can be used as a data engine to generate supervised-finetuning (SFT) data for MLLM alignment without extra human intervention.
Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning
Dec 19, 2023



Instruction tuning of the Large Vision-language Models (LVLMs) has revolutionized the development of versatile models with zero-shot generalization across a wide range of downstream vision-language tasks. However, diversity of training tasks of different sources and formats would lead to inevitable task conflicts, where different tasks conflicts for the same set of model parameters, resulting in sub-optimal instruction-following abilities. To address that, we propose the Mixture of Cluster-conditional LoRA Experts (MoCLE), a novel Mixture of Experts (MoE) architecture designed to activate the task-customized model parameters based on the instruction clusters. A separate universal expert is further incorporated to improve the generalization capabilities of MoCLE for novel instructions. Extensive experiments on 10 zero-shot tasks demonstrate the effectiveness of MoCLE.
Leveraging per Image-Token Consistency for Vision-Language Pre-training
Nov 20, 2022Most existing vision-language pre-training (VLP) approaches adopt cross-modal masked language modeling (CMLM) to learn vision-language associations. However, we find that CMLM is insufficient for this purpose according to our observations: (1) Modality bias: a considerable amount of masked tokens in CMLM can be recovered with only the language information, ignoring the visual inputs. (2) Under-utilization of the unmasked tokens: CMLM primarily focuses on the masked token but it cannot simultaneously leverage other tokens to learn vision-language associations. To handle those limitations, we propose EPIC (lEveraging Per Image-Token Consistency for vision-language pre-training). In EPIC, for each image-sentence pair, we mask tokens that are salient to the image (i.e., Saliency-based Masking Strategy) and replace them with alternatives sampled from a language model (i.e., Inconsistent Token Generation Procedure), and then the model is required to determine for each token in the sentence whether they are consistent with the image (i.e., Image-Text Consistent Task). The proposed EPIC method is easily combined with pre-training methods. Extensive experiments show that the combination of the EPIC method and state-of-the-art pre-training approaches, including ViLT, ALBEF, METER, and X-VLM, leads to significant improvements on downstream tasks.
Exploring Hierarchical Graph Representation for Large-Scale Zero-Shot Image Classification
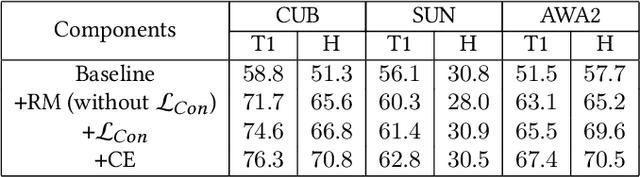
Mar 02, 2022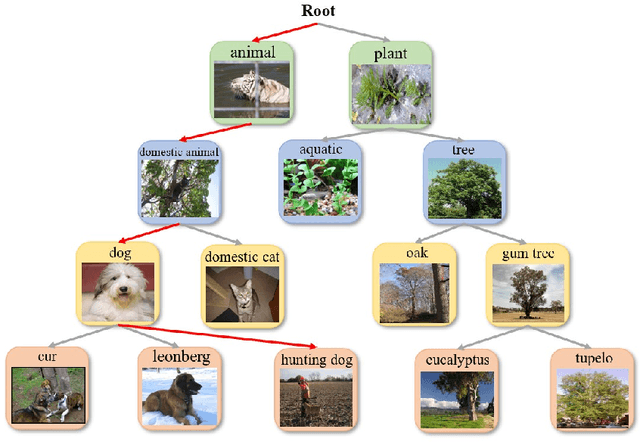

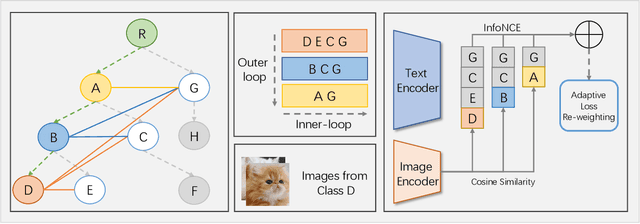
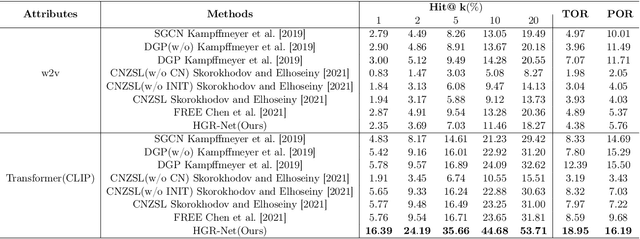
The main question we address in this paper is how to scale up visual recognition of unseen classes, also known as zero-shot learning, to tens of thousands of categories as in the ImageNet-21K benchmark. At this scale, especially with many fine-grained categories included in ImageNet-21K, it is critical to learn quality visual semantic representations that are discriminative enough to recognize unseen classes and distinguish them from seen ones. We propose a Hierarchical Graphical knowledge Representation framework for the confidence-based classification method, dubbed as HGR-Net. Our experimental results demonstrate that HGR-Net can grasp class inheritance relations by utilizing hierarchical conceptual knowledge. Our method significantly outperformed all existing techniques, boosting the performance 7% compared to the runner-up approach on the ImageNet-21K benchmark. We show that HGR-Net is learning-efficient in few-shot scenarios. We also analyzed our method on smaller datasets like ImageNet-21K-P, 2-hops and 3-hops, demonstrating its generalization ability. Our benchmark and code will be made publicly available.
Region Semantically Aligned Network for Zero-Shot Learning
Oct 14, 2021


Zero-shot learning (ZSL) aims to recognize unseen classes based on the knowledge of seen classes. Previous methods focused on learning direct embeddings from global features to the semantic space in hope of knowledge transfer from seen classes to unseen classes. However, an unseen class shares local visual features with a set of seen classes and leveraging global visual features makes the knowledge transfer ineffective. To tackle this problem, we propose a Region Semantically Aligned Network (RSAN), which maps local features of unseen classes to their semantic attributes. Instead of using global features which are obtained by an average pooling layer after an image encoder, we directly utilize the output of the image encoder which maintains local information of the image. Concretely, we obtain each attribute from a specific region of the output and exploit these attributes for recognition. As a result, the knowledge of seen classes can be successfully transferred to unseen classes in a region-bases manner. In addition, we regularize the image encoder through attribute regression with a semantic knowledge to extract robust and attribute-related visual features. Experiments on several standard ZSL datasets reveal the benefit of the proposed RSAN method, outperforming state-of-the-art methods.