 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Multimodal Interleaved Generation via Group Relative Policy Optimization
Mar 10, 2026Unified vision-language models have made significant progress in multimodal understanding and generation, yet they largely fall short in producing multimodal interleaved outputs, which is a crucial capability for tasks like visual storytelling and step-by-step visual reasoning. In this work, we propose a reinforcement learning-based post-training strategy to unlock this capability in existing unified models, without relying on large-scale multimodal interleaved datasets. We begin with a warm-up stage using a hybrid dataset comprising curated interleaved sequences and limited data for multimodal understanding and text-to-image generation, which exposes the model to interleaved generation patterns while preserving its pretrained capabilities. To further refine interleaved generation, we propose a unified policy optimization framework that extends Group Relative Policy Optimization (GRPO) to the multimodal setting. Our approach jointly models text and image generation within a single decoding trajectory and optimizes it with our novel hybrid rewards covering textual relevance, visual-text alignment, and structural fidelity. Additionally, we incorporate process-level rewards to provide step-wise guidance, enhancing training efficiency in complex multimodal tasks. Experiments on MMIE and InterleavedBench demonstrate that our approach significantly enhances the quality and coherence of multimodal interleaved generation.
InterCoG: Towards Spatially Precise Image Editing with Interleaved Chain-of-Grounding Reasoning
Mar 03, 2026Emerging unified editing models have demonstrated strong capabilities in general object editing tasks. However, it remains a significant challenge to perform fine-grained editing in complex multi-entity scenes, particularly those where targets are not visually salient and require spatial reasoning. To this end, we propose InterCoG, a novel text-vision Interleaved Chain-of-Grounding reasoning framework for fine-grained image editing in complex real-world scenes. The key insight of InterCoG is to first perform object position reasoning solely within text that includes spatial relation details to explicitly deduce the location and identity of the edited target. It then conducts visual grounding via highlighting the editing targets with generated bounding boxes and masks in pixel space, and finally rewrites the editing description to specify the intended outcomes. To further facilitate this paradigm, we propose two auxiliary training modules: multimodal grounding reconstruction supervision and multimodal grounding reasoning alignment to enforce spatial localization accuracy and reasoning interpretability, respectively. We also construct GroundEdit-45K, a dataset comprising 45K grounding-oriented editing samples with detailed reasoning annotations, and GroundEdit-Bench for grounding-aware editing evaluation. Extensive experiments substantiate the superiority of our approach in highly precise edits under spatially intricate and multi-entity scenes.
SlowFocus: Enhancing Fine-grained Temporal Understanding in Video LLM
Feb 03, 2026Large language models (LLMs) have demonstrated exceptional capabilities in text understanding, which has paved the way for their expansion into video LLMs (Vid-LLMs) to analyze video data. However, current Vid-LLMs struggle to simultaneously retain high-quality frame-level semantic information (i.e., a sufficient number of tokens per frame) and comprehensive video-level temporal information (i.e., an adequate number of sampled frames per video). This limitation hinders the advancement of Vid-LLMs towards fine-grained video understanding. To address this issue, we introduce the SlowFocus mechanism, which significantly enhances the equivalent sampling frequency without compromising the quality of frame-level visual tokens. SlowFocus begins by identifying the query-related temporal segment based on the posed question, then performs dense sampling on this segment to extract local high-frequency features. A multi-frequency mixing attention module is further leveraged to aggregate these local high-frequency details with global low-frequency contexts for enhanced temporal comprehension. Additionally, to tailor Vid-LLMs to this innovative mechanism, we introduce a set of training strategies aimed at bolstering both temporal grounding and detailed temporal reasoning capabilities. Furthermore, we establish FineAction-CGR, a benchmark specifically devised to assess the ability of Vid-LLMs to process fine-grained temporal understanding tasks. Comprehensive experiments demonstrate the superiority of our mechanism across both existing public video understanding benchmarks and our proposed FineAction-CGR.
KFFocus: Highlighting Keyframes for Enhanced Video Understanding
Aug 12, 2025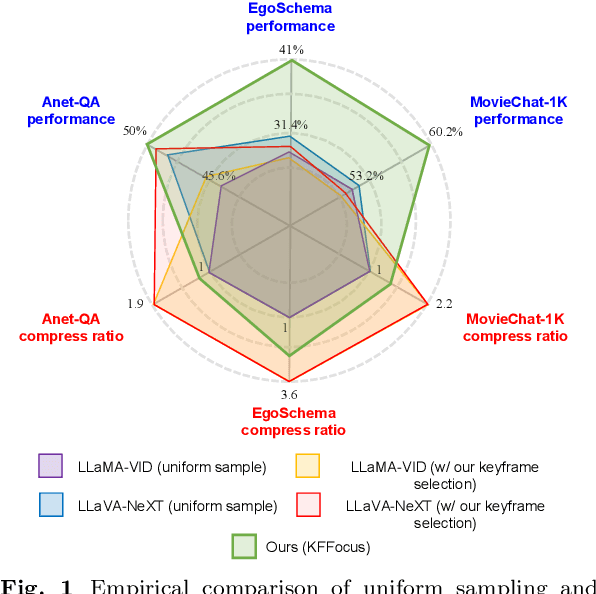
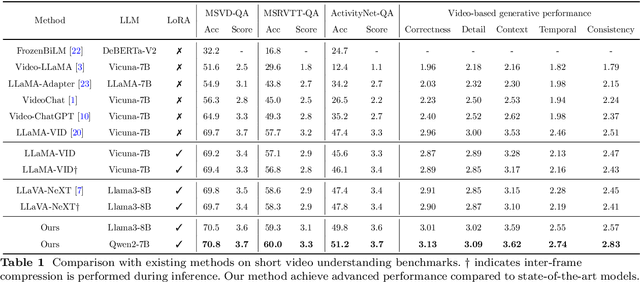
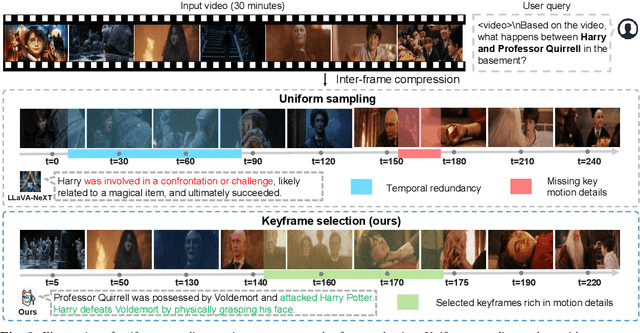
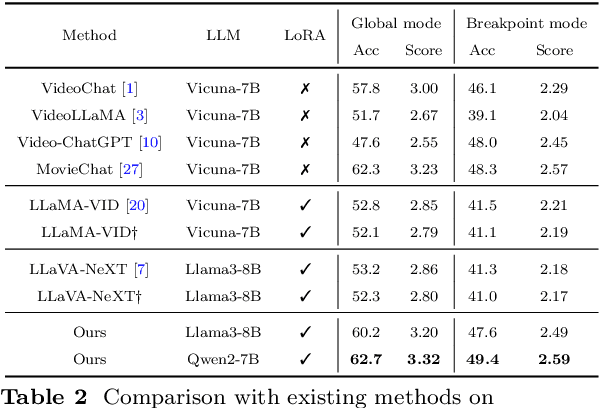
Recently, with the emergence of large language models, multimodal LLMs have demonstrated exceptional capabilities in image and video modalities. Despite advancements in video comprehension, the substantial computational demands of long video sequences lead current video LLMs (Vid-LLMs) to employ compression strategies at both the inter-frame level (e.g., uniform sampling of video frames) and intra-frame level (e.g., condensing all visual tokens of each frame into a limited number). However, this approach often neglects the uneven temporal distribution of critical information across frames, risking the omission of keyframes that contain essential temporal and semantic details. To tackle these challenges, we propose KFFocus, a method designed to efficiently compress video tokens and emphasize the informative context present within video frames. We substitute uniform sampling with a refined approach inspired by classic video compression principles to identify and capture keyframes based on their temporal redundancy. By assigning varying condensation ratios to frames based on their contextual relevance, KFFocus efficiently reduces token redundancy while preserving informative content details. Additionally, we introduce a spatiotemporal modeling module that encodes both the temporal relationships between video frames and the spatial structure within each frame, thus providing Vid-LLMs with a nuanced understanding of spatial-temporal dynamics. Extensive experiments on widely recognized video understanding benchmarks, especially long video scenarios, demonstrate that KFFocus significantly outperforms existing methods, achieving substantial computational efficiency and enhanced accuracy.
ILLUME+: Illuminating Unified MLLM with Dual Visual Tokenization and Diffusion Refinement
Apr 03, 2025



We present ILLUME+ that leverages dual visual tokenization and a diffusion decoder to improve both deep semantic understanding and high-fidelity image generation. Existing unified models have struggled to simultaneously handle the three fundamental capabilities in a unified model: understanding, generation, and editing. Models like Chameleon and EMU3 utilize VQGAN for image discretization, due to the lack of deep semantic interaction, they lag behind specialist models like LLaVA in visual understanding tasks. To mitigate this, LaViT and ILLUME employ semantic encoders for tokenization, but they struggle with image editing due to poor texture preservation. Meanwhile, Janus series decouples the input and output image representation, limiting their abilities to seamlessly handle interleaved image-text understanding and generation. In contrast, ILLUME+ introduces a unified dual visual tokenizer, DualViTok, which preserves both fine-grained textures and text-aligned semantics while enabling a coarse-to-fine image representation strategy for multimodal understanding and generation. Additionally, we employ a diffusion model as the image detokenizer for enhanced generation quality and efficient super-resolution. ILLUME+ follows a continuous-input, discrete-output scheme within the unified MLLM and adopts a progressive training procedure that supports dynamic resolution across the vision tokenizer, MLLM, and diffusion decoder. This design allows for flexible and efficient context-aware image editing and generation across diverse tasks. ILLUME+ (3B) exhibits competitive performance against existing unified MLLMs and specialized models across multimodal understanding, generation, and editing benchmarks. With its strong performance, ILLUME+ provides a scalable and versatile foundation for future multimodal applications. Project Page: https://illume-unified-mllm.github.io/.
SemHiTok: A Unified Image Tokenizer via Semantic-Guided Hierarchical Codebook for Multimodal Understanding and Generation
Mar 09, 2025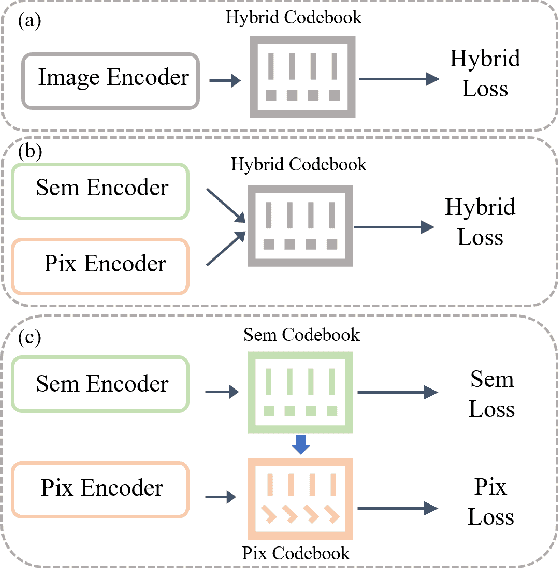
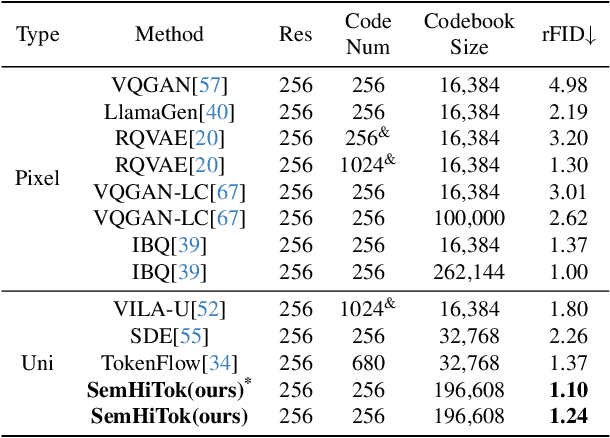
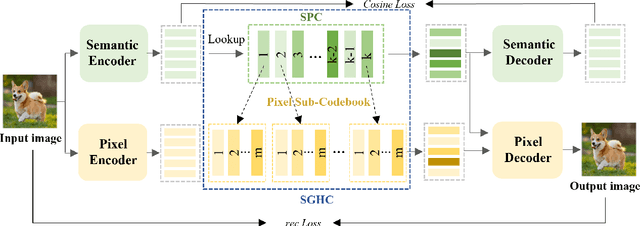
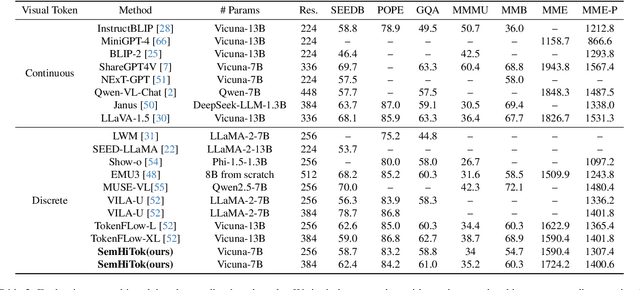
We present SemHiTok, a unified image Tokenizer via Semantic-Guided Hierarchical codebook that provides consistent discrete feature representations for multimodal understanding and generation tasks. Recently, unified multimodal large models (MLLMs) for understanding and generation have sparked exploration within research community. Previous works attempt to train a unified image tokenizer by combining loss functions for semantic feature reconstruction and pixel reconstruction. However, due to the differing levels of features prioritized by multimodal understanding and generation tasks, joint training methods face significant challenges in achieving a good trade-off. SemHiTok addresses this challenge through Semantic-Guided Hierarchical codebook which builds texture sub-codebooks on pre-trained semantic codebook. This design decouples the training of semantic reconstruction and pixel reconstruction and equips the tokenizer with low-level texture feature extraction capability without degradation of high-level semantic feature extraction ability. Our experiments demonstrate that SemHiTok achieves state-of-the-art rFID score at 256X256resolution compared to other unified tokenizers, and exhibits competitive performance on multimodal understanding and generation tasks.
FreqPrior: Improving Video Diffusion Models with Frequency Filtering Gaussian Noise
Feb 05, 2025

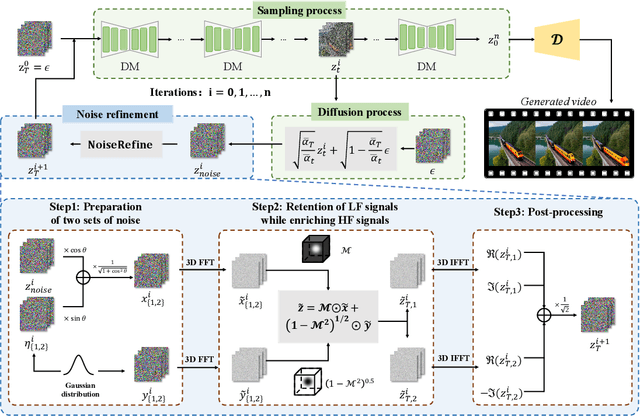

Text-driven video generation has advanced significantly due to developments in diffusion models. Beyond the training and sampling phases, recent studies have investigated noise priors of diffusion models, as improved noise priors yield better generation results. One recent approach employs the Fourier transform to manipulate noise, marking the initial exploration of frequency operations in this context. However, it often generates videos that lack motion dynamics and imaging details. In this work, we provide a comprehensive theoretical analysis of the variance decay issue present in existing methods, contributing to the loss of details and motion dynamics. Recognizing the critical impact of noise distribution on generation quality, we introduce FreqPrior, a novel noise initialization strategy that refines noise in the frequency domain. Our method features a novel filtering technique designed to address different frequency signals while maintaining the noise prior distribution that closely approximates a standard Gaussian distribution. Additionally, we propose a partial sampling process by perturbing the latent at an intermediate timestep during finding the noise prior, significantly reducing inference time without compromising quality. Extensive experiments on VBench demonstrate that our method achieves the highest scores in both quality and semantic assessments, resulting in the best overall total score. These results highlight the superiority of our proposed noise prior.
Brick-Diffusion: Generating Long Videos with Brick-to-Wall Denoising
Jan 06, 2025



Recent advances in diffusion models have greatly improved text-driven video generation. However, training models for long video generation demands significant computational power and extensive data, leading most video diffusion models to be limited to a small number of frames. Existing training-free methods that attempt to generate long videos using pre-trained short video diffusion models often struggle with issues such as insufficient motion dynamics and degraded video fidelity. In this paper, we present Brick-Diffusion, a novel, training-free approach capable of generating long videos of arbitrary length. Our method introduces a brick-to-wall denoising strategy, where the latent is denoised in segments, with a stride applied in subsequent iterations. This process mimics the construction of a staggered brick wall, where each brick represents a denoised segment, enabling communication between frames and improving overall video quality. Through quantitative and qualitative evaluations, we demonstrate that Brick-Diffusion outperforms existing baseline methods in generating high-fidelity videos.
ILLUME: Illuminating Your LLMs to See, Draw, and Self-Enhance
Dec 09, 2024In this paper, we introduce ILLUME, a unified multimodal large language model (MLLM) that seamlessly integrates multimodal understanding and generation capabilities within a single large language model through a unified next-token prediction formulation. To address the large dataset size typically required for image-text alignment, we propose to enhance data efficiency through the design of a vision tokenizer that incorporates semantic information and a progressive multi-stage training procedure. This approach reduces the dataset size to just 15M for pretraining -- over four times fewer than what is typically needed -- while achieving competitive or even superior performance with existing unified MLLMs, such as Janus. Additionally, to promote synergistic enhancement between understanding and generation capabilities, which is under-explored in previous works, we introduce a novel self-enhancing multimodal alignment scheme. This scheme supervises the MLLM to self-assess the consistency between text descriptions and self-generated images, facilitating the model to interpret images more accurately and avoid unrealistic and incorrect predictions caused by misalignment in image generation. Based on extensive experiments, our proposed ILLUME stands out and competes with state-of-the-art unified MLLMs and specialized models across various benchmarks for multimodal understanding, generation, and editing.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024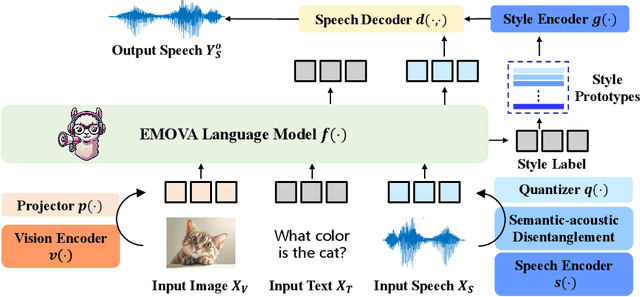
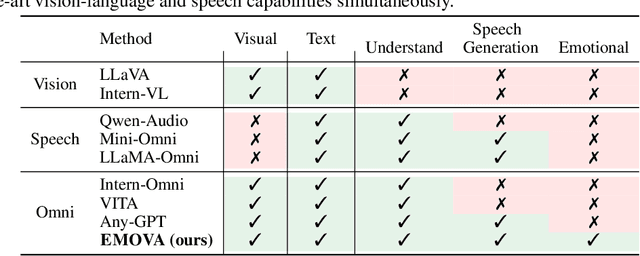
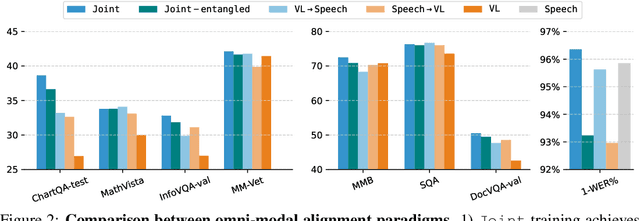

GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.