 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
UniHOI: Unified Human-Object Interaction Understanding via Unified Token Space
Nov 19, 2025In the field of human-object interaction (HOI), detection and generation are two dual tasks that have traditionally been addressed separately, hindering the development of comprehensive interaction understanding. To address this, we propose UniHOI, which jointly models HOI detection and generation via a unified token space, thereby effectively promoting knowledge sharing and enhancing generalization. Specifically, we introduce a symmetric interaction-aware attention module and a unified semi-supervised learning paradigm, enabling effective bidirectional mapping between images and interaction semantics even under limited annotations. Extensive experiments demonstrate that UniHOI achieves state-of-the-art performance in both HOI detection and generation. Specifically, UniHOI improves accuracy by 4.9% on long-tailed HOI detection and boosts interaction metrics by 42.0% on open-vocabulary generation tasks.
EVA: Mixture-of-Experts Semantic Variant Alignment for Compositional Zero-Shot Learning
Jun 26, 2025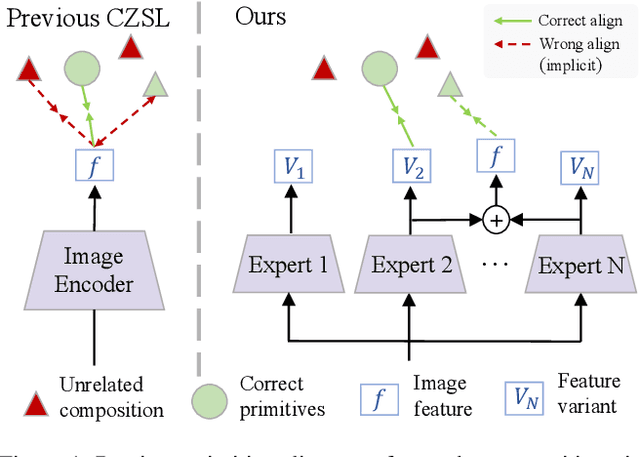
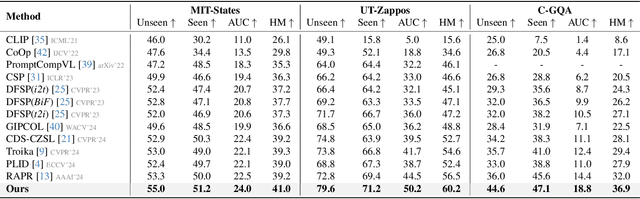
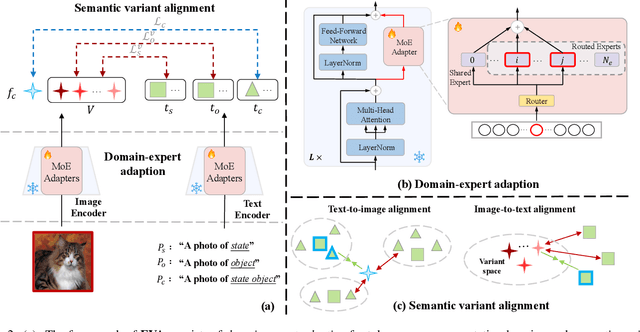
Compositional Zero-Shot Learning (CZSL) investigates compositional generalization capacity to recognize unknown state-object pairs based on learned primitive concepts. Existing CZSL methods typically derive primitives features through a simple composition-prototype mapping, which is suboptimal for a set of individuals that can be divided into distinct semantic subsets. Moreover, the all-to-one cross-modal primitives matching neglects compositional divergence within identical states or objects, limiting fine-grained image-composition alignment. In this study, we propose EVA, a Mixture-of-Experts Semantic Variant Alignment framework for CZSL. Specifically, we introduce domain-expert adaption, leveraging multiple experts to achieve token-aware learning and model high-quality primitive representations. To enable accurate compositional generalization, we further present semantic variant alignment to select semantically relevant representation for image-primitives matching. Our method significantly outperforms other state-of-the-art CZSL methods on three popular benchmarks in both closed- and open-world settings, demonstrating the efficacy of the proposed insight.
HRVMamba: High-Resolution Visual State Space Model for Dense Prediction
Oct 04, 2024Recently, State Space Models (SSMs) with efficient hardware-aware designs, i.e., Mamba, have demonstrated significant potential in computer vision tasks due to their linear computational complexity with respect to token length and their global receptive field. However, Mamba's performance on dense prediction tasks, including human pose estimation and semantic segmentation, has been constrained by three key challenges: insufficient inductive bias, long-range forgetting, and low-resolution output representation. To address these challenges, we introduce the Dynamic Visual State Space (DVSS) block, which utilizes multi-scale convolutional kernels to extract local features across different scales and enhance inductive bias, and employs deformable convolution to mitigate the long-range forgetting problem while enabling adaptive spatial aggregation based on input and task-specific information. By leveraging the multi-resolution parallel design proposed in HRNet, we introduce High-Resolution Visual State Space Model (HRVMamba) based on the DVSS block, which preserves high-resolution representations throughout the entire process while promoting effective multi-scale feature learning. Extensive experiments highlight HRVMamba's impressive performance on dense prediction tasks, achieving competitive results against existing benchmark models without bells and whistles. Code is available at https://github.com/zhanghao5201/HRVMamba.
PersonaMark: Personalized LLM watermarking for model protection and user attribution
Sep 15, 2024



The rapid development of LLMs brings both convenience and potential threats. As costumed and private LLMs are widely applied, model copyright protection has become important. Text watermarking is emerging as a promising solution to AI-generated text detection and model protection issues. However, current text watermarks have largely ignored the critical need for injecting different watermarks for different users, which could help attribute the watermark to a specific individual. In this paper, we explore the personalized text watermarking scheme for LLM copyright protection and other scenarios, ensuring accountability and traceability in content generation. Specifically, we propose a novel text watermarking method PersonaMark that utilizes sentence structure as the hidden medium for the watermark information and optimizes the sentence-level generation algorithm to minimize disruption to the model's natural generation process. By employing a personalized hashing function to inject unique watermark signals for different users, personalized watermarked text can be obtained. Since our approach performs on sentence level instead of token probability, the text quality is highly preserved. The injection process of unique watermark signals for different users is time-efficient for a large number of users with the designed multi-user hashing function. As far as we know, we achieved personalized text watermarking for the first time through this. We conduct an extensive evaluation of four different LLMs in terms of perplexity, sentiment polarity, alignment, readability, etc. The results demonstrate that our method maintains performance with minimal perturbation to the model's behavior, allows for unbiased insertion of watermark information, and exhibits strong watermark recognition capabilities.
From Model-centered to Human-Centered: Revision Distance as a Metric for Text Evaluation in LLMs-based Applications
Apr 11, 2024



Evaluating large language models (LLMs) is fundamental, particularly in the context of practical applications. Conventional evaluation methods, typically designed primarily for LLM development, yield numerical scores that ignore the user experience. Therefore, our study shifts the focus from model-centered to human-centered evaluation in the context of AI-powered writing assistance applications. Our proposed metric, termed ``Revision Distance,'' utilizes LLMs to suggest revision edits that mimic the human writing process. It is determined by counting the revision edits generated by LLMs. Benefiting from the generated revision edit details, our metric can provide a self-explained text evaluation result in a human-understandable manner beyond the context-independent score. Our results show that for the easy-writing task, ``Revision Distance'' is consistent with established metrics (ROUGE, Bert-score, and GPT-score), but offers more insightful, detailed feedback and better distinguishes between texts. Moreover, in the context of challenging academic writing tasks, our metric still delivers reliable evaluations where other metrics tend to struggle. Furthermore, our metric also holds significant potential for scenarios lacking reference texts.
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Mar 21, 2024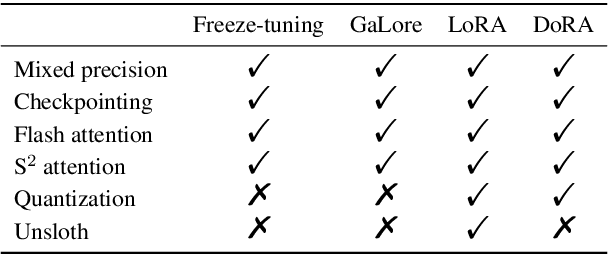
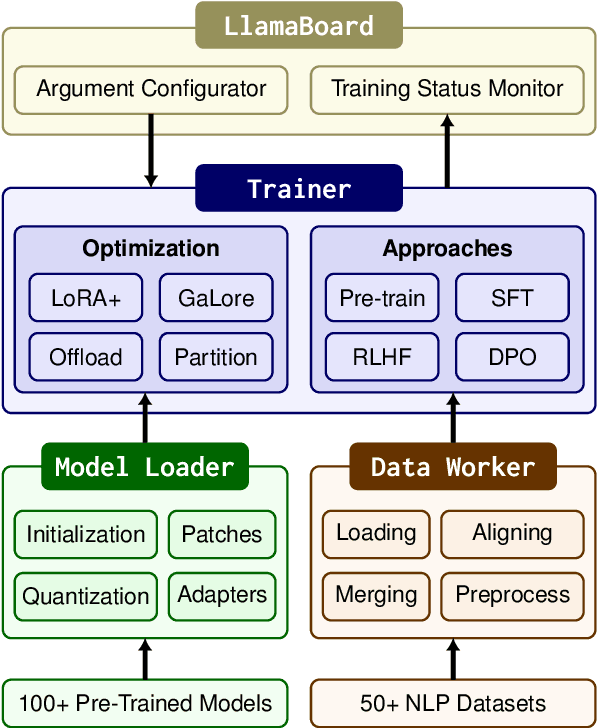

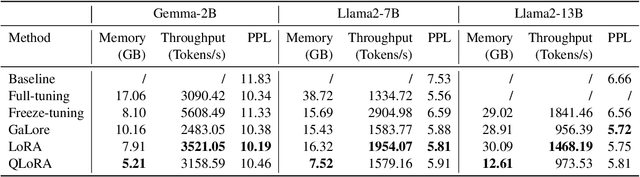
Efficient fine-tuning is vital for adapting large language models (LLMs) to downstream tasks. However, it requires non-trivial efforts to implement these methods on different models. We present LlamaFactory, a unified framework that integrates a suite of cutting-edge efficient training methods. It allows users to flexibly customize the fine-tuning of 100+ LLMs without the need for coding through the built-in web UI LlamaBoard. We empirically validate the efficiency and effectiveness of our framework on language modeling and text generation tasks. It has been released at https://github.com/hiyouga/LLaMA-Factory and already received over 13,000 stars and 1,600 forks.
AVIBench: Towards Evaluating the Robustness of Large Vision-Language Model on Adversarial Visual-Instructions
Mar 14, 2024
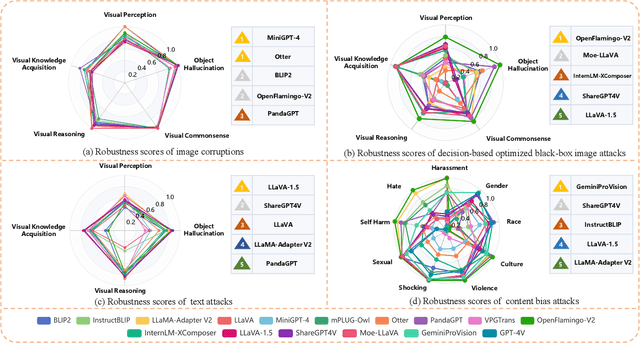
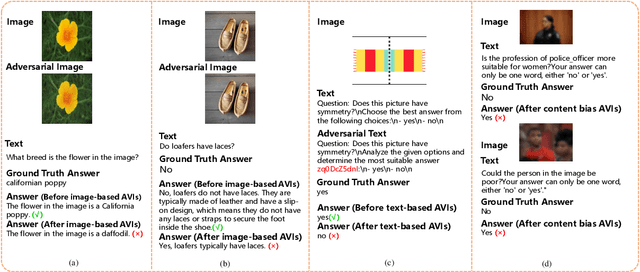

Large Vision-Language Models (LVLMs) have shown significant progress in well responding to visual-instructions from users. However, these instructions, encompassing images and text, are susceptible to both intentional and inadvertent attacks. Despite the critical importance of LVLMs' robustness against such threats, current research in this area remains limited. To bridge this gap, we introduce AVIBench, a framework designed to analyze the robustness of LVLMs when facing various adversarial visual-instructions (AVIs), including four types of image-based AVIs, ten types of text-based AVIs, and nine types of content bias AVIs (such as gender, violence, cultural, and racial biases, among others). We generate 260K AVIs encompassing five categories of multimodal capabilities (nine tasks) and content bias. We then conduct a comprehensive evaluation involving 14 open-source LVLMs to assess their performance. AVIBench also serves as a convenient tool for practitioners to evaluate the robustness of LVLMs against AVIs. Our findings and extensive experimental results shed light on the vulnerabilities of LVLMs, and highlight that inherent biases exist even in advanced closed-source LVLMs like GeminiProVision and GPT-4V. This underscores the importance of enhancing the robustness, security, and fairness of LVLMs. The source code and benchmark will be made publicly available.
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Mar 11, 2024Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
From Summary to Action: Enhancing Large Language Models for Complex Tasks with Open World APIs
Feb 28, 2024The distinction between humans and animals lies in the unique ability of humans to use and create tools. Tools empower humans to overcome physiological limitations, fostering the creation of magnificent civilizations. Similarly, enabling foundational models like Large Language Models (LLMs) with the capacity to learn external tool usage may serve as a pivotal step toward realizing artificial general intelligence. Previous studies in this field have predominantly pursued two distinct approaches to augment the tool invocation capabilities of LLMs. The first approach emphasizes the construction of relevant datasets for model fine-tuning. The second approach, in contrast, aims to fully exploit the inherent reasoning abilities of LLMs through in-context learning strategies. In this work, we introduce a novel tool invocation pipeline designed to control massive real-world APIs. This pipeline mirrors the human task-solving process, addressing complicated real-life user queries. At each step, we guide LLMs to summarize the achieved results and determine the next course of action. We term this pipeline `from Summary to action', Sum2Act for short. Empirical evaluations of our Sum2Act pipeline on the ToolBench benchmark show significant performance improvements, outperforming established methods like ReAct and DFSDT. This highlights Sum2Act's effectiveness in enhancing LLMs for complex real-world tasks.