 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Resolving Manifold Misalignment in Visual Tokenization via Topological Orthogonality
May 07, 2026Unified visual tokenization faces a fundamental trade-off between high-fidelity pixel reconstruction (spatial equivariance) and semantic abstraction (conceptual invariance). We attribute this conflict to Manifold Misalignment: naive joint optimization induces opposing gradients, creating a zero-sum game between reconstruction and perception. To address this, we propose MUSE, a framework based on Topological Orthogonality. By treating Structure as an orthogonal bridge, MUSE decouples optimization within Transformers: structural gradients refine attention topology, while semantic gradients update feature values. This turns destructive interference into Mutual Reinforcement. Experiments show that MUSE breaks the trade-off, achieving state-of-the-art generation quality (gFID 3.08) and surpassing its teacher InternViT-300M in linear probing (85.2\% vs. 82.5\%), demonstrating that structurally aligned reconstruction can enhance semantic perception. Code is available at https://github.com/PanqiYang1/MUSE.
Breakthrough the Suboptimal Stable Point in Value-Factorization-Based Multi-Agent Reinforcement Learning
Apr 07, 2026Value factorization, a popular paradigm in MARL, faces significant theoretical and algorithmic bottlenecks: its tendency to converge to suboptimal solutions remains poorly understood and unsolved. Theoretically, existing analyses fail to explain this due to their primary focus on the optimal case. To bridge this gap, we introduce a novel theoretical concept: the stable point, which characterizes the potential convergence of value factorization in general cases. Through an analysis of stable point distributions in existing methods, we reveal that non-optimal stable points are the primary cause of poor performance. However, algorithmically, making the optimal action the unique stable point is nearly infeasible. In contrast, iteratively filtering suboptimal actions by rendering them unstable emerges as a more practical approach for global optimality. Inspired by this, we propose a novel Multi-Round Value Factorization (MRVF) framework. Specifically, by measuring a non-negative payoff increment relative to the previously selected action, MRVF transforms inferior actions into unstable points, thereby driving each iteration toward a stable point with a superior action. Experiments on challenging benchmarks, including predator-prey tasks and StarCraft II Multi-Agent Challenge (SMAC), validate our analysis of stable points and demonstrate the superiority of MRVF over state-of-the-art methods.
This Looks Distinctly Like That: Grounding Interpretable Recognition in Stiefel Geometry against Neural Collapse
Mar 09, 2026Prototype networks provide an intrinsic case based explanation mechanism, but their interpretability is often undermined by prototype collapse, where multiple prototypes degenerate to highly redundant evidence. We attribute this failure mode to the terminal dynamics of Neural Collapse, where cross entropy optimization suppresses intra class variance and drives class conditional features toward a low dimensional limit. To mitigate this, we propose Adaptive Manifold Prototypes (AMP), a framework that leverages Riemannian optimization on the Stiefel manifold to represent class prototypes as orthonormal bases and make rank one prototype collapse infeasible by construction. AMP further learns class specific effective rank via a proximal gradient update on a nonnegative capacity vector, and introduces spatial regularizers that reduce rotational ambiguity and encourage localized, non overlapping part evidence. Extensive experiments on fine-grained benchmarks demonstrate that AMP achieves state-of-the-art classification accuracy while significantly improving causal faithfulness over prior interpretable models.
Unsupervised Causal Prototypical Networks for De-biased Interpretable Dermoscopy Diagnosis
Feb 27, 2026Despite the success of deep learning in dermoscopy image analysis, its inherent black-box nature hinders clinical trust, motivating the use of prototypical networks for case-based visual transparency. However, inevitable selection bias in clinical data often drives these models toward shortcut learning, where environmental confounders are erroneously encoded as predictive prototypes, generating spurious visual evidence that misleads medical decision-making. To mitigate these confounding effects, we propose CausalProto, an Unsupervised Causal Prototypical Network that fundamentally purifies the visual evidence chain. Framed within a Structural Causal Model, we employ an Information Bottleneck-constrained encoder to enforce strict unsupervised orthogonal disentanglement between pathological features and environmental confounders. By mapping these decoupled representations into independent prototypical spaces, we leverage the learned spurious dictionary to perform backdoor adjustment via do-calculus, transforming complex causal interventions into efficient expectation pooling to marginalize environmental noise. Extensive experiments on multiple dermoscopy datasets demonstrate that CausalProto achieves superior diagnostic performance and consistently outperforms standard black box models, while simultaneously providing transparent and high purity visual interpretability without suffering from the traditional accuracy compromise.
OmniVideo-R1: Reinforcing Audio-visual Reasoning with Query Intention and Modality Attention
Feb 05, 2026While humans perceive the world through diverse modalities that operate synergistically to support a holistic understanding of their surroundings, existing omnivideo models still face substantial challenges on audio-visual understanding tasks. In this paper, we propose OmniVideo-R1, a novel reinforced framework that improves mixed-modality reasoning. OmniVideo-R1 empowers models to "think with omnimodal cues" by two key strategies: (1) query-intensive grounding based on self-supervised learning paradigms; and (2) modality-attentive fusion built upon contrastive learning paradigms. Extensive experiments on multiple benchmarks demonstrate that OmniVideo-R1 consistently outperforms strong baselines, highlighting its effectiveness and robust generalization capabilities.
We Need a More Robust Classifier: Dual Causal Learning Empowers Domain-Incremental Time Series Classification
Jan 15, 2026The World Wide Web thrives on intelligent services that rely on accurate time series classification, which has recently witnessed significant progress driven by advances in deep learning. However, existing studies face challenges in domain incremental learning. In this paper, we propose a lightweight and robust dual-causal disentanglement framework (DualCD) to enhance the robustness of models under domain incremental scenarios, which can be seamlessly integrated into time series classification models. Specifically, DualCD first introduces a temporal feature disentanglement module to capture class-causal features and spurious features. The causal features can offer sufficient predictive power to support the classifier in domain incremental learning settings. To accurately capture these causal features, we further design a dual-causal intervention mechanism to eliminate the influence of both intra-class and inter-class confounding features. This mechanism constructs variant samples by combining the current class's causal features with intra-class spurious features and with causal features from other classes. The causal intervention loss encourages the model to accurately predict the labels of these variant samples based solely on the causal features. Extensive experiments on multiple datasets and models demonstrate that DualCD effectively improves performance in domain incremental scenarios. We summarize our rich experiments into a comprehensive benchmark to facilitate research in domain incremental time series classification.
UniHOI: Unified Human-Object Interaction Understanding via Unified Token Space
Nov 19, 2025In the field of human-object interaction (HOI), detection and generation are two dual tasks that have traditionally been addressed separately, hindering the development of comprehensive interaction understanding. To address this, we propose UniHOI, which jointly models HOI detection and generation via a unified token space, thereby effectively promoting knowledge sharing and enhancing generalization. Specifically, we introduce a symmetric interaction-aware attention module and a unified semi-supervised learning paradigm, enabling effective bidirectional mapping between images and interaction semantics even under limited annotations. Extensive experiments demonstrate that UniHOI achieves state-of-the-art performance in both HOI detection and generation. Specifically, UniHOI improves accuracy by 4.9% on long-tailed HOI detection and boosts interaction metrics by 42.0% on open-vocabulary generation tasks.
EVA: Mixture-of-Experts Semantic Variant Alignment for Compositional Zero-Shot Learning
Jun 26, 2025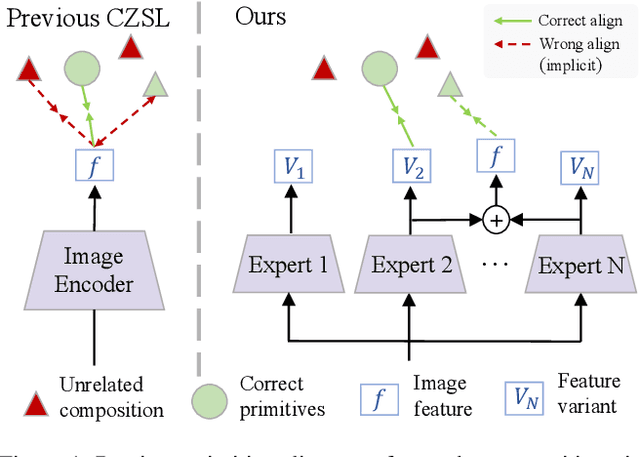
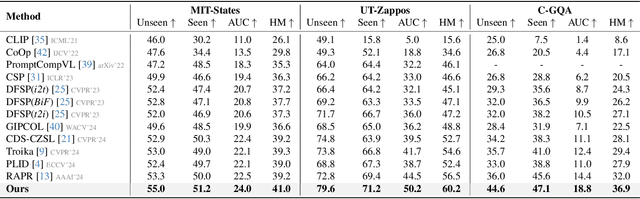
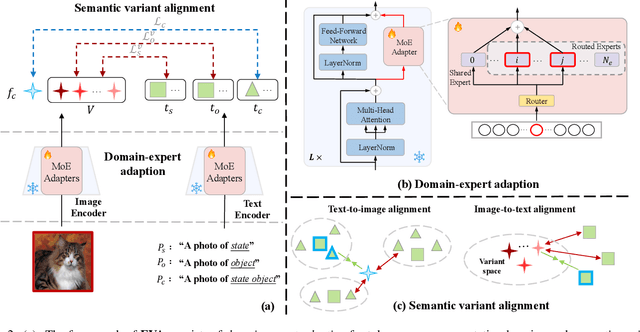
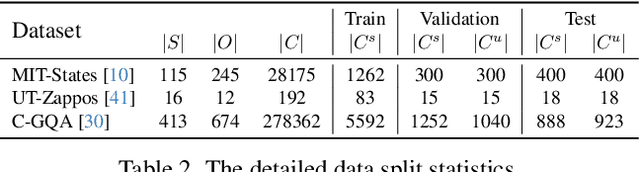
Compositional Zero-Shot Learning (CZSL) investigates compositional generalization capacity to recognize unknown state-object pairs based on learned primitive concepts. Existing CZSL methods typically derive primitives features through a simple composition-prototype mapping, which is suboptimal for a set of individuals that can be divided into distinct semantic subsets. Moreover, the all-to-one cross-modal primitives matching neglects compositional divergence within identical states or objects, limiting fine-grained image-composition alignment. In this study, we propose EVA, a Mixture-of-Experts Semantic Variant Alignment framework for CZSL. Specifically, we introduce domain-expert adaption, leveraging multiple experts to achieve token-aware learning and model high-quality primitive representations. To enable accurate compositional generalization, we further present semantic variant alignment to select semantically relevant representation for image-primitives matching. Our method significantly outperforms other state-of-the-art CZSL methods on three popular benchmarks in both closed- and open-world settings, demonstrating the efficacy of the proposed insight.
AttenST: A Training-Free Attention-Driven Style Transfer Framework with Pre-Trained Diffusion Models
Mar 10, 2025While diffusion models have achieved remarkable progress in style transfer tasks, existing methods typically rely on fine-tuning or optimizing pre-trained models during inference, leading to high computational costs and challenges in balancing content preservation with style integration. To address these limitations, we introduce AttenST, a training-free attention-driven style transfer framework. Specifically, we propose a style-guided self-attention mechanism that conditions self-attention on the reference style by retaining the query of the content image while substituting its key and value with those from the style image, enabling effective style feature integration. To mitigate style information loss during inversion, we introduce a style-preserving inversion strategy that refines inversion accuracy through multiple resampling steps. Additionally, we propose a content-aware adaptive instance normalization, which integrates content statistics into the normalization process to optimize style fusion while mitigating the content degradation. Furthermore, we introduce a dual-feature cross-attention mechanism to fuse content and style features, ensuring a harmonious synthesis of structural fidelity and stylistic expression. Extensive experiments demonstrate that AttenST outperforms existing methods, achieving state-of-the-art performance in style transfer dataset.
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Mar 11, 2024Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.