 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation
Mar 10, 2025Existing long-text generation methods primarily concentrate on producing lengthy texts from short inputs, neglecting the long-input and long-output tasks. Such tasks have numerous practical applications while lacking available benchmarks. Moreover, as the input grows in length, existing methods inevitably encounter the "lost-in-the-middle" phenomenon. In this paper, we first introduce a Long Input and Output Benchmark (LongInOutBench), including a synthetic dataset and a comprehensive evaluation framework, addressing the challenge of the missing benchmark. We then develop the Retrieval-Augmented Long-Text Writer (RAL-Writer), which retrieves and restates important yet overlooked content, mitigating the "lost-in-the-middle" issue by constructing explicit prompts. We finally employ the proposed LongInOutBench to evaluate our RAL-Writer against comparable baselines, and the results demonstrate the effectiveness of our approach. Our code has been released at https://github.com/OnlyAR/RAL-Writer.
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Mar 21, 2024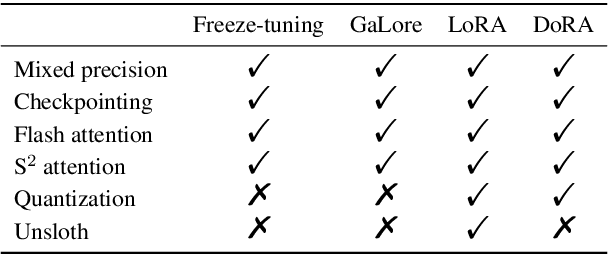
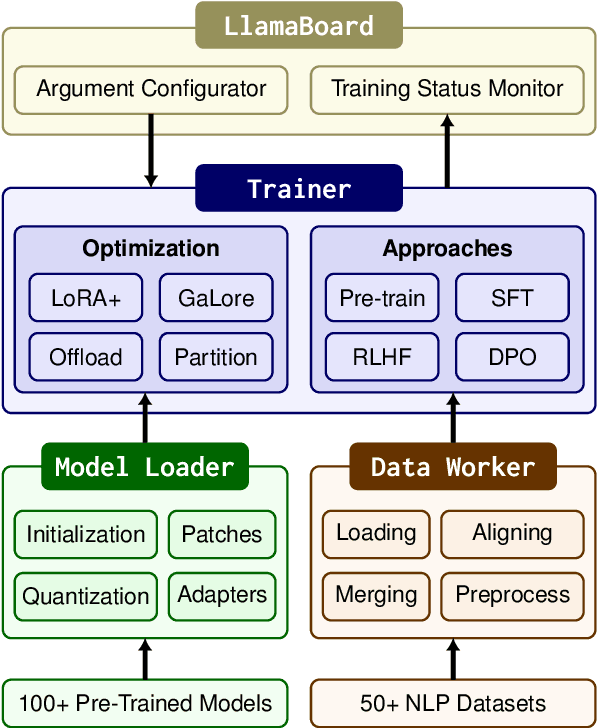

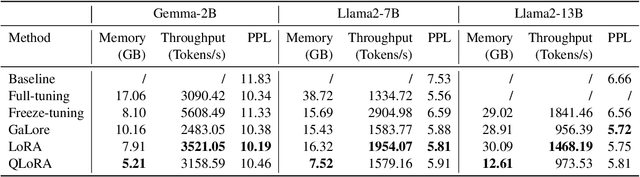
Efficient fine-tuning is vital for adapting large language models (LLMs) to downstream tasks. However, it requires non-trivial efforts to implement these methods on different models. We present LlamaFactory, a unified framework that integrates a suite of cutting-edge efficient training methods. It allows users to flexibly customize the fine-tuning of 100+ LLMs without the need for coding through the built-in web UI LlamaBoard. We empirically validate the efficiency and effectiveness of our framework on language modeling and text generation tasks. It has been released at https://github.com/hiyouga/LLaMA-Factory and already received over 13,000 stars and 1,600 forks.