 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
Native Visual Understanding: Resolving Resolution Dilemmas in Vision-Language Models
Jun 15, 2025



Vision-Language Models (VLMs) face significant challenges when dealing with the diverse resolutions and aspect ratios of real-world images, as most existing models rely on fixed, low-resolution inputs. While recent studies have explored integrating native resolution visual encoding to improve model performance, such efforts remain fragmented and lack a systematic framework within the open-source community. Moreover, existing benchmarks fall short in evaluating VLMs under varied visual conditions, often neglecting resolution as a critical factor. To address the "Resolution Dilemma" stemming from both model design and benchmark limitations, we introduce RC-Bench, a novel benchmark specifically designed to systematically evaluate VLM capabilities under extreme visual conditions, with an emphasis on resolution and aspect ratio variations. In conjunction, we propose NativeRes-LLaVA, an open-source training framework that empowers VLMs to effectively process images at their native resolutions and aspect ratios. Based on RC-Bench and NativeRes-LLaVA, we conduct comprehensive experiments on existing visual encoding strategies. The results show that Native Resolution Visual Encoding significantly improves the performance of VLMs on RC-Bench as well as other resolution-centric benchmarks. Code is available at https://github.com/Niujunbo2002/NativeRes-LLaVA.
Lost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation
Mar 10, 2025Existing long-text generation methods primarily concentrate on producing lengthy texts from short inputs, neglecting the long-input and long-output tasks. Such tasks have numerous practical applications while lacking available benchmarks. Moreover, as the input grows in length, existing methods inevitably encounter the "lost-in-the-middle" phenomenon. In this paper, we first introduce a Long Input and Output Benchmark (LongInOutBench), including a synthetic dataset and a comprehensive evaluation framework, addressing the challenge of the missing benchmark. We then develop the Retrieval-Augmented Long-Text Writer (RAL-Writer), which retrieves and restates important yet overlooked content, mitigating the "lost-in-the-middle" issue by constructing explicit prompts. We finally employ the proposed LongInOutBench to evaluate our RAL-Writer against comparable baselines, and the results demonstrate the effectiveness of our approach. Our code has been released at https://github.com/OnlyAR/RAL-Writer.
OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
Jan 09, 2025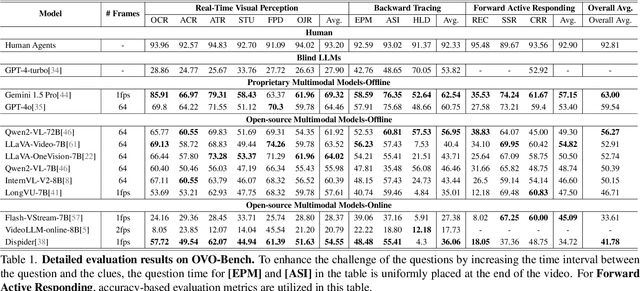
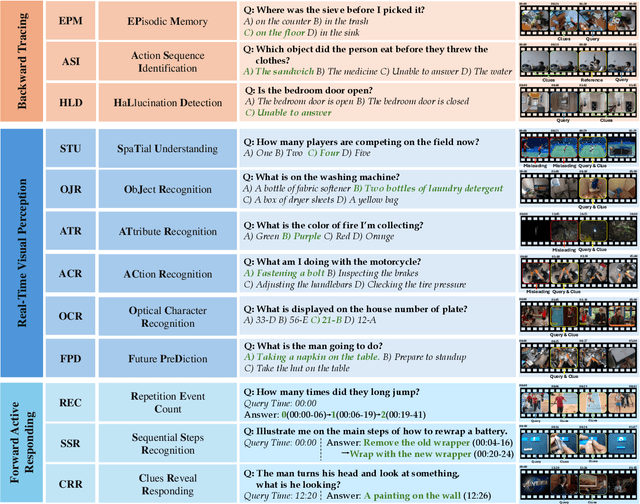
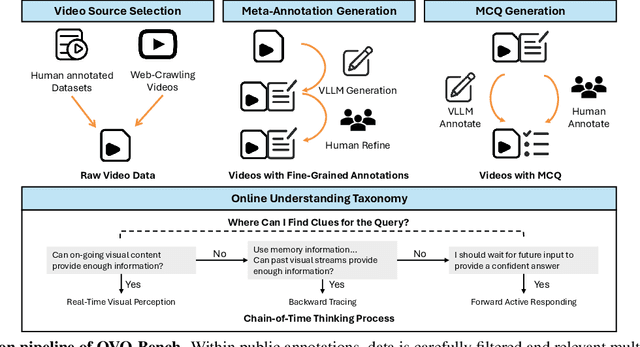
Temporal Awareness, the ability to reason dynamically based on the timestamp when a question is raised, is the key distinction between offline and online video LLMs. Unlike offline models, which rely on complete videos for static, post hoc analysis, online models process video streams incrementally and dynamically adapt their responses based on the timestamp at which the question is posed. Despite its significance, temporal awareness has not been adequately evaluated in existing benchmarks. To fill this gap, we present OVO-Bench (Online-VideO-Benchmark), a novel video benchmark that emphasizes the importance of timestamps for advanced online video understanding capability benchmarking. OVO-Bench evaluates the ability of video LLMs to reason and respond to events occurring at specific timestamps under three distinct scenarios: (1) Backward tracing: trace back to past events to answer the question. (2) Real-time understanding: understand and respond to events as they unfold at the current timestamp. (3) Forward active responding: delay the response until sufficient future information becomes available to answer the question accurately. OVO-Bench comprises 12 tasks, featuring 644 unique videos and approximately human-curated 2,800 fine-grained meta-annotations with precise timestamps. We combine automated generation pipelines with human curation. With these high-quality samples, we further developed an evaluation pipeline to systematically query video LLMs along the video timeline. Evaluations of nine Video-LLMs reveal that, despite advancements on traditional benchmarks, current models struggle with online video understanding, showing a significant gap compared to human agents. We hope OVO-Bench will drive progress in video LLMs and inspire future research in online video reasoning. Our benchmark and code can be accessed at https://github.com/JoeLeelyf/OVO-Bench.