 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Visual Understanding: Resolving Resolution Dilemmas in Vision-Language Models
Jun 15, 2025



Vision-Language Models (VLMs) face significant challenges when dealing with the diverse resolutions and aspect ratios of real-world images, as most existing models rely on fixed, low-resolution inputs. While recent studies have explored integrating native resolution visual encoding to improve model performance, such efforts remain fragmented and lack a systematic framework within the open-source community. Moreover, existing benchmarks fall short in evaluating VLMs under varied visual conditions, often neglecting resolution as a critical factor. To address the "Resolution Dilemma" stemming from both model design and benchmark limitations, we introduce RC-Bench, a novel benchmark specifically designed to systematically evaluate VLM capabilities under extreme visual conditions, with an emphasis on resolution and aspect ratio variations. In conjunction, we propose NativeRes-LLaVA, an open-source training framework that empowers VLMs to effectively process images at their native resolutions and aspect ratios. Based on RC-Bench and NativeRes-LLaVA, we conduct comprehensive experiments on existing visual encoding strategies. The results show that Native Resolution Visual Encoding significantly improves the performance of VLMs on RC-Bench as well as other resolution-centric benchmarks. Code is available at https://github.com/Niujunbo2002/NativeRes-LLaVA.
OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
Jan 09, 2025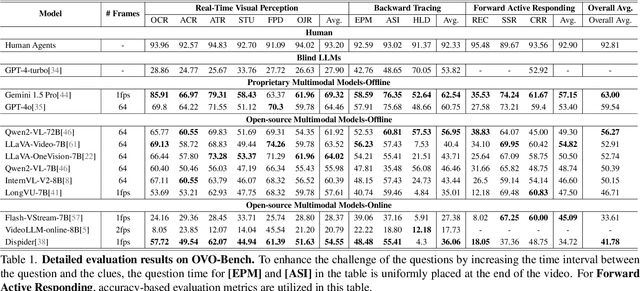
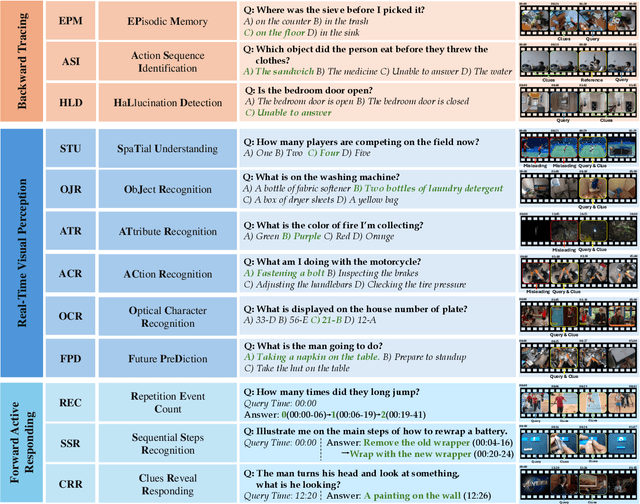
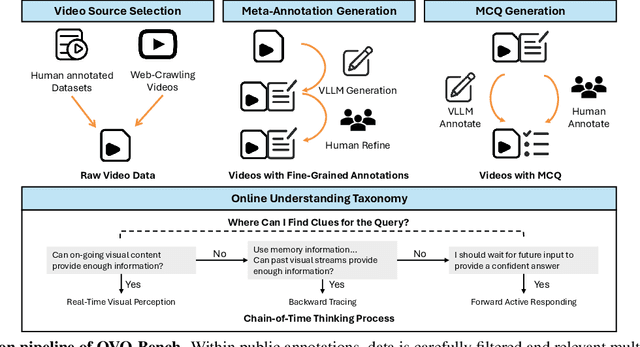
Temporal Awareness, the ability to reason dynamically based on the timestamp when a question is raised, is the key distinction between offline and online video LLMs. Unlike offline models, which rely on complete videos for static, post hoc analysis, online models process video streams incrementally and dynamically adapt their responses based on the timestamp at which the question is posed. Despite its significance, temporal awareness has not been adequately evaluated in existing benchmarks. To fill this gap, we present OVO-Bench (Online-VideO-Benchmark), a novel video benchmark that emphasizes the importance of timestamps for advanced online video understanding capability benchmarking. OVO-Bench evaluates the ability of video LLMs to reason and respond to events occurring at specific timestamps under three distinct scenarios: (1) Backward tracing: trace back to past events to answer the question. (2) Real-time understanding: understand and respond to events as they unfold at the current timestamp. (3) Forward active responding: delay the response until sufficient future information becomes available to answer the question accurately. OVO-Bench comprises 12 tasks, featuring 644 unique videos and approximately human-curated 2,800 fine-grained meta-annotations with precise timestamps. We combine automated generation pipelines with human curation. With these high-quality samples, we further developed an evaluation pipeline to systematically query video LLMs along the video timeline. Evaluations of nine Video-LLMs reveal that, despite advancements on traditional benchmarks, current models struggle with online video understanding, showing a significant gap compared to human agents. We hope OVO-Bench will drive progress in video LLMs and inspire future research in online video reasoning. Our benchmark and code can be accessed at https://github.com/JoeLeelyf/OVO-Bench.
T2Vid: Translating Long Text into Multi-Image is the Catalyst for Video-LLMs
Dec 02, 2024



The success of Multimodal Large Language Models (MLLMs) in the image domain has garnered wide attention from the research community. Drawing on previous successful experiences, researchers have recently explored extending the success to the video understanding realms. Apart from training from scratch, an efficient way is to utilize the pre-trained image-LLMs, leading to two mainstream approaches, i.e. zero-shot inference and further fine-tuning with video data. In this work, our study of these approaches harvests an effective data augmentation method. We first make a deeper inspection of the zero-shot inference way and identify two limitations, i.e. limited generalization and lack of temporal understanding capabilities. Thus, we further investigate the fine-tuning approach and find a low learning efficiency when simply using all the video data samples, which can be attributed to a lack of instruction diversity. Aiming at this issue, we develop a method called T2Vid to synthesize video-like samples to enrich the instruction diversity in the training corpus. Integrating these data enables a simple and efficient training scheme, which achieves performance comparable to or even superior to using full video datasets by training with just 15% the sample size. Meanwhile, we find that the proposed scheme can boost the performance of long video understanding without training with long video samples. We hope our study will spark more thinking about using MLLMs for video understanding and curation of high-quality data. The code is released at https://github.com/xjtupanda/T2Vid.
Everything to the Synthetic: Diffusion-driven Test-time Adaptation via Synthetic-Domain Alignment
Jun 06, 2024



Test-time adaptation (TTA) aims to enhance the performance of source-domain pretrained models when tested on unknown shifted target domains. Traditional TTA methods primarily adapt model weights based on target data streams, making model performance sensitive to the amount and order of target data. Recently, diffusion-driven TTA methods have demonstrated strong performance by using an unconditional diffusion model, which is also trained on the source domain to transform target data into synthetic data as a source domain projection. This allows the source model to make predictions without weight adaptation. In this paper, we argue that the domains of the source model and the synthetic data in diffusion-driven TTA methods are not aligned. To adapt the source model to the synthetic domain of the unconditional diffusion model, we introduce a Synthetic-Domain Alignment (SDA) framework to fine-tune the source model with synthetic data. Specifically, we first employ a conditional diffusion model to generate labeled samples, creating a synthetic dataset. Subsequently, we use the aforementioned unconditional diffusion model to add noise to and denoise each sample before fine-tuning. This process mitigates the potential domain gap between the conditional and unconditional models. Extensive experiments across various models and benchmarks demonstrate that SDA achieves superior domain alignment and consistently outperforms existing diffusion-driven TTA methods. Our code is available at https://github.com/SHI-Labs/Diffusion-Driven-Test-Time-Adaptation-via-Synthetic-Domain-Alignment.
Demystify Mamba in Vision: A Linear Attention Perspective
May 26, 2024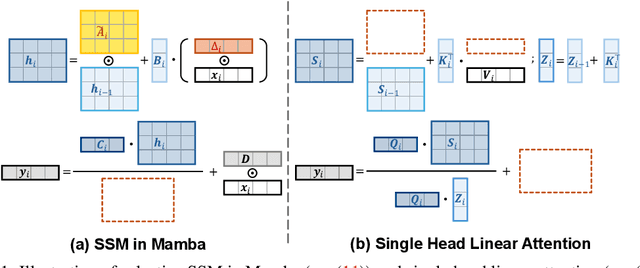
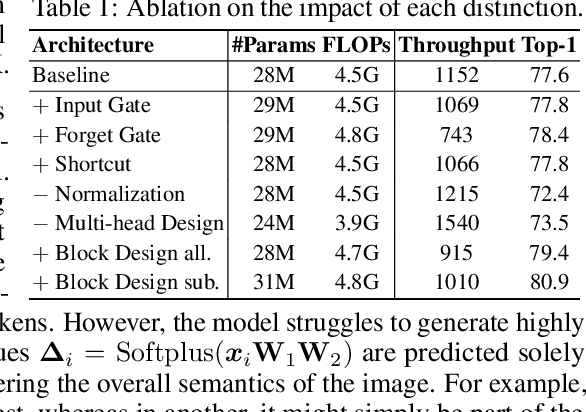
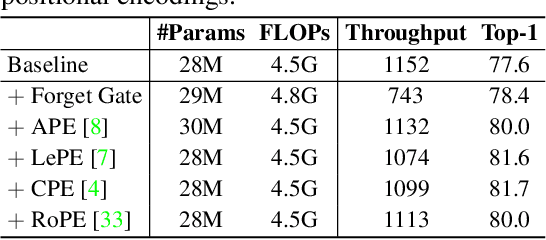
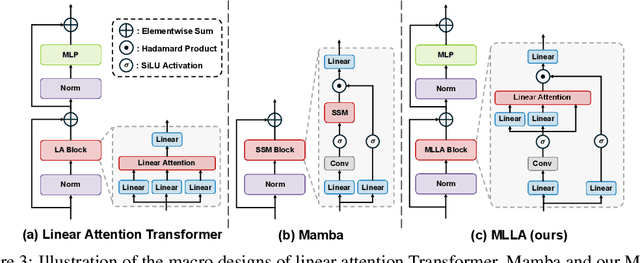
Mamba is an effective state space model with linear computation complexity. It has recently shown impressive efficiency in dealing with high-resolution inputs across various vision tasks. In this paper, we reveal that the powerful Mamba model shares surprising similarities with linear attention Transformer, which typically underperform conventional Transformer in practice. By exploring the similarities and disparities between the effective Mamba and subpar linear attention Transformer, we provide comprehensive analyses to demystify the key factors behind Mamba's success. Specifically, we reformulate the selective state space model and linear attention within a unified formulation, rephrasing Mamba as a variant of linear attention Transformer with six major distinctions: input gate, forget gate, shortcut, no attention normalization, single-head, and modified block design. For each design, we meticulously analyze its pros and cons, and empirically evaluate its impact on model performance in vision tasks. Interestingly, the results highlight the forget gate and block design as the core contributors to Mamba's success, while the other four designs are less crucial. Based on these findings, we propose a Mamba-Like Linear Attention (MLLA) model by incorporating the merits of these two key designs into linear attention. The resulting model outperforms various vision Mamba models in both image classification and high-resolution dense prediction tasks, while enjoying parallelizable computation and fast inference speed. Code is available at https://github.com/LeapLabTHU/MLLA.
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models
May 24, 2024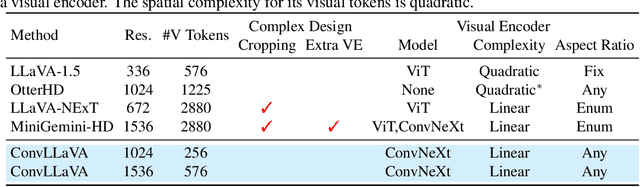
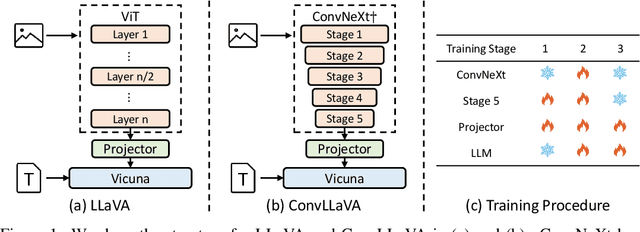
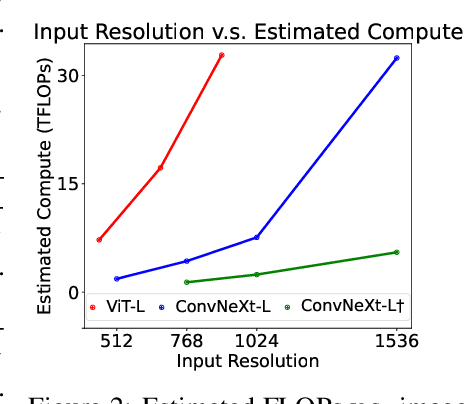

High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic complexity while still generating excessive visual tokens. However, the redundancy in visual tokens is the key problem as it leads to more substantial compute. To mitigate this issue, we propose ConvLLaVA, which employs ConvNeXt, a hierarchical backbone, as the visual encoder of LMM to replace Vision Transformer (ViT). ConvLLaVA compresses high-resolution images into information-rich visual features, effectively preventing the generation of excessive visual tokens. To enhance the capabilities of ConvLLaVA, we propose two critical optimizations. Since the low-resolution pretrained ConvNeXt underperforms when directly applied on high resolution, we update it to bridge the gap. Moreover, since ConvNeXt's original compression ratio is inadequate for much higher resolution inputs, we train a successive stage to further compress the visual tokens, thereby reducing redundancy. These optimizations enable ConvLLaVA to support inputs of 1536x1536 resolution generating only 576 visual tokens, capable of handling images of arbitrary aspect ratios. Experimental results demonstrate that our method achieves competitive performance with state-of-the-art models on mainstream benchmarks. The ConvLLaVA model series are publicly available at https://github.com/alibaba/conv-llava.
LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images
Mar 18, 2024



Visual encoding constitutes the basis of large multimodal models (LMMs) in understanding the visual world. Conventional LMMs process images in fixed sizes and limited resolutions, while recent explorations in this direction are limited in adaptivity, efficiency, and even correctness. In this work, we first take GPT-4V and LLaVA-1.5 as representative examples and expose systematic flaws rooted in their visual encoding strategy. To address the challenges, we present LLaVA-UHD, a large multimodal model that can efficiently perceive images in any aspect ratio and high resolution. LLaVA-UHD includes three key components: (1) An image modularization strategy that divides native-resolution images into smaller variable-sized slices for efficient and extensible encoding, (2) a compression module that further condenses image tokens from visual encoders, and (3) a spatial schema to organize slice tokens for LLMs. Comprehensive experiments show that LLaVA-UHD outperforms established LMMs trained with 2-3 orders of magnitude more data on 9 benchmarks. Notably, our model built on LLaVA-1.5 336x336 supports 6 times larger (i.e., 672x1088) resolution images using only 94% inference computation, and achieves 6.4 accuracy improvement on TextVQA. Moreover, the model can be efficiently trained in academic settings, within 23 hours on 8 A100 GPUs (vs. 26 hours of LLaVA-1.5). We make the data and code publicly available at https://github.com/thunlp/LLaVA-UHD.
Using Human Feedback to Fine-tune Diffusion Models without Any Reward Model
Nov 23, 2023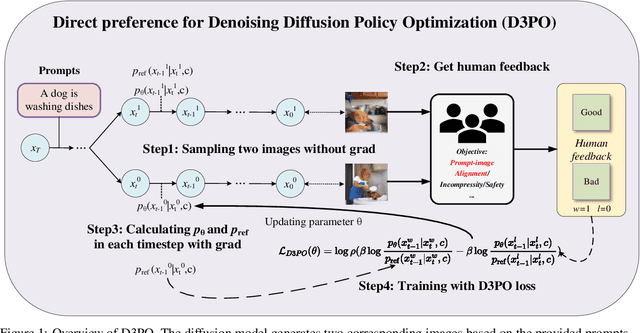

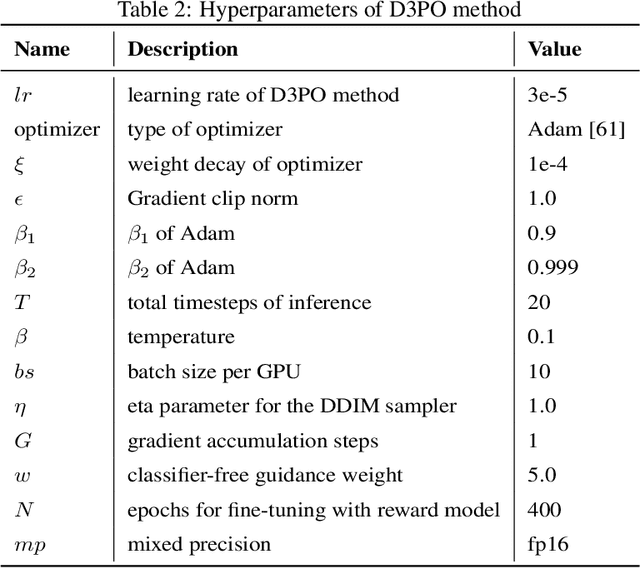
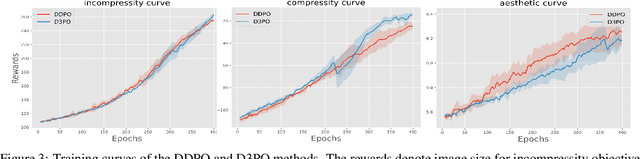
Using reinforcement learning with human feedback (RLHF) has shown significant promise in fine-tuning diffusion models. Previous methods start by training a reward model that aligns with human preferences, then leverage RL techniques to fine-tune the underlying models. However, crafting an efficient reward model demands extensive datasets, optimal architecture, and manual hyperparameter tuning, making the process both time and cost-intensive. The direct preference optimization (DPO) method, effective in fine-tuning large language models, eliminates the necessity for a reward model. However, the extensive GPU memory requirement of the diffusion model's denoising process hinders the direct application of the DPO method. To address this issue, we introduce the Direct Preference for Denoising Diffusion Policy Optimization (D3PO) method to directly fine-tune diffusion models. The theoretical analysis demonstrates that although D3PO omits training a reward model, it effectively functions as the optimal reward model trained using human feedback data to guide the learning process. This approach requires no training of a reward model, proving to be more direct, cost-effective, and minimizing computational overhead. In experiments, our method uses the relative scale of objectives as a proxy for human preference, delivering comparable results to methods using ground-truth rewards. Moreover, D3PO demonstrates the ability to reduce image distortion rates and generate safer images, overcoming challenges lacking robust reward models. Our code is publicly available in https://github.com/yk7333/D3PO/tree/main.
Cross-Modal Adapter for Text-Video Retrieval
Nov 17, 2022Text-video retrieval is an important multi-modal learning task, where the goal is to retrieve the most relevant video for a given text query. Recently, pre-trained models, e.g., CLIP, show great potential on this task. However, as pre-trained models are scaling up, fully fine-tuning them on text-video retrieval datasets has a high risk of overfitting. Moreover, in practice, it would be costly to train and store a large model for each task. To overcome the above issues, we present a novel $\textbf{Cross-Modal Adapter}$ for parameter-efficient fine-tuning. Inspired by adapter-based methods, we adjust the pre-trained model with a few parameterization layers. However, there are two notable differences. First, our method is designed for the multi-modal domain. Secondly, it allows early cross-modal interactions between CLIP's two encoders. Although surprisingly simple, our approach has three notable benefits: (1) reduces $\textbf{99.6}\%$ of fine-tuned parameters, and alleviates the problem of overfitting, (2) saves approximately 30% of training time, and (3) allows all the pre-trained parameters to be fixed, enabling the pre-trained model to be shared across datasets. Extensive experiments demonstrate that, without bells and whistles, it achieves superior or comparable performance compared to fully fine-tuned methods on MSR-VTT, MSVD, VATEX, ActivityNet, and DiDeMo datasets. The code will be available at \url{https://github.com/LeapLabTHU/Cross-Modal-Adapter}.
Domain Adaptation via Prompt Learning
Feb 14, 2022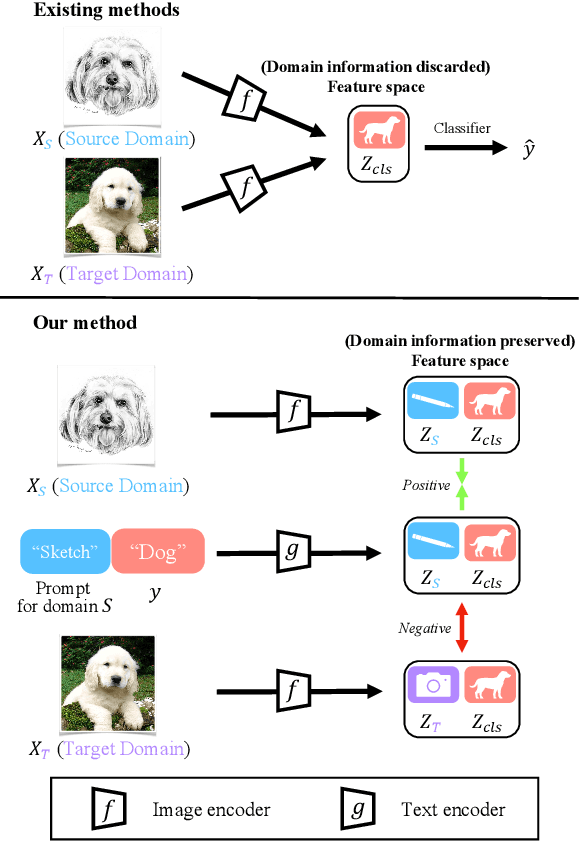

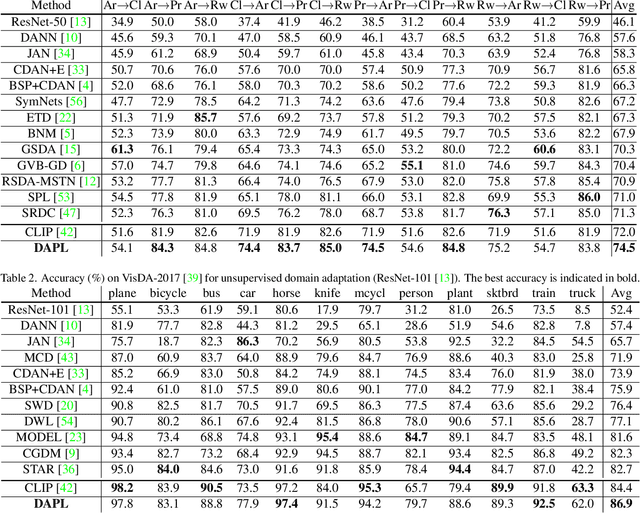
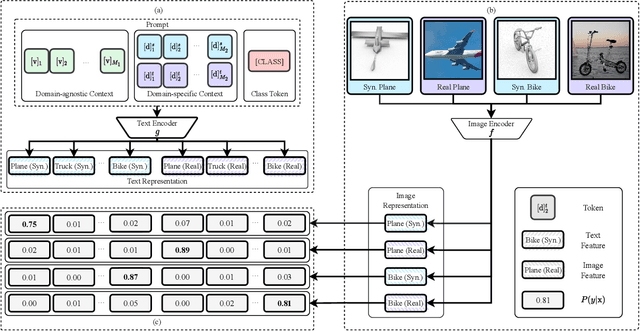
Unsupervised domain adaption (UDA) aims to adapt models learned from a well-annotated source domain to a target domain, where only unlabeled samples are given. Current UDA approaches learn domain-invariant features by aligning source and target feature spaces. Such alignments are imposed by constraints such as statistical discrepancy minimization or adversarial training. However, these constraints could lead to the distortion of semantic feature structures and loss of class discriminability. In this paper, we introduce a novel prompt learning paradigm for UDA, named Domain Adaptation via Prompt Learning (DAPL). In contrast to prior works, our approach makes use of pre-trained vision-language models and optimizes only very few parameters. The main idea is to embed domain information into prompts, a form of representations generated from natural language, which is then used to perform classification. This domain information is shared only by images from the same domain, thereby dynamically adapting the classifier according to each domain. By adopting this paradigm, we show that our model not only outperforms previous methods on several cross-domain benchmarks but also is very efficient to train and easy to implement.