 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELLM: Exploring LLM-Powered Micro-Expression Understanding Enhanced by Subtle Motion Perception
May 11, 2025
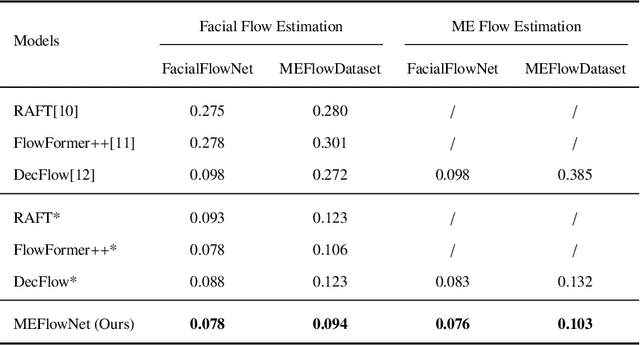
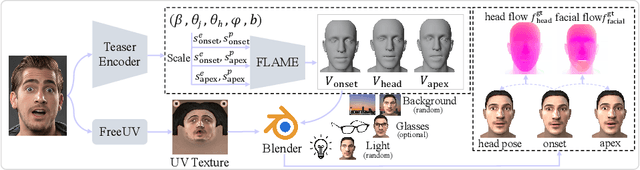
Micro-expressions (MEs) are crucial psychological responses with significant potential for affective computing. However, current automatic micro-expression recognition (MER) research primarily focuses on discrete emotion classification, neglecting a convincing analysis of the subtle dynamic movements and inherent emotional cues. The rapid progress in multimodal large language models (MLLMs), known for their strong multimodal comprehension and language generation abilities, offers new possibilities. MLLMs have shown success in various vision-language tasks, indicating their potential to understand MEs comprehensively, including both fine-grained motion patterns and underlying emotional semantics. Nevertheless, challenges remain due to the subtle intensity and short duration of MEs, as existing MLLMs are not designed to capture such delicate frame-level facial dynamics. In this paper, we propose a novel Micro-Expression Large Language Model (MELLM), which incorporates a subtle facial motion perception strategy with the strong inference capabilities of MLLMs, representing the first exploration of MLLMs in the domain of ME analysis. Specifically, to explicitly guide the MLLM toward motion-sensitive regions, we construct an interpretable motion-enhanced color map by fusing onset-apex optical flow dynamics with the corresponding grayscale onset frame as the model input. Additionally, specialized fine-tuning strategies are incorporated to further enhance the model's visual perception of MEs. Furthermore, we construct an instruction-description dataset based on Facial Action Coding System (FACS) annotations and emotion labels to train our MELLM. Comprehensive evaluations across multiple benchmark datasets demonstrate that our model exhibits superior robustness and generalization capabilities in ME understanding (MEU). Code is available at https://github.com/zyzhangUstc/MELLM.
QuoTA: Query-oriented Token Assignment via CoT Query Decouple for Long Video Comprehension
Mar 11, 2025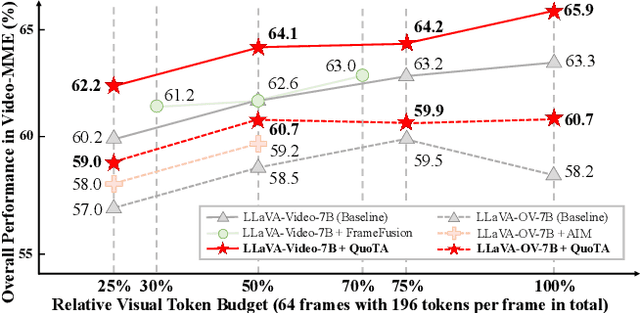
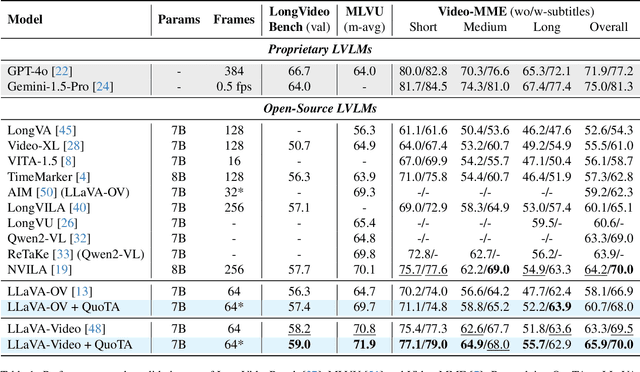
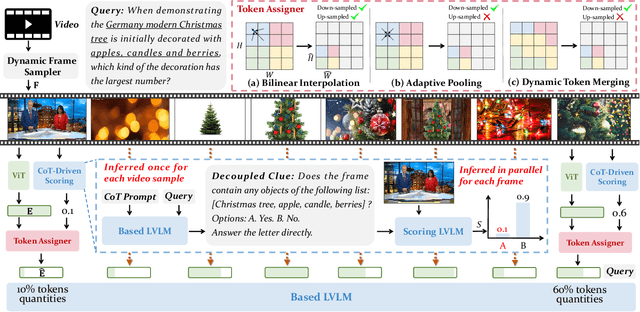
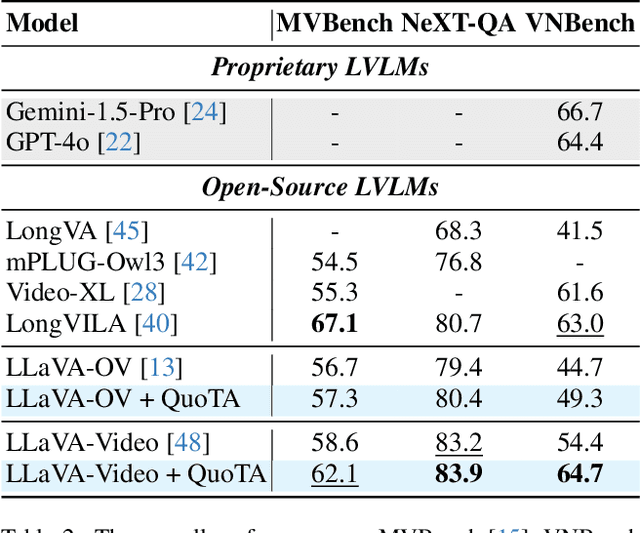
Recent advances in long video understanding typically mitigate visual redundancy through visual token pruning based on attention distribution. However, while existing methods employ post-hoc low-response token pruning in decoder layers, they overlook the input-level semantic correlation between visual tokens and instructions (query). In this paper, we propose QuoTA, an ante-hoc training-free modular that extends existing large video-language models (LVLMs) for visual token assignment based on query-oriented frame-level importance assessment. The query-oriented token selection is crucial as it aligns visual processing with task-specific requirements, optimizing token budget utilization while preserving semantically relevant content. Specifically, (i) QuoTA strategically allocates frame-level importance scores based on query relevance, enabling one-time visual token assignment before cross-modal interactions in decoder layers, (ii) we decouple the query through Chain-of-Thoughts reasoning to facilitate more precise LVLM-based frame importance scoring, and (iii) QuoTA offers a plug-and-play functionality that extends to existing LVLMs. Extensive experimental results demonstrate that implementing QuoTA with LLaVA-Video-7B yields an average performance improvement of 3.2% across six benchmarks (including Video-MME and MLVU) while operating within an identical visual token budget as the baseline. Codes are open-sourced at https://github.com/MAC-AutoML/QuoTA.
T2Vid: Translating Long Text into Multi-Image is the Catalyst for Video-LLMs
Dec 02, 2024



The success of Multimodal Large Language Models (MLLMs) in the image domain has garnered wide attention from the research community. Drawing on previous successful experiences, researchers have recently explored extending the success to the video understanding realms. Apart from training from scratch, an efficient way is to utilize the pre-trained image-LLMs, leading to two mainstream approaches, i.e. zero-shot inference and further fine-tuning with video data. In this work, our study of these approaches harvests an effective data augmentation method. We first make a deeper inspection of the zero-shot inference way and identify two limitations, i.e. limited generalization and lack of temporal understanding capabilities. Thus, we further investigate the fine-tuning approach and find a low learning efficiency when simply using all the video data samples, which can be attributed to a lack of instruction diversity. Aiming at this issue, we develop a method called T2Vid to synthesize video-like samples to enrich the instruction diversity in the training corpus. Integrating these data enables a simple and efficient training scheme, which achieves performance comparable to or even superior to using full video datasets by training with just 15% the sample size. Meanwhile, we find that the proposed scheme can boost the performance of long video understanding without training with long video samples. We hope our study will spark more thinking about using MLLMs for video understanding and curation of high-quality data. The code is released at https://github.com/xjtupanda/T2Vid.
MME-Survey: A Comprehensive Survey on Evaluation of Multimodal LLMs
Nov 22, 2024
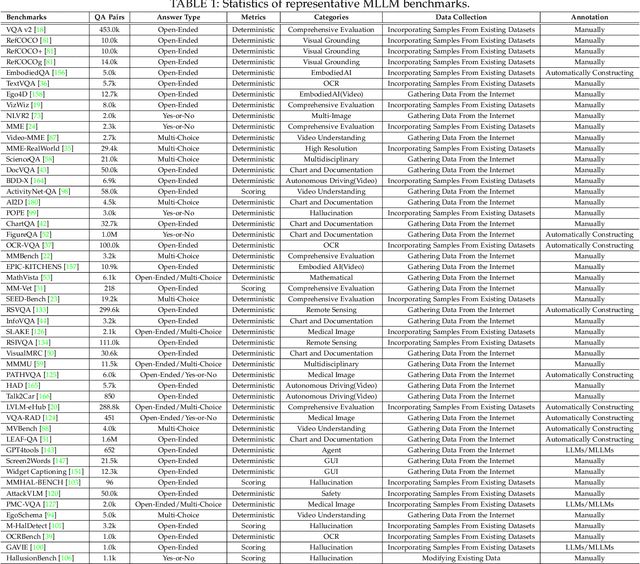
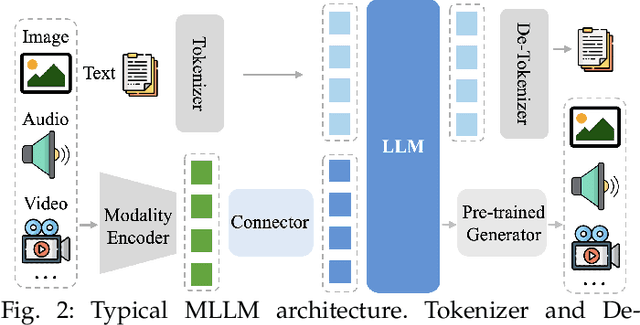
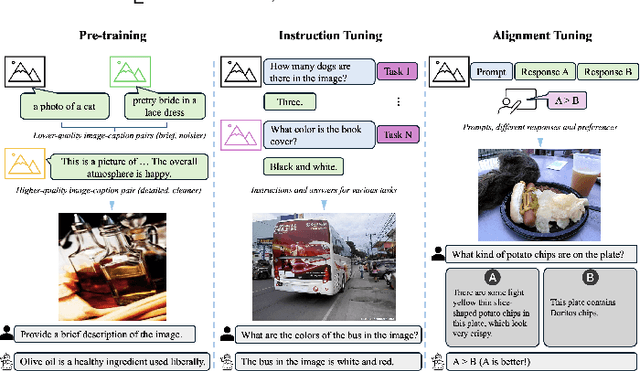
As a prominent direction of Artificial General Intelligence (AGI), Multimodal Large Language Models (MLLMs) have garnered increased attention from both industry and academia. Building upon pre-trained LLMs, this family of models further develops multimodal perception and reasoning capabilities that are impressive, such as writing code given a flow chart or creating stories based on an image. In the development process, evaluation is critical since it provides intuitive feedback and guidance on improving models. Distinct from the traditional train-eval-test paradigm that only favors a single task like image classification, the versatility of MLLMs has spurred the rise of various new benchmarks and evaluation methods. In this paper, we aim to present a comprehensive survey of MLLM evaluation, discussing four key aspects: 1) the summarised benchmarks types divided by the evaluation capabilities, including foundation capabilities, model self-analysis, and extented applications; 2) the typical process of benchmark counstruction, consisting of data collection, annotation, and precautions; 3) the systematic evaluation manner composed of judge, metric, and toolkit; 4) the outlook for the next benchmark. This work aims to offer researchers an easy grasp of how to effectively evaluate MLLMs according to different needs and to inspire better evaluation methods, thereby driving the progress of MLLM research.
Woodpecker: Hallucination Correction for Multimodal Large Language Models
Oct 24, 2023Hallucination is a big shadow hanging over the rapidly evolving Multimodal Large Language Models (MLLMs), referring to the phenomenon that the generated text is inconsistent with the image content. In order to mitigate hallucinations, existing studies mainly resort to an instruction-tuning manner that requires retraining the models with specific data. In this paper, we pave a different way, introducing a training-free method named Woodpecker. Like a woodpecker heals trees, it picks out and corrects hallucinations from the generated text. Concretely, Woodpecker consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Implemented in a post-remedy manner, Woodpecker can easily serve different MLLMs, while being interpretable by accessing intermediate outputs of the five stages. We evaluate Woodpecker both quantitatively and qualitatively and show the huge potential of this new paradigm. On the POPE benchmark, our method obtains a 30.66%/24.33% improvement in accuracy over the baseline MiniGPT-4/mPLUG-Owl. The source code is released at https://github.com/BradyFU/Woodpecker.
A Survey on Multimodal Large Language Models
Jun 23, 2023Multimodal Large Language Model (MLLM) recently has been a new rising research hotspot, which uses powerful Large Language Models (LLMs) as a brain to perform multimodal tasks. The surprising emergent capabilities of MLLM, such as writing stories based on images and OCR-free math reasoning, are rare in traditional methods, suggesting a potential path to artificial general intelligence. In this paper, we aim to trace and summarize the recent progress of MLLM. First of all, we present the formulation of MLLM and delineate its related concepts. Then, we discuss the key techniques and applications, including Multimodal Instruction Tuning (M-IT), Multimodal In-Context Learning (M-ICL), Multimodal Chain of Thought (M-CoT), and LLM-Aided Visual Reasoning (LAVR). Finally, we discuss existing challenges and point out promising research directions. In light of the fact that the era of MLLM has only just begun, we will keep updating this survey and hope it can inspire more research. An associated GitHub link collecting the latest papers is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models.
AU-aware graph convolutional network for Macro- and Micro-expression spotting
Mar 16, 2023Automatic Micro-Expression (ME) spotting in long videos is a crucial step in ME analysis but also a challenging task due to the short duration and low intensity of MEs. When solving this problem, previous works generally lack in considering the structures of human faces and the correspondence between expressions and relevant facial muscles. To address this issue for better performance of ME spotting, this paper seeks to extract finer spatial features by modeling the relationships between facial Regions of Interest (ROIs). Specifically, we propose a graph convolutional-based network, called Action-Unit-aWare Graph Convolutional Network (AUW-GCN). Furthermore, to inject prior information and to cope with the problem of small datasets, AU-related statistics are encoded into the network. Comprehensive experiments show that our results outperform baseline methods consistently and achieve new SOTA performance in two benchmark datasets,CAS(ME)^2 and SAMM-LV. Our code is available at https://github.com/xjtupanda/AUW-GCN.