 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuoTA: Query-oriented Token Assignment via CoT Query Decouple for Long Video Comprehension
Paper and Code
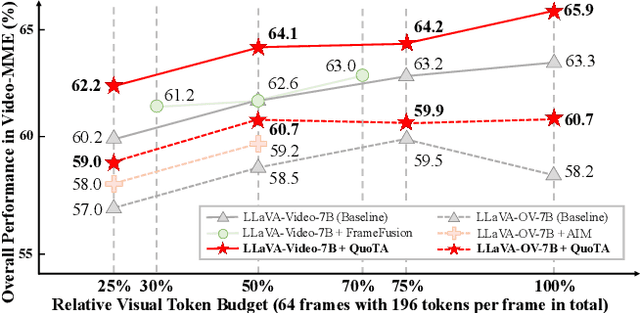
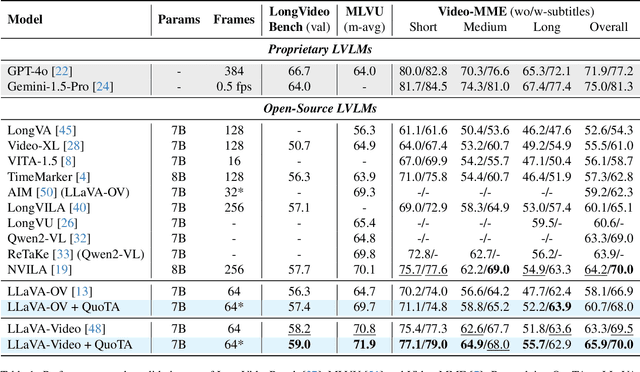
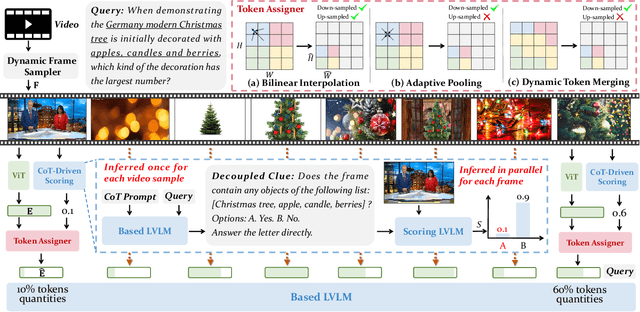
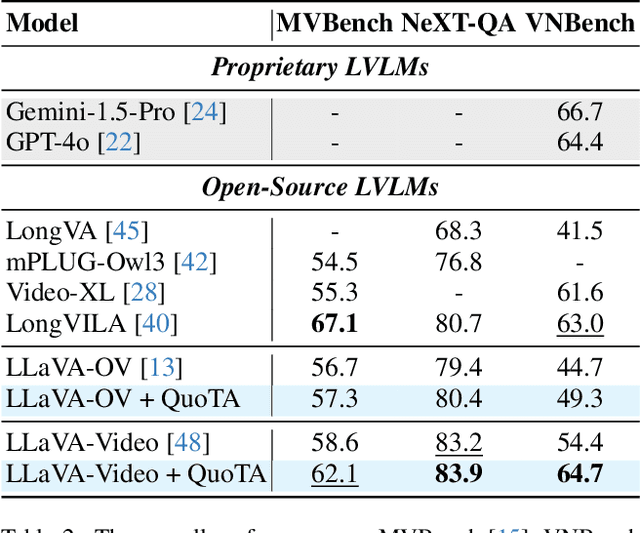
Recent advances in long video understanding typically mitigate visual redundancy through visual token pruning based on attention distribution. However, while existing methods employ post-hoc low-response token pruning in decoder layers, they overlook the input-level semantic correlation between visual tokens and instructions (query). In this paper, we propose QuoTA, an ante-hoc training-free modular that extends existing large video-language models (LVLMs) for visual token assignment based on query-oriented frame-level importance assessment. The query-oriented token selection is crucial as it aligns visual processing with task-specific requirements, optimizing token budget utilization while preserving semantically relevant content. Specifically, (i) QuoTA strategically allocates frame-level importance scores based on query relevance, enabling one-time visual token assignment before cross-modal interactions in decoder layers, (ii) we decouple the query through Chain-of-Thoughts reasoning to facilitate more precise LVLM-based frame importance scoring, and (iii) QuoTA offers a plug-and-play functionality that extends to existing LVLMs. Extensive experimental results demonstrate that implementing QuoTA with LLaVA-Video-7B yields an average performance improvement of 3.2% across six benchmarks (including Video-MME and MLVU) while operating within an identical visual token budget as the baseline. Codes are open-sourced at https://github.com/MAC-AutoML/QuoTA.