 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering One-Step Diffusion Model with Fidelity-Rich Decoder for Fast Image Compression
Aug 07, 2025Diffusion-based image compression has demonstrated impressive perceptual performance. However, it suffers from two critical drawbacks: (1) excessive decoding latency due to multi-step sampling, and (2) poor fidelity resulting from over-reliance on generative priors. To address these issues, we propose SODEC, a novel single-step diffusion image compression model. We argue that in image compression, a sufficiently informative latent renders multi-step refinement unnecessary. Based on this insight, we leverage a pre-trained VAE-based model to produce latents with rich information, and replace the iterative denoising process with a single-step decoding. Meanwhile, to improve fidelity, we introduce the fidelity guidance module, encouraging output that is faithful to the original image. Furthermore, we design the rate annealing training strategy to enable effective training under extremely low bitrates. Extensive experiments show that SODEC significantly outperforms existing methods, achieving superior rate-distortion-perception performance. Moreover, compared to previous diffusion-based compression models, SODEC improves decoding speed by more than 20$\times$. Code is released at: https://github.com/zhengchen1999/SODEC.
ChineseSimpleVQA -- "See the World, Discover Knowledge": A Chinese Factuality Evaluation for Large Vision Language Models
Feb 19, 2025The evaluation of factual accuracy in large vision language models (LVLMs) has lagged behind their rapid development, making it challenging to fully reflect these models' knowledge capacity and reliability. In this paper, we introduce the first factuality-based visual question-answering benchmark in Chinese, named ChineseSimpleVQA, aimed at assessing the visual factuality of LVLMs across 8 major topics and 56 subtopics. The key features of this benchmark include a focus on the Chinese language, diverse knowledge types, a multi-hop question construction, high-quality data, static consistency, and easy-to-evaluate through short answers. Moreover, we contribute a rigorous data construction pipeline and decouple the visual factuality into two parts: seeing the world (i.e., object recognition) and discovering knowledge. This decoupling allows us to analyze the capability boundaries and execution mechanisms of LVLMs. Subsequently, we evaluate 34 advanced open-source and closed-source models, revealing critical performance gaps within this field.
Compression with Global Guidance: Towards Training-free High-Resolution MLLMs Acceleration
Jan 09, 2025



Multimodal large language models (MLLMs) have attracted considerable attention due to their exceptional performance in visual content understanding and reasoning. However, their inference efficiency has been a notable concern, as the increasing length of multimodal contexts leads to quadratic complexity. Token compression techniques, which reduce the number of visual tokens, have demonstrated their effectiveness in reducing computational costs. Yet, these approaches have struggled to keep pace with the rapid advancements in MLLMs, especially the AnyRes strategy in the context of high-resolution image understanding. In this paper, we propose a novel token compression method, GlobalCom$^2$, tailored for high-resolution MLLMs that receive both the thumbnail and multiple crops. GlobalCom$^2$ treats the tokens derived from the thumbnail as the ``commander'' of the entire token compression process, directing the allocation of retention ratios and the specific compression for each crop. In this way, redundant tokens are eliminated while important local details are adaptively preserved to the highest extent feasible. Empirical results across 10 benchmarks reveal that GlobalCom$^2$ achieves an optimal balance between performance and efficiency, and consistently outperforms state-of-the-art token compression methods with LLaVA-NeXT-7B/13B models. Our code is released at \url{https://github.com/xuyang-liu16/GlobalCom2}.
LongDocURL: a Comprehensive Multimodal Long Document Benchmark Integrating Understanding, Reasoning, and Locating
Dec 24, 2024Large vision language models (LVLMs) have improved the document understanding capabilities remarkably, enabling the handling of complex document elements, longer contexts, and a wider range of tasks. However, existing document understanding benchmarks have been limited to handling only a small number of pages and fail to provide a comprehensive analysis of layout elements locating. In this paper, we first define three primary task categories: Long Document Understanding, numerical Reasoning, and cross-element Locating, and then propose a comprehensive benchmark, LongDocURL, integrating above three primary tasks and comprising 20 sub-tasks categorized based on different primary tasks and answer evidences. Furthermore, we develop a semi-automated construction pipeline and collect 2,325 high-quality question-answering pairs, covering more than 33,000 pages of documents, significantly outperforming existing benchmarks. Subsequently, we conduct comprehensive evaluation experiments on both open-source and closed-source models across 26 different configurations, revealing critical performance gaps in this field.
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models
May 24, 2024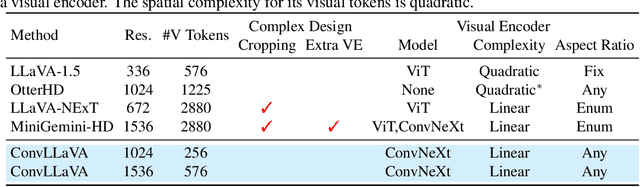
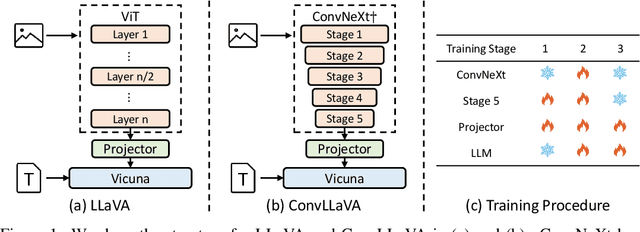
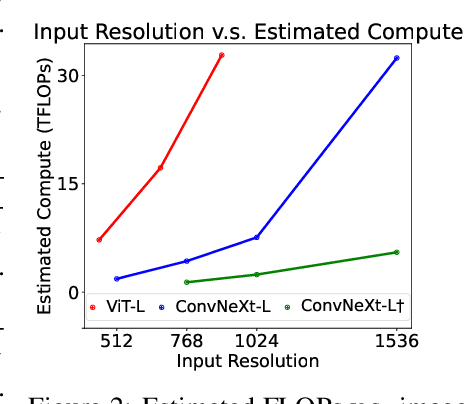

High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic complexity while still generating excessive visual tokens. However, the redundancy in visual tokens is the key problem as it leads to more substantial compute. To mitigate this issue, we propose ConvLLaVA, which employs ConvNeXt, a hierarchical backbone, as the visual encoder of LMM to replace Vision Transformer (ViT). ConvLLaVA compresses high-resolution images into information-rich visual features, effectively preventing the generation of excessive visual tokens. To enhance the capabilities of ConvLLaVA, we propose two critical optimizations. Since the low-resolution pretrained ConvNeXt underperforms when directly applied on high resolution, we update it to bridge the gap. Moreover, since ConvNeXt's original compression ratio is inadequate for much higher resolution inputs, we train a successive stage to further compress the visual tokens, thereby reducing redundancy. These optimizations enable ConvLLaVA to support inputs of 1536x1536 resolution generating only 576 visual tokens, capable of handling images of arbitrary aspect ratios. Experimental results demonstrate that our method achieves competitive performance with state-of-the-art models on mainstream benchmarks. The ConvLLaVA model series are publicly available at https://github.com/alibaba/conv-llava.