 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Life-Logging Video Streams Make the Privacy-Utility Trade-off Inevitable
May 11, 2026With the growing prevalence of always-on hardware such as smart glasses, body cameras, and home security systems, life-logging visual sensing is becoming inevitable, forming the backbone of persistent, always-on AI systems. Meanwhile, recent advances in proactive agents and world models signal a fundamental shift from episodic, prompt-driven tools to next-generation AI systems that continuously perceive and react to the physical world. Although life-logging video streams can substantially improve utility of these promising systems, they also introduce significant privacy risks by revealing sensitive information, such as behavioral patterns, emotional states, and social interactions, beyond what isolated images expose. If unresolved, these risks may undermine public trust and hinder the sustainable development of always-on AI technologies. Existing privacy protections are either attack-specific or incur substantial utility loss, and fail to consider the entire data exploitation pipeline. We therefore posit that the privacy-utility trade-off in life-logging video streams is a foundational challenge for next-generation AI systems that demands further investigation. We call for novel pipeline-aware privacy-preserving designs that jointly optimize utility and privacy for long-horizon life-logging visual data. In parallel, formal privacy leakage metrics and standardized benchmarks remain important open directions for future research.
Evaluating Memory Capability in Continuous Lifelog Scenario
Apr 13, 2026Nowadays, wearable devices can continuously lifelog ambient conversations, creating substantial opportunities for memory systems. However, existing benchmarks primarily focus on online one-on-one chatting or human-AI interactions, thus neglecting the unique demands of real-world scenarios. Given the scarcity of public lifelogging audio datasets, we propose a hierarchical synthesis framework to curate \textbf{\textsc{LifeDialBench}}, a novel benchmark comprising two complementary subsets: \textbf{EgoMem}, built on real-world egocentric videos, and \textbf{LifeMem}, constructed using simulated virtual community. Crucially, to address the issue of temporal leakage in traditional offline settings, we propose an \textbf{Online Evaluation} protocol that strictly adheres to temporal causality, ensuring systems are evaluated in a realistic streaming fashion. Our experimental results reveal a counterintuitive finding: current sophisticated memory systems fail to outperform a simple RAG-based baseline. This highlights the detrimental impact of over-designed structures and lossy compression in current approaches, emphasizing the necessity of high-fidelity context preservation for lifelog scenarios. We release our code and data at https://github.com/qys77714/LifeDialBench.
Recurrent Reasoning with Vision-Language Models for Estimating Long-Horizon Embodied Task Progress
Mar 18, 2026Accurately estimating task progress is critical for embodied agents to plan and execute long-horizon, multi-step tasks. Despite promising advances, existing Vision-Language Models (VLMs) based methods primarily leverage their video understanding capabilities, while neglecting their complex reasoning potential. Furthermore, processing long video trajectories with VLMs is computationally prohibitive for real-world deployment. To address these challenges, we propose the Recurrent Reasoning Vision-Language Model ($\text{R}^2$VLM). Our model features a recurrent reasoning framework that processes local video snippets iteratively, maintaining a global context through an evolving Chain of Thought (CoT). This CoT explicitly records task decomposition, key steps, and their completion status, enabling the model to reason about complex temporal dependencies. This design avoids the high cost of processing long videos while preserving essential reasoning capabilities. We train $\text{R}^2$VLM on large-scale, automatically generated datasets from ALFRED and Ego4D. Extensive experiments on progress estimation and downstream applications, including progress-enhanced policy learning, reward modeling for reinforcement learning, and proactive assistance, demonstrate that $\text{R}^2$VLM achieves strong performance and generalization, achieving a new state-of-the-art in long-horizon task progress estimation. The models and benchmarks are publicly available at \href{https://huggingface.co/collections/zhangyuelin/r2vlm}{huggingface}.
Building Egocentric Procedural AI Assistant: Methods, Benchmarks, and Challenges
Nov 17, 2025Driven by recent advances in vision language models (VLMs) and egocentric perception research, we introduce the concept of an egocentric procedural AI assistant (EgoProceAssist) tailored to step-by-step support daily procedural tasks in a first-person view. In this work, we start by identifying three core tasks: egocentric procedural error detection, egocentric procedural learning, and egocentric procedural question answering. These tasks define the essential functions of EgoProceAssist within a new taxonomy. Specifically, our work encompasses a comprehensive review of current techniques, relevant datasets, and evaluation metrics across these three core areas. To clarify the gap between the proposed EgoProceAssist and existing VLM-based AI assistants, we introduce novel experiments and provide a comprehensive evaluation of representative VLM-based methods. Based on these findings and our technical analysis, we discuss the challenges ahead and suggest future research directions. Furthermore, an exhaustive list of this study is publicly available in an active repository that continuously collects the latest work: https://github.com/z1oong/Building-Egocentric-Procedural-AI-Assistant
StableToolBench-MirrorAPI: Modeling Tool Environments as Mirrors of 7,000+ Real-World APIs
Mar 26, 2025



The rapid advancement of large language models (LLMs) has spurred significant interest in tool learning, where LLMs are augmented with external tools to tackle complex tasks. However, existing tool environments face challenges in balancing stability, scalability, and realness, particularly for benchmarking purposes. To address this problem, we propose MirrorAPI, a novel framework that trains specialized LLMs to accurately simulate real API responses, effectively acting as "mirrors" to tool environments. Using a comprehensive dataset of request-response pairs from 7,000+ APIs, we employ supervised fine-tuning and chain-of-thought reasoning to enhance simulation fidelity. MirrorAPI achieves superior accuracy and stability compared to state-of-the-art methods, as demonstrated by its performance on the newly constructed MirrorAPI-Bench and its integration into StableToolBench.
VidEgoThink: Assessing Egocentric Video Understanding Capabilities for Embodied AI
Oct 15, 2024Recent advancements in Multi-modal Large Language Models (MLLMs) have opened new avenues for applications in Embodied AI. Building on previous work, EgoThink, we introduce VidEgoThink, a comprehensive benchmark for evaluating egocentric video understanding capabilities. To bridge the gap between MLLMs and low-level control in Embodied AI, we design four key interrelated tasks: video question-answering, hierarchy planning, visual grounding and reward modeling. To minimize manual annotation costs, we develop an automatic data generation pipeline based on the Ego4D dataset, leveraging the prior knowledge and multimodal capabilities of GPT-4o. Three human annotators then filter the generated data to ensure diversity and quality, resulting in the VidEgoThink benchmark. We conduct extensive experiments with three types of models: API-based MLLMs, open-source image-based MLLMs, and open-source video-based MLLMs. Experimental results indicate that all MLLMs, including GPT-4o, perform poorly across all tasks related to egocentric video understanding. These findings suggest that foundation models still require significant advancements to be effectively applied to first-person scenarios in Embodied AI. In conclusion, VidEgoThink reflects a research trend towards employing MLLMs for egocentric vision, akin to human capabilities, enabling active observation and interaction in the complex real-world environments.
Instruction-Guided Visual Masking
May 30, 2024

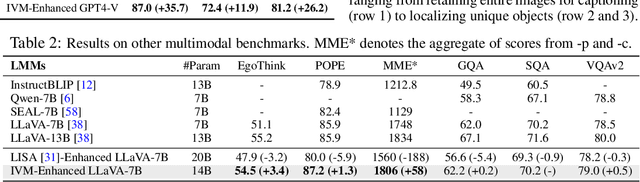

Instruction following is crucial in contemporary LLM. However, when extended to multimodal setting, it often suffers from misalignment between specific textual instruction and targeted local region of an image. To achieve more accurate and nuanced multimodal instruction following, we introduce Instruction-guided Visual Masking (IVM), a new versatile visual grounding model that is compatible with diverse multimodal models, such as LMM and robot model. By constructing visual masks for instruction-irrelevant regions, IVM-enhanced multimodal models can effectively focus on task-relevant image regions to better align with complex instructions. Specifically, we design a visual masking data generation pipeline and create an IVM-Mix-1M dataset with 1 million image-instruction pairs. We further introduce a new learning technique, Discriminator Weighted Supervised Learning (DWSL) for preferential IVM training that prioritizes high-quality data samples. Experimental results on generic multimodal tasks such as VQA and embodied robotic control demonstrate the versatility of IVM, which as a plug-and-play tool, significantly boosts the performance of diverse multimodal models, yielding new state-of-the-art results across challenging multimodal benchmarks. Code is available at https://github.com/2toinf/IVM.
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models
May 24, 2024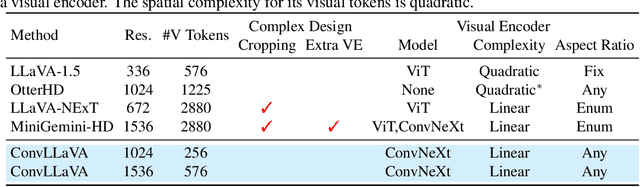
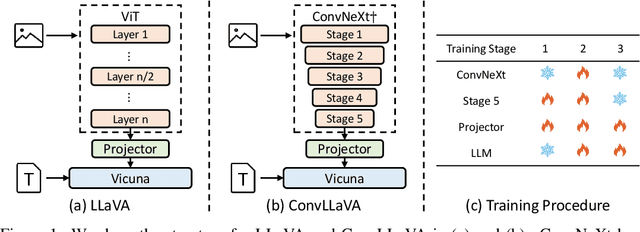
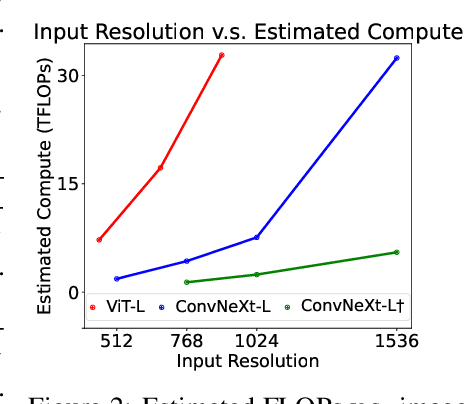

High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic complexity while still generating excessive visual tokens. However, the redundancy in visual tokens is the key problem as it leads to more substantial compute. To mitigate this issue, we propose ConvLLaVA, which employs ConvNeXt, a hierarchical backbone, as the visual encoder of LMM to replace Vision Transformer (ViT). ConvLLaVA compresses high-resolution images into information-rich visual features, effectively preventing the generation of excessive visual tokens. To enhance the capabilities of ConvLLaVA, we propose two critical optimizations. Since the low-resolution pretrained ConvNeXt underperforms when directly applied on high resolution, we update it to bridge the gap. Moreover, since ConvNeXt's original compression ratio is inadequate for much higher resolution inputs, we train a successive stage to further compress the visual tokens, thereby reducing redundancy. These optimizations enable ConvLLaVA to support inputs of 1536x1536 resolution generating only 576 visual tokens, capable of handling images of arbitrary aspect ratios. Experimental results demonstrate that our method achieves competitive performance with state-of-the-art models on mainstream benchmarks. The ConvLLaVA model series are publicly available at https://github.com/alibaba/conv-llava.
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
Mar 13, 2024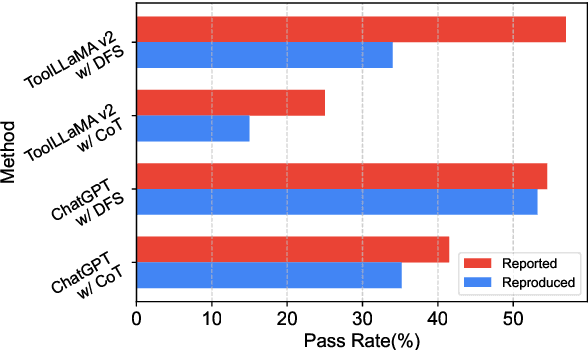
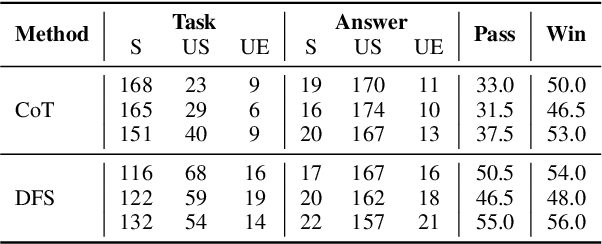
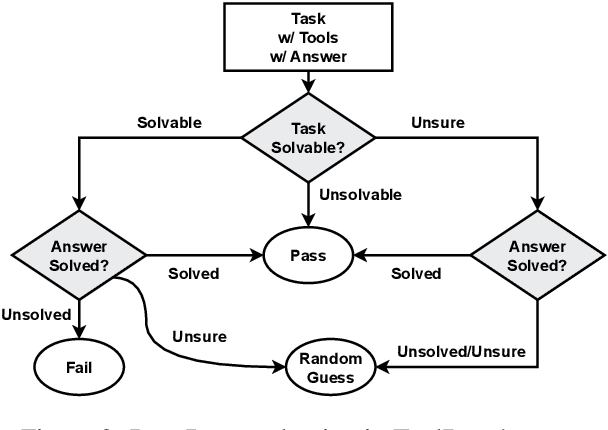
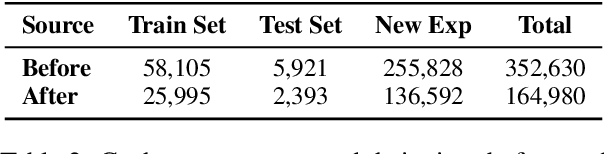
Large Language Models (LLMs) have witnessed remarkable advancements in recent years, prompting the exploration of tool learning, which integrates LLMs with external tools to address diverse real-world challenges. Assessing the capability of LLMs to utilise tools necessitates large-scale and stable benchmarks. However, previous works relied on either hand-crafted online tools with limited scale, or large-scale real online APIs suffering from instability of API status. To address this problem, we introduce StableToolBench, a benchmark evolving from ToolBench, proposing a virtual API server and stable evaluation system. The virtual API server contains a caching system and API simulators which are complementary to alleviate the change in API status. Meanwhile, the stable evaluation system designs solvable pass and win rates using GPT-4 as the automatic evaluator to eliminate the randomness during evaluation. Experimental results demonstrate the stability of StableToolBench, and further discuss the effectiveness of API simulators, the caching system, and the evaluator system.
DecisionNCE: Embodied Multimodal Representations via Implicit Preference Learning
Feb 28, 2024Multimodal pretraining has emerged as an effective strategy for the trinity of goals of representation learning in autonomous robots: 1) extracting both local and global task progression information; 2) enforcing temporal consistency of visual representation; 3) capturing trajectory-level language grounding. Most existing methods approach these via separate objectives, which often reach sub-optimal solutions. In this paper, we propose a universal unified objective that can simultaneously extract meaningful task progression information from image sequences and seamlessly align them with language instructions. We discover that via implicit preferences, where a visual trajectory inherently aligns better with its corresponding language instruction than mismatched pairs, the popular Bradley-Terry model can transform into representation learning through proper reward reparameterizations. The resulted framework, DecisionNCE, mirrors an InfoNCE-style objective but is distinctively tailored for decision-making tasks, providing an embodied representation learning framework that elegantly extracts both local and global task progression features, with temporal consistency enforced through implicit time contrastive learning, while ensuring trajectory-level instruction grounding via multimodal joint encoding. Evaluation on both simulated and real robots demonstrates that DecisionNCE effectively facilitates diverse downstream policy learning tasks, offering a versatile solution for unified representation and reward learning. Project Page: https://2toinf.github.io/DecisionNCE/