 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's LIT! Reliability-Optimized LLMs with Inspectable Tools
Nov 18, 2025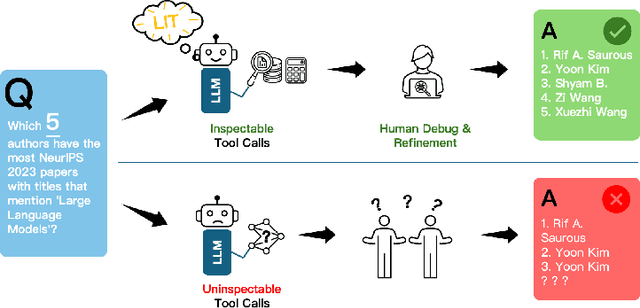
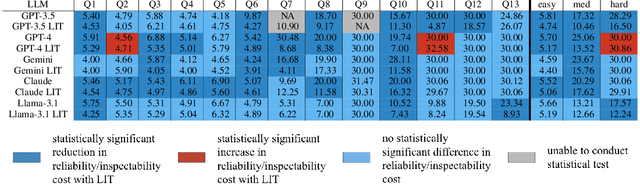
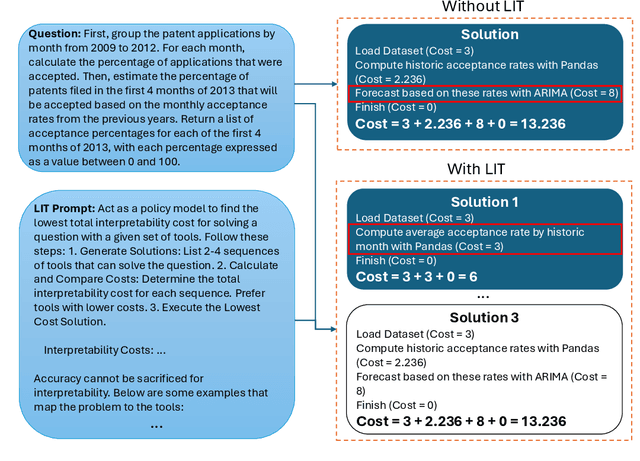
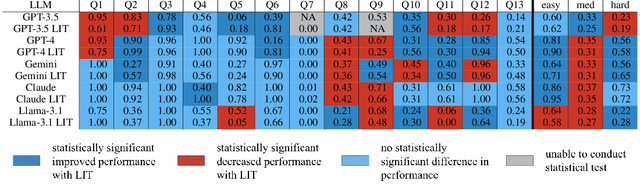
Large language models (LLMs) have exhibited remarkable capabilities across various domains. The ability to call external tools further expands their capability to handle real-world tasks. However, LLMs often follow an opaque reasoning process, which limits their usefulness in high-stakes domains where solutions need to be trustworthy to end users. LLMs can choose solutions that are unreliable and difficult to troubleshoot, even if better options are available. We address this issue by forcing LLMs to use external -- more reliable -- tools to solve problems when possible. We present a framework built on the tool-calling capabilities of existing LLMs to enable them to select the most reliable and easy-to-troubleshoot solution path, which may involve multiple sequential tool calls. We refer to this framework as LIT (LLMs with Inspectable Tools). In order to support LIT, we introduce a new and challenging benchmark dataset of 1,300 questions and a customizable set of reliability cost functions associated with a collection of specialized tools. These cost functions summarize how reliable each tool is and how easy it is to troubleshoot. For instance, a calculator is reliable across domains, whereas a linear prediction model is not reliable if there is distribution shift, but it is easy to troubleshoot. A tool that constructs a random forest is neither reliable nor easy to troubleshoot. These tools interact with the Harvard USPTO Patent Dataset and a new dataset of NeurIPS 2023 papers to solve mathematical, coding, and modeling problems of varying difficulty levels. We demonstrate that LLMs can achieve more reliable and informed problem-solving while maintaining task performance using our framework.
StableToolBench-MirrorAPI: Modeling Tool Environments as Mirrors of 7,000+ Real-World APIs
Mar 26, 2025



The rapid advancement of large language models (LLMs) has spurred significant interest in tool learning, where LLMs are augmented with external tools to tackle complex tasks. However, existing tool environments face challenges in balancing stability, scalability, and realness, particularly for benchmarking purposes. To address this problem, we propose MirrorAPI, a novel framework that trains specialized LLMs to accurately simulate real API responses, effectively acting as "mirrors" to tool environments. Using a comprehensive dataset of request-response pairs from 7,000+ APIs, we employ supervised fine-tuning and chain-of-thought reasoning to enhance simulation fidelity. MirrorAPI achieves superior accuracy and stability compared to state-of-the-art methods, as demonstrated by its performance on the newly constructed MirrorAPI-Bench and its integration into StableToolBench.
Rashomon Sets for Prototypical-Part Networks: Editing Interpretable Models in Real-Time
Mar 03, 2025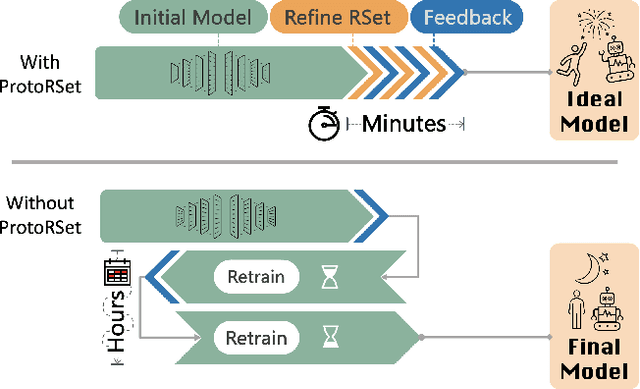
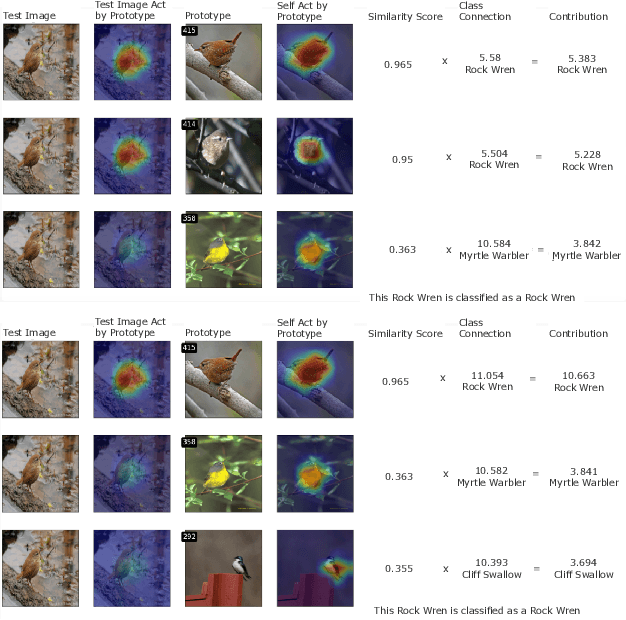

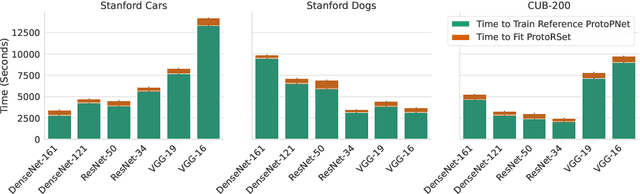
Interpretability is critical for machine learning models in high-stakes settings because it allows users to verify the model's reasoning. In computer vision, prototypical part models (ProtoPNets) have become the dominant model type to meet this need. Users can easily identify flaws in ProtoPNets, but fixing problems in a ProtoPNet requires slow, difficult retraining that is not guaranteed to resolve the issue. This problem is called the "interaction bottleneck." We solve the interaction bottleneck for ProtoPNets by simultaneously finding many equally good ProtoPNets (i.e., a draw from a "Rashomon set"). We show that our framework - called Proto-RSet - quickly produces many accurate, diverse ProtoPNets, allowing users to correct problems in real time while maintaining performance guarantees with respect to the training set. We demonstrate the utility of this method in two settings: 1) removing synthetic bias introduced to a bird identification model and 2) debugging a skin cancer identification model. This tool empowers non-machine-learning experts, such as clinicians or domain experts, to quickly refine and correct machine learning models without repeated retraining by machine learning experts.
StepTool: A Step-grained Reinforcement Learning Framework for Tool Learning in LLMs
Oct 10, 2024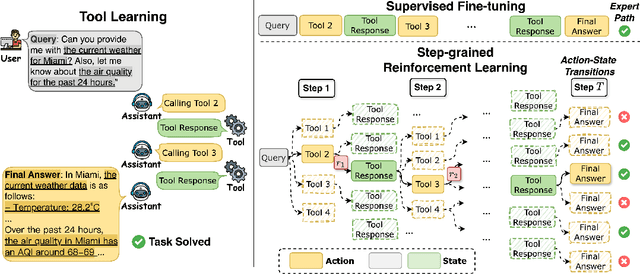

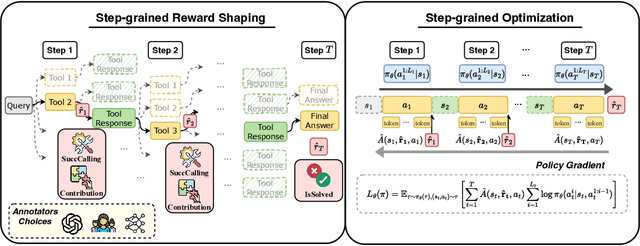
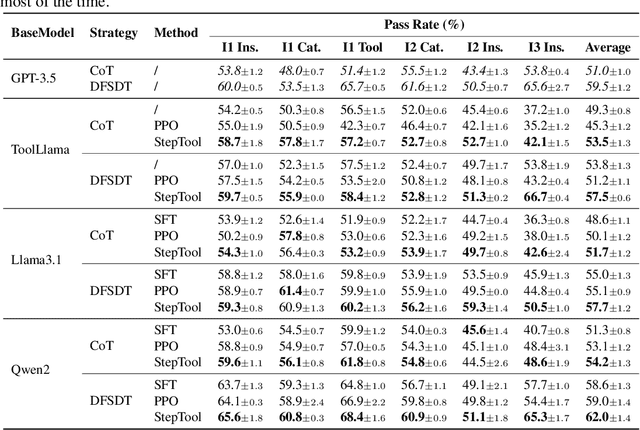
Despite having powerful reasoning and inference capabilities, Large Language Models (LLMs) still need external tools to acquire real-time information retrieval or domain-specific expertise to solve complex tasks, which is referred to as tool learning. Existing tool learning methods primarily rely on tuning with expert trajectories, focusing on token-sequence learning from a linguistic perspective. However, there are several challenges: 1) imitating static trajectories limits their ability to generalize to new tasks. 2) even expert trajectories can be suboptimal, and better solution paths may exist. In this work, we introduce StepTool, a novel step-grained reinforcement learning framework to improve tool learning in LLMs. It consists of two components: Step-grained Reward Shaping, which assigns rewards at each tool interaction based on tool invocation success and its contribution to the task, and Step-grained Optimization, which uses policy gradient methods to optimize the model in a multi-step manner. Experimental results demonstrate that StepTool significantly outperforms existing methods in multi-step, tool-based tasks, providing a robust solution for complex task environments. Codes are available at https://github.com/yuyq18/StepTool.
Is It Good Data for Multilingual Instruction Tuning or Just Bad Multilingual Evaluation for Large Language Models?
Jun 18, 2024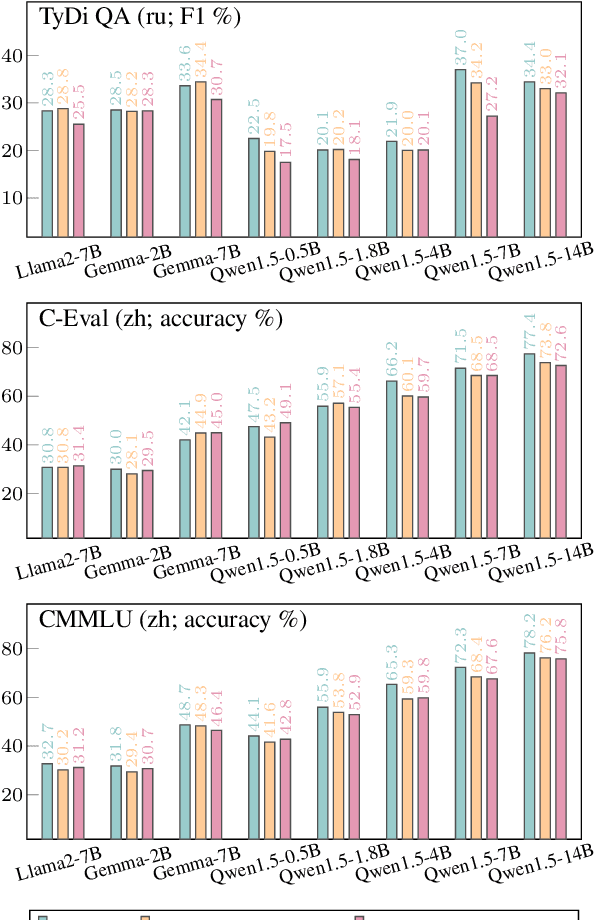
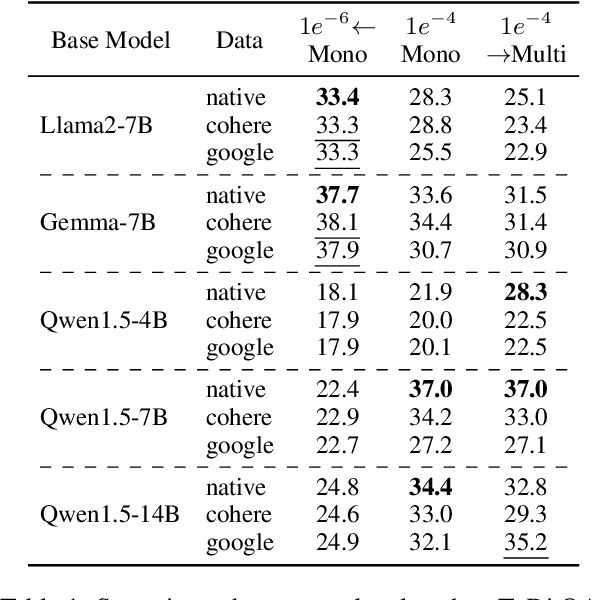
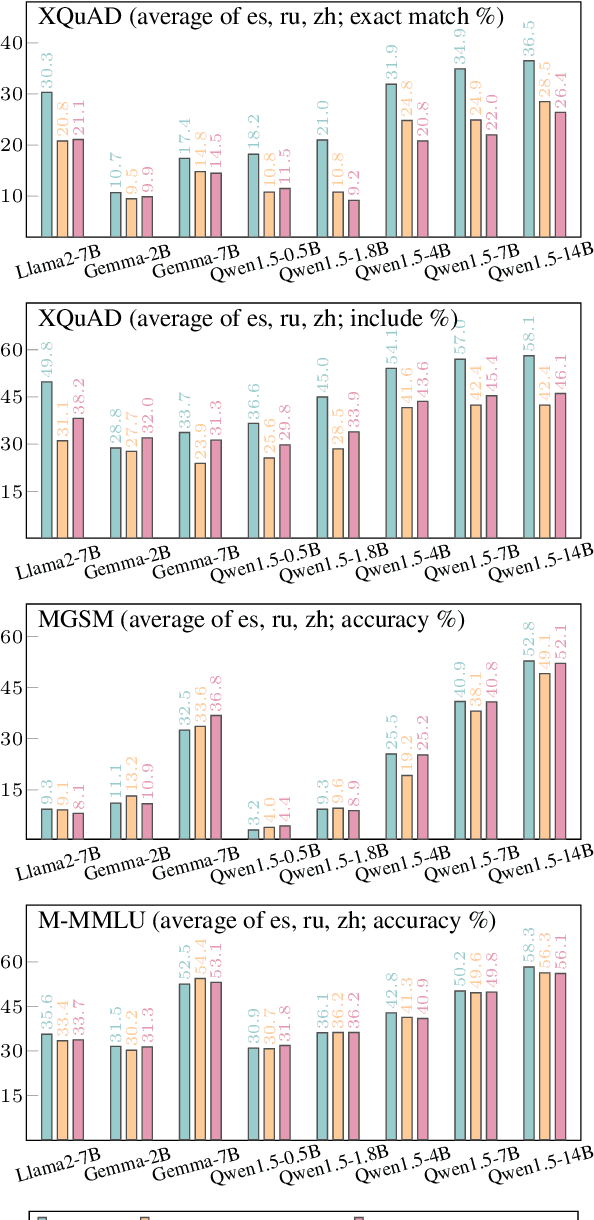
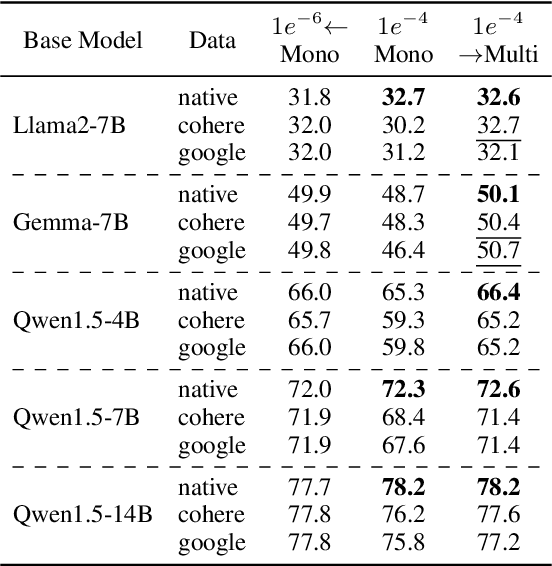
Large language models, particularly multilingual ones, are designed, claimed, and expected to cater to native speakers of varied languages. We hypothesise that the current practices of fine-tuning and evaluating these models may mismatch this intention owing to a heavy reliance on translation, which can introduce translation artefacts and defects. It remains unknown whether the nature of the instruction data has an impact on the model output; on the other hand, it remains questionable whether translated test sets can capture such nuances. Due to the often coupled practices of using translated data in both stages, such imperfections could have been overlooked. This work investigates these issues by using controlled native or translated data during instruction tuning and evaluation stages and observing model results. Experiments on eight base models and eight different benchmarks reveal that native or generation benchmarks display a notable difference between native and translated instruction data especially when model performance is high, whereas other types of test sets cannot. Finally, we demonstrate that regularization is beneficial to bridging this gap on structured but not generative tasks.
SiamQuality: A ConvNet-Based Foundation Model for Imperfect Physiological Signals
Apr 26, 2024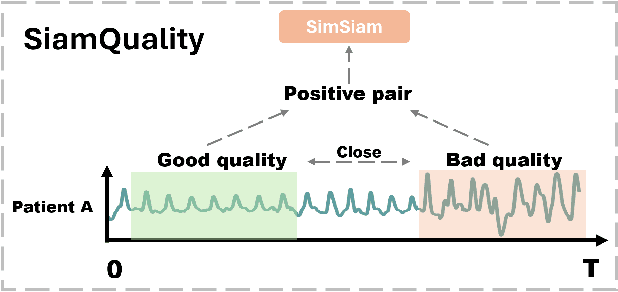

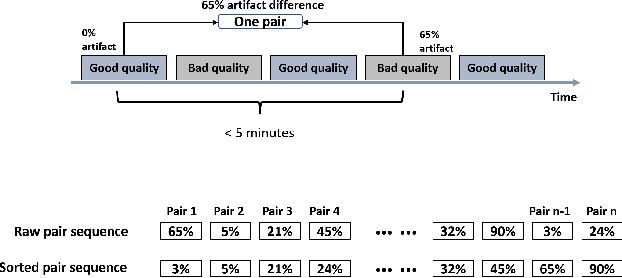
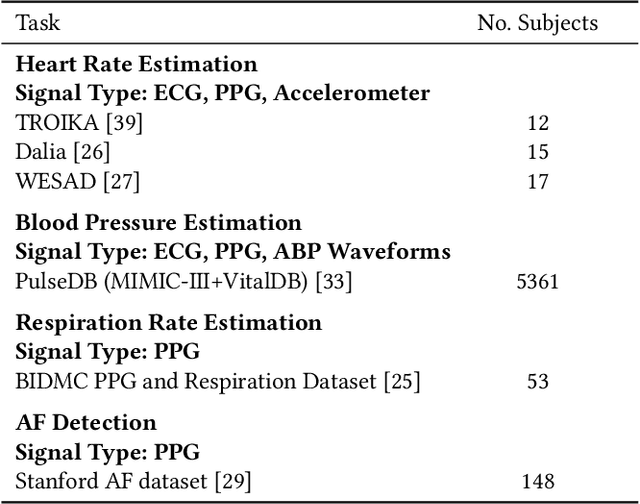
Foundation models, especially those using transformers as backbones, have gained significant popularity, particularly in language and language-vision tasks. However, large foundation models are typically trained on high-quality data, which poses a significant challenge, given the prevalence of poor-quality real-world data. This challenge is more pronounced for developing foundation models for physiological data; such data are often noisy, incomplete, or inconsistent. The present work aims to provide a toolset for developing foundation models on physiological data. We leverage a large dataset of photoplethysmography (PPG) signals from hospitalized intensive care patients. For this data, we propose SimQuality, a novel self-supervised learning task based on convolutional neural networks (CNNs) as the backbone to enforce representations to be similar for good and poor quality signals that are from similar physiological states. We pre-trained the SimQuality on over 36 million 30-second PPG pairs and then fine-tuned and tested on six downstream tasks using external datasets. The results demonstrate the superiority of the proposed approach on all the downstream tasks, which are extremely important for heart monitoring on wearable devices. Our method indicates that CNNs can be an effective backbone for foundation models that are robust to training data quality.
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
Mar 13, 2024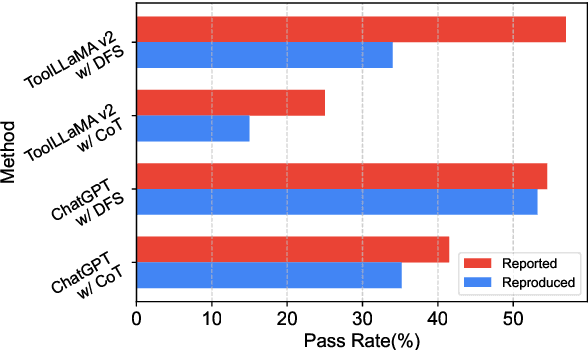
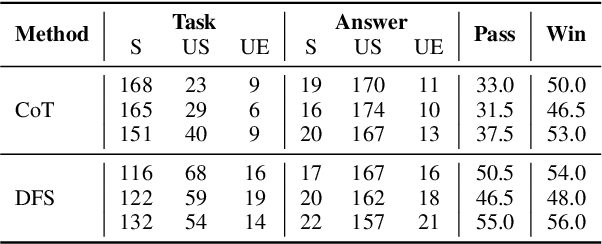
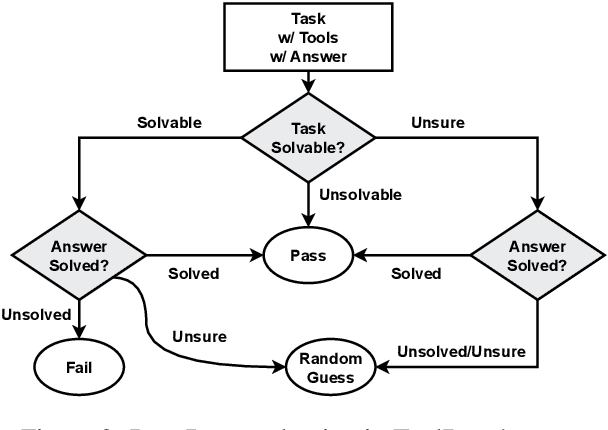
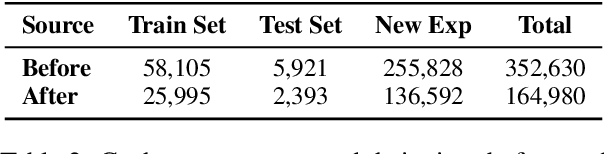
Large Language Models (LLMs) have witnessed remarkable advancements in recent years, prompting the exploration of tool learning, which integrates LLMs with external tools to address diverse real-world challenges. Assessing the capability of LLMs to utilise tools necessitates large-scale and stable benchmarks. However, previous works relied on either hand-crafted online tools with limited scale, or large-scale real online APIs suffering from instability of API status. To address this problem, we introduce StableToolBench, a benchmark evolving from ToolBench, proposing a virtual API server and stable evaluation system. The virtual API server contains a caching system and API simulators which are complementary to alleviate the change in API status. Meanwhile, the stable evaluation system designs solvable pass and win rates using GPT-4 as the automatic evaluator to eliminate the randomness during evaluation. Experimental results demonstrate the stability of StableToolBench, and further discuss the effectiveness of API simulators, the caching system, and the evaluator system.
What is different between these datasets?
Mar 08, 2024



The performance of machine learning models heavily depends on the quality of input data, yet real-world applications often encounter various data-related challenges. One such challenge could arise when curating training data or deploying the model in the real world - two comparable datasets in the same domain may have different distributions. While numerous techniques exist for detecting distribution shifts, the literature lacks comprehensive approaches for explaining dataset differences in a human-understandable manner. To address this gap, we propose a suite of interpretable methods (toolbox) for comparing two datasets. We demonstrate the versatility of our approach across diverse data modalities, including tabular data, language, images, and signals in both low and high-dimensional settings. Our methods not only outperform comparable and related approaches in terms of explanation quality and correctness, but also provide actionable, complementary insights to understand and mitigate dataset differences effectively.
Towards Unified Alignment Between Agents, Humans, and Environment
Feb 14, 2024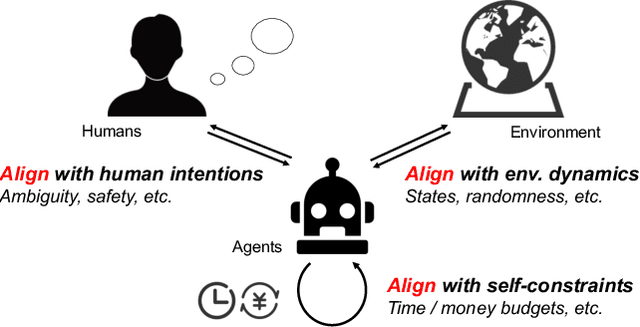
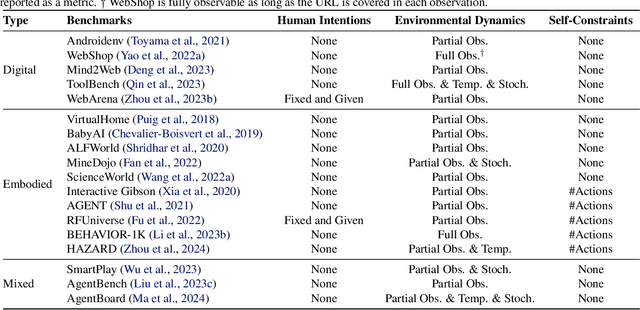
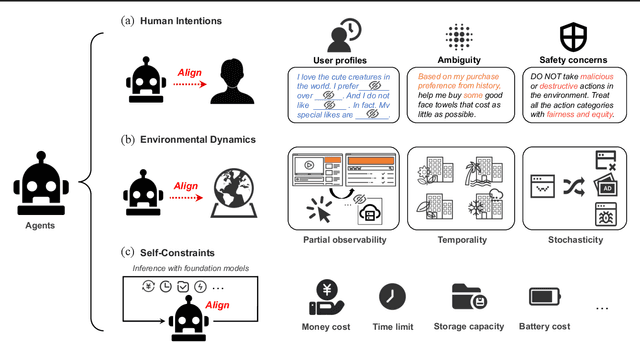

The rapid progress of foundation models has led to the prosperity of autonomous agents, which leverage the universal capabilities of foundation models to conduct reasoning, decision-making, and environmental interaction. However, the efficacy of agents remains limited when operating in intricate, realistic environments. In this work, we introduce the principles of $\mathbf{U}$nified $\mathbf{A}$lignment for $\mathbf{A}$gents ($\mathbf{UA}^2$), which advocate for the simultaneous alignment of agents with human intentions, environmental dynamics, and self-constraints such as the limitation of monetary budgets. From the perspective of $\mathbf{UA}^2$, we review the current agent research and highlight the neglected factors in existing agent benchmarks and method candidates. We also conduct proof-of-concept studies by introducing realistic features to WebShop, including user profiles to demonstrate intentions, personalized reranking for complex environmental dynamics, and runtime cost statistics to reflect self-constraints. We then follow the principles of $\mathbf{UA}^2$ to propose an initial design of our agent, and benchmark its performance with several candidate baselines in the retrofitted WebShop. The extensive experimental results further prove the importance of the principles of $\mathbf{UA}^2$. Our research sheds light on the next steps of autonomous agent research with improved general problem-solving abilities.
Reconsideration on evaluation of machine learning models in continuous monitoring using wearables
Dec 04, 2023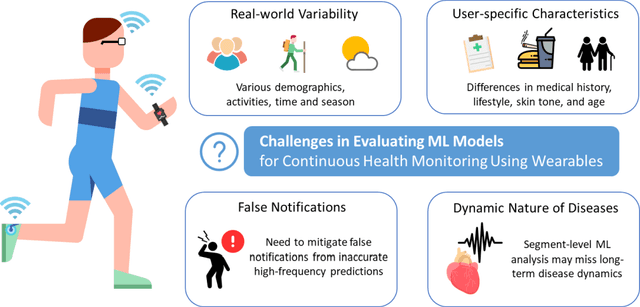

This paper explores the challenges in evaluating machine learning (ML) models for continuous health monitoring using wearable devices beyond conventional metrics. We state the complexities posed by real-world variability, disease dynamics, user-specific characteristics, and the prevalence of false notifications, necessitating novel evaluation strategies. Drawing insights from large-scale heart studies, the paper offers a comprehensive guideline for robust ML model evaluation on continuous health monitoring.