 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs It Good Data for Multilingual Instruction Tuning or Just Bad Multilingual Evaluation for Large Language Models?
Paper and Code
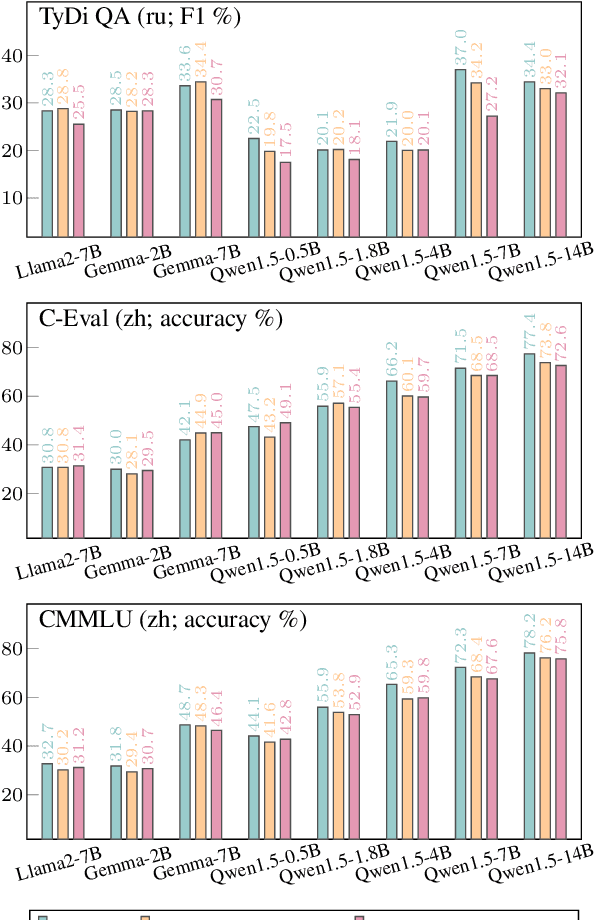
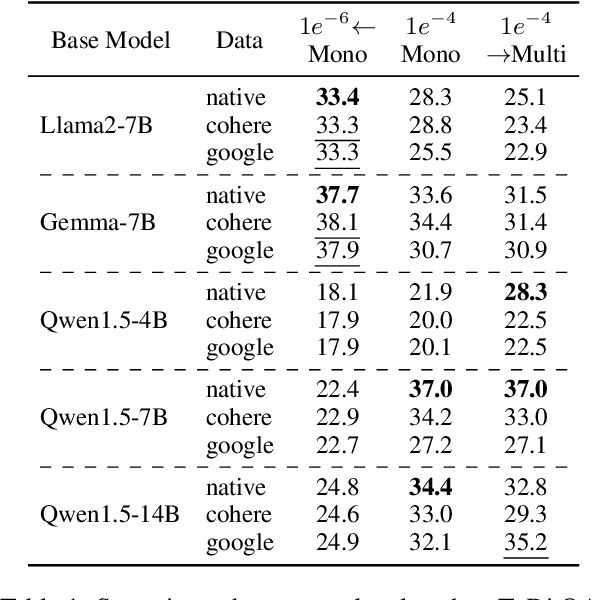
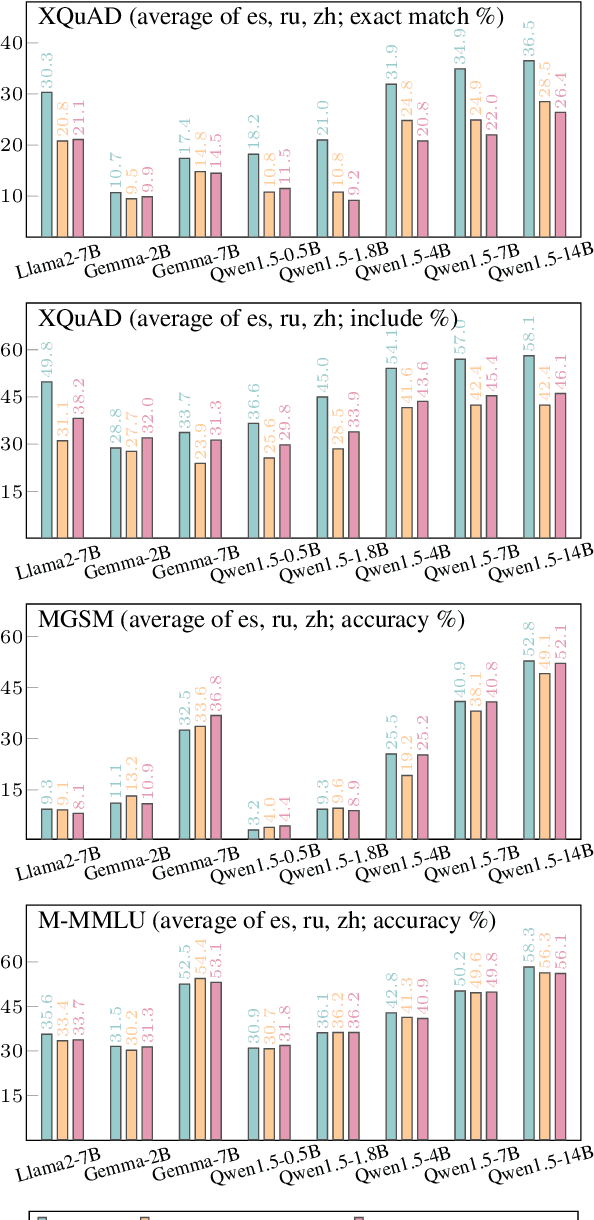
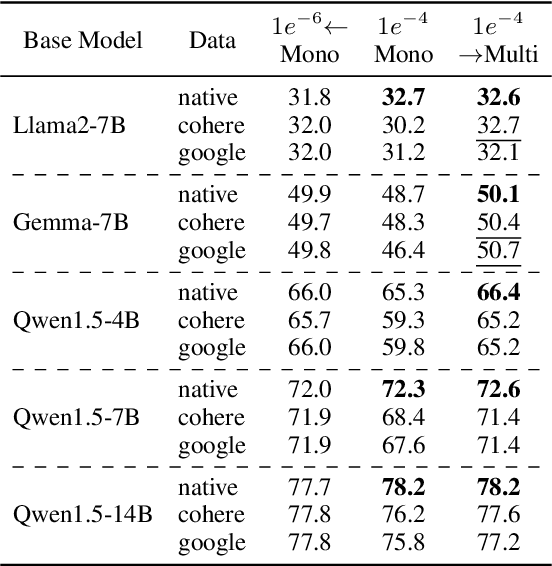
Large language models, particularly multilingual ones, are designed, claimed, and expected to cater to native speakers of varied languages. We hypothesise that the current practices of fine-tuning and evaluating these models may mismatch this intention owing to a heavy reliance on translation, which can introduce translation artefacts and defects. It remains unknown whether the nature of the instruction data has an impact on the model output; on the other hand, it remains questionable whether translated test sets can capture such nuances. Due to the often coupled practices of using translated data in both stages, such imperfections could have been overlooked. This work investigates these issues by using controlled native or translated data during instruction tuning and evaluation stages and observing model results. Experiments on eight base models and eight different benchmarks reveal that native or generation benchmarks display a notable difference between native and translated instruction data especially when model performance is high, whereas other types of test sets cannot. Finally, we demonstrate that regularization is beneficial to bridging this gap on structured but not generative tasks.