 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Elicits Contextual Learning of Unseen Language Translation
Jun 04, 2026Prior work has shown that large language models (LLMs) can translate unseen or low-resource languages by undergoing continued training or even by encoding a grammar book in their context. However, both methods typically overfit specific languages, with limited zero-shot transfer at test time. To translate extremely low-resource languages at scale, we argue that LLMs must acquire the meta-skill of utilizing in-context linguistic knowledge rather than memorizing specific languages. In this paper, we propose a reinforcement learning (RL) approach to unseen language translation given rich linguistic context, using a surface-level translation metric (chrF) as the reward. Empirically, despite the lightweight reward, our RL-trained models effectively extract and apply relevant linguistic information from the provided context, leading to better translations on completely unseen languages than in-context learning or supervised fine-tuning. Our analyses suggest that outcome-based RL can extend beyond conventional reasoning tasks like math and coding to serve as a recipe for language learning from context.
When Flores Bloomz Wrong: Cross-Direction Contamination in Machine Translation Evaluation
Jan 28, 2026Large language models (LLMs) can be benchmark-contaminated, resulting in inflated scores that mask memorization as generalization, and in multilingual settings, this memorization can even transfer to "uncontaminated" languages. Using the FLORES-200 translation benchmark as a diagnostic, we study two 7-8B instruction-tuned multilingual LLMs: Bloomz, which was trained on FLORES, and Llama as an uncontaminated control. We confirm Bloomz's FLORES contamination and demonstrate that machine translation contamination can be cross-directional, artificially boosting performance in unseen translation directions due to target-side memorization. Further analysis shows that recall of memorized references often persists despite various source-side perturbation efforts like paraphrasing and named entity replacement. However, replacing named entities leads to a consistent decrease in BLEU, suggesting an effective probing method for memorization in contaminated models.
Deep Learning Superresolution for 7T Knee MR Imaging: Impact on Image Quality and Diagnostic Performance
Jan 05, 2026Background: Deep learning superresolution (SR) may enhance musculoskeletal MR image quality, but its diagnostic value in knee imaging at 7T is unclear. Objectives: To compare image quality and diagnostic performance of SR, low-resolution (LR), and high-resolution (HR) 7T knee MRI. Methods: In this prospective study, 42 participants underwent 7T knee MRI with LR (0.8*0.8*2 mm3) and HR (0.4*0.4*2 mm3) sequences. SR images were generated from LR data using a Hybrid Attention Transformer model. Three radiologists assessed image quality, anatomic conspicuity, and detection of knee pathologies. Arthroscopy served as reference in 10 cases. Results: SR images showed higher overall quality than LR (median score 5 vs 4, P<.001) and lower noise than HR (5 vs 4, P<.001). Visibility of cartilage, menisci, and ligaments was superior in SR and HR compared to LR (P<.001). Detection rates and diagnostic performance (sensitivity, specificity, AUC) for intra-articular pathology were similar across image types (P>=.095). Conclusions: Deep learning superresolution improved subjective image quality in 7T knee MRI but did not increase diagnostic accuracy compared with standard LR imaging.
CHARM: Calibrating Reward Models With Chatbot Arena Scores
Apr 14, 2025Reward models (RMs) play a crucial role in Reinforcement Learning from Human Feedback by serving as proxies for human preferences in aligning large language models. In this paper, we identify a model preference bias in RMs, where they systematically assign disproportionately high scores to responses from certain policy models. This bias distorts ranking evaluations and leads to unfair judgments. To address this issue, we propose a calibration method named CHatbot Arena calibrated Reward Modeling (CHARM) that leverages Elo scores from the Chatbot Arena leaderboard to mitigate RM overvaluation. We also introduce a Mismatch Degree metric to measure this preference bias. Our approach is computationally efficient, requiring only a small preference dataset for continued training of the RM. We conduct extensive experiments on reward model benchmarks and human preference alignment. Results demonstrate that our calibrated RMs (1) achieve improved evaluation accuracy on RM-Bench and the Chat-Hard domain of RewardBench, and (2) exhibit a stronger correlation with human preferences by producing scores more closely aligned with Elo rankings. By mitigating model preference bias, our method provides a generalizable and efficient solution for building fairer and more reliable reward models.
XL-Instruct: Synthetic Data for Cross-Lingual Open-Ended Generation
Mar 29, 2025Cross-lingual open-ended generation -- i.e. generating responses in a desired language different from that of the user's query -- is an important yet understudied problem. We introduce XL-AlpacaEval, a new benchmark for evaluating cross-lingual generation capabilities in Large Language Models (LLMs), and propose XL-Instruct, a high-quality synthetic data generation method. Fine-tuning with just 8K XL-Instruct-generated instructions significantly improves model performance, increasing the win rate against GPT-4o-Mini from 7.4% to 21.5%, and improving on several fine-grained quality metrics. Additionally, models fine-tuned on XL-Instruct exhibit strong zero-shot transfer to both English-only and multilingual generation tasks. Given its consistent gains across the board, we strongly recommend incorporating XL-Instruct in the post-training pipeline of future multilingual LLMs. To facilitate further research, we will publicly and freely release the XL-Instruct and XL-AlpacaEval datasets, which constitute two of the few cross-lingual resources currently available in the literature.
Generalizing From Short to Long: Effective Data Synthesis for Long-Context Instruction Tuning
Feb 21, 2025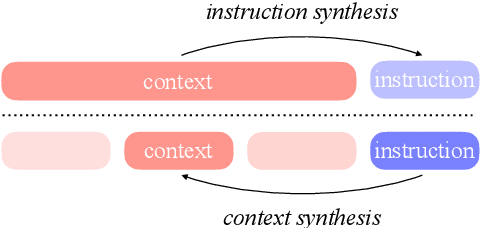

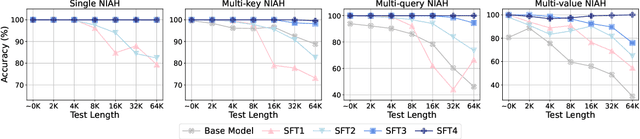
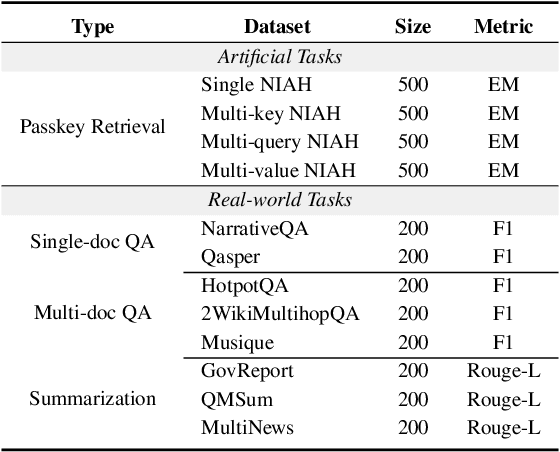
Long-context modelling for large language models (LLMs) has been a key area of recent research because many real world use cases require reasoning over longer inputs such as documents. The focus of research into modelling long context has been on how to model position and there has been little investigation into other important aspects of language modelling such as instruction tuning. Long context training examples are challenging and expensive to create and use. In this paper, we investigate how to design instruction data for the post-training phase of a long context pre-trained model: how much and what type of context is needed for optimal and efficient post-training. Our controlled study reveals that models instruction-tuned on short contexts can effectively generalize to longer ones, while also identifying other critical factors such as instruction difficulty and context composition. Based on these findings, we propose context synthesis, a novel data synthesis framework that leverages off-the-shelf LLMs to generate extended background contexts for high-quality instruction-answer pairs. Experiment results on the document-level benchmark (LongBench) demonstrate that our proposed approach outperforms previous instruction synthesis approaches and comes close to the performance of human-annotated long-context instruction data. The project will be available at: https://github.com/NJUNLP/context-synthesis.
Context and System Fusion in Post-ASR Emotion Recognition with Large Language Models
Oct 04, 2024



Large language models (LLMs) have started to play a vital role in modelling speech and text. To explore the best use of context and multiple systems' outputs for post-ASR speech emotion prediction, we study LLM prompting on a recent task named GenSEC. Our techniques include ASR transcript ranking, variable conversation context, and system output fusion. We show that the conversation context has diminishing returns and the metric used to select the transcript for prediction is crucial. Finally, our best submission surpasses the provided baseline by 20% in absolute accuracy.
EMMA-500: Enhancing Massively Multilingual Adaptation of Large Language Models
Sep 26, 2024



In this work, we introduce EMMA-500, a large-scale multilingual language model continue-trained on texts across 546 languages designed for enhanced multilingual performance, focusing on improving language coverage for low-resource languages. To facilitate continual pre-training, we compile the MaLA corpus, a comprehensive multilingual dataset enriched with curated datasets across diverse domains. Leveraging this corpus, we conduct extensive continual pre-training of the Llama 2 7B model, resulting in EMMA-500, which demonstrates robust performance across a wide collection of benchmarks, including a comprehensive set of multilingual tasks and PolyWrite, an open-ended generation benchmark developed in this study. Our results highlight the effectiveness of continual pre-training in expanding large language models' language capacity, particularly for underrepresented languages, demonstrating significant gains in cross-lingual transfer, task generalization, and language adaptability.
Pitfalls and Outlooks in Using COMET
Sep 02, 2024



Since its introduction, the COMET metric has blazed a trail in the machine translation community, given its strong correlation with human judgements of translation quality. Its success stems from being a modified pre-trained multilingual model finetuned for quality assessment. However, it being a machine learning model also gives rise to a new set of pitfalls that may not be widely known. We investigate these unexpected behaviours from three aspects: 1) technical: obsolete software versions and compute precision; 2) data: empty content, language mismatch, and translationese at test time as well as distribution and domain biases in training; 3) usage and reporting: multi-reference support and model referencing in the literature. All of these problems imply that COMET scores is not comparable between papers or even technical setups and we put forward our perspective on fixing each issue. Furthermore, we release the SacreCOMET package that can generate a signature for the software and model configuration as well as an appropriate citation. The goal of this work is to help the community make more sound use of the COMET metric.
Quality or Quantity? On Data Scale and Diversity in Adapting Large Language Models for Low-Resource Translation
Aug 23, 2024


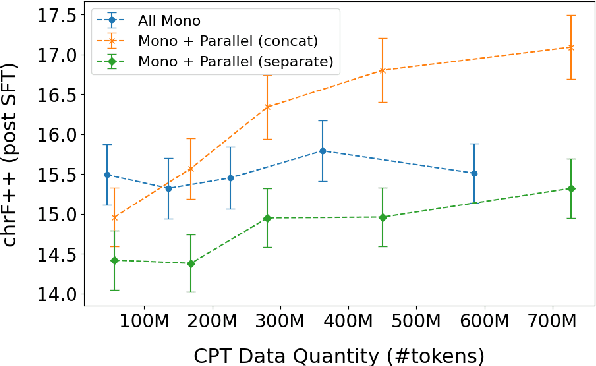
Despite the recent popularity of Large Language Models (LLMs) in Machine Translation (MT), their performance in low-resource translation still lags significantly behind Neural Machine Translation (NMT) models. In this paper, we explore what it would take to adapt LLMs for low-resource settings. In particular, we re-examine the role of two factors: a) the importance and application of parallel data, and b) diversity in Supervised Fine-Tuning (SFT). Recently, parallel data has been shown to be less important for MT using LLMs than in previous MT research. Similarly, diversity during SFT has been shown to promote significant transfer in LLMs across languages and tasks. However, for low-resource LLM-MT, we show that the opposite is true for both of these considerations: a) parallel data is critical during both pretraining and SFT, and b) diversity tends to cause interference, not transfer. Our experiments, conducted with 3 LLMs across 2 low-resourced language groups - indigenous American and North-East Indian - reveal consistent patterns in both cases, underscoring the generalizability of our findings. We believe these insights will be valuable for scaling to massively multilingual LLM-MT models that can effectively serve lower-resource languages.