 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossmodal ASR Error Correction with Discrete Speech Units
Paper and Code
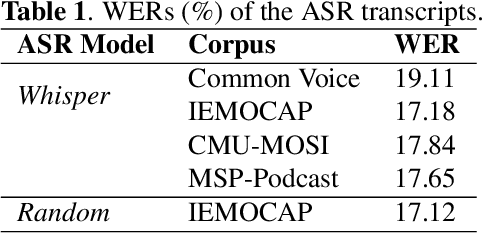
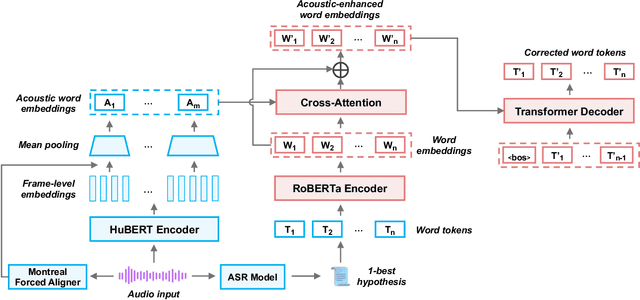


ASR remains unsatisfactory in scenarios where the speaking style diverges from that used to train ASR systems, resulting in erroneous transcripts. To address this, ASR Error Correction (AEC), a post-ASR processing approach, is required. In this work, we tackle an understudied issue: the Low-Resource Out-of-Domain (LROOD) problem, by investigating crossmodal AEC on very limited downstream data with 1-best hypothesis transcription. We explore pre-training and fine-tuning strategies and uncover an ASR domain discrepancy phenomenon, shedding light on appropriate training schemes for LROOD data. Moreover, we propose the incorporation of discrete speech units to align with and enhance the word embeddings for improving AEC quality. Results from multiple corpora and several evaluation metrics demonstrate the feasibility and efficacy of our proposed AEC approach on LROOD data, as well as its generalizability and superiority on large-scale data. Finally, a study on speech emotion recognition confirms that our model produces ASR error-robust transcripts suitable for downstream applications.