 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan the Waymo Open Motion Dataset Support Realistic Behavioral Modeling? A Validation Study with Naturalistic Trajectories
Sep 03, 2025The Waymo Open Motion Dataset (WOMD) has become a popular resource for data-driven modeling of autonomous vehicles (AVs) behavior. However, its validity for behavioral analysis remains uncertain due to proprietary post-processing, the absence of error quantification, and the segmentation of trajectories into 20-second clips. This study examines whether WOMD accurately captures the dynamics and interactions observed in real-world AV operations. Leveraging an independently collected naturalistic dataset from Level 4 AV operations in Phoenix, Arizona (PHX), we perform comparative analyses across three representative urban driving scenarios: discharging at signalized intersections, car-following, and lane-changing behaviors. For the discharging analysis, headways are manually extracted from aerial video to ensure negligible measurement error. For the car-following and lane-changing cases, we apply the Simulation-Extrapolation (SIMEX) method to account for empirically estimated error in the PHX data and use Dynamic Time Warping (DTW) distances to quantify behavioral differences. Results across all scenarios consistently show that behavior in PHX falls outside the behavioral envelope of WOMD. Notably, WOMD underrepresents short headways and abrupt decelerations. These findings suggest that behavioral models calibrated solely on WOMD may systematically underestimate the variability, risk, and complexity of naturalistic driving. Caution is therefore warranted when using WOMD for behavior modeling without proper validation against independently collected data.
CHARM: Calibrating Reward Models With Chatbot Arena Scores
Apr 14, 2025Reward models (RMs) play a crucial role in Reinforcement Learning from Human Feedback by serving as proxies for human preferences in aligning large language models. In this paper, we identify a model preference bias in RMs, where they systematically assign disproportionately high scores to responses from certain policy models. This bias distorts ranking evaluations and leads to unfair judgments. To address this issue, we propose a calibration method named CHatbot Arena calibrated Reward Modeling (CHARM) that leverages Elo scores from the Chatbot Arena leaderboard to mitigate RM overvaluation. We also introduce a Mismatch Degree metric to measure this preference bias. Our approach is computationally efficient, requiring only a small preference dataset for continued training of the RM. We conduct extensive experiments on reward model benchmarks and human preference alignment. Results demonstrate that our calibrated RMs (1) achieve improved evaluation accuracy on RM-Bench and the Chat-Hard domain of RewardBench, and (2) exhibit a stronger correlation with human preferences by producing scores more closely aligned with Elo rankings. By mitigating model preference bias, our method provides a generalizable and efficient solution for building fairer and more reliable reward models.
ELF-Gym: Evaluating Large Language Models Generated Features for Tabular Prediction
Oct 13, 2024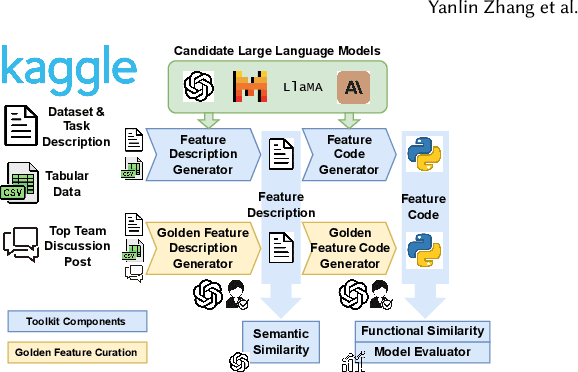
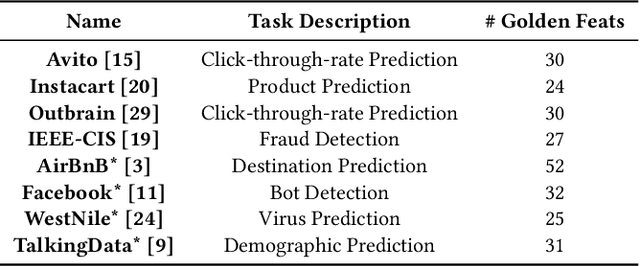
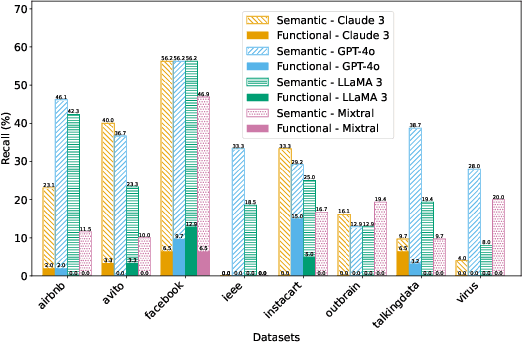
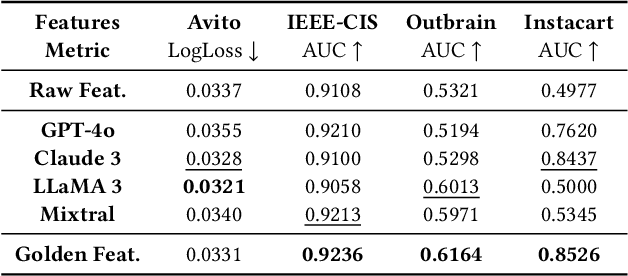
Crafting effective features is a crucial yet labor-intensive and domain-specific task within machine learning pipelines. Fortunately, recent advancements in Large Language Models (LLMs) have shown promise in automating various data science tasks, including feature engineering. But despite this potential, evaluations thus far are primarily based on the end performance of a complete ML pipeline, providing limited insight into precisely how LLMs behave relative to human experts in feature engineering. To address this gap, we propose ELF-Gym, a framework for Evaluating LLM-generated Features. We curated a new dataset from historical Kaggle competitions, including 251 "golden" features used by top-performing teams. ELF-Gym then quantitatively evaluates LLM-generated features by measuring their impact on downstream model performance as well as their alignment with expert-crafted features through semantic and functional similarity assessments. This approach provides a more comprehensive evaluation of disparities between LLMs and human experts, while offering valuable insights into specific areas where LLMs may have room for improvement. For example, using ELF-Gym we empirically demonstrate that, in the best-case scenario, LLMs can semantically capture approximately 56% of the golden features, but at the more demanding implementation level this overlap drops to 13%. Moreover, in other cases LLMs may fail completely, particularly on datasets that require complex features, indicating broad potential pathways for improvement.
4DBInfer: A 4D Benchmarking Toolbox for Graph-Centric Predictive Modeling on Relational DBs
Apr 28, 2024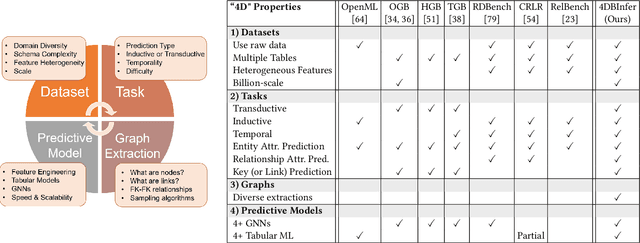
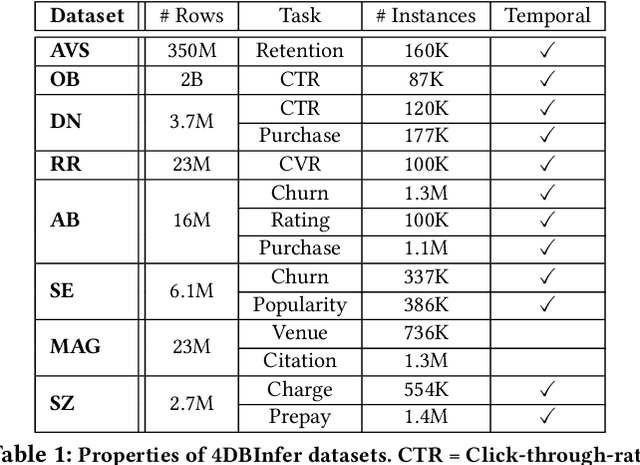
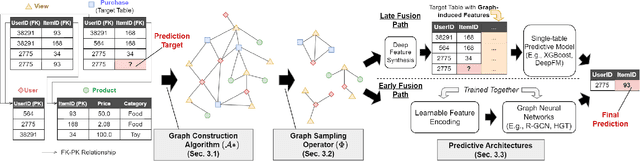
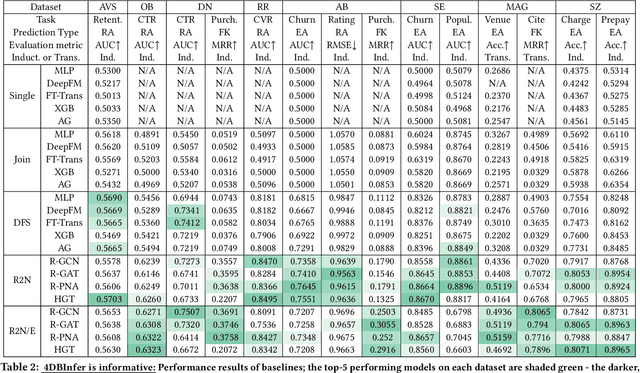
Although RDBs store vast amounts of rich, informative data spread across interconnected tables, the progress of predictive machine learning models as applied to such tasks arguably falls well behind advances in other domains such as computer vision or natural language processing. This deficit stems, at least in part, from the lack of established/public RDB benchmarks as needed for training and evaluation purposes. As a result, related model development thus far often defaults to tabular approaches trained on ubiquitous single-table benchmarks, or on the relational side, graph-based alternatives such as GNNs applied to a completely different set of graph datasets devoid of tabular characteristics. To more precisely target RDBs lying at the nexus of these two complementary regimes, we explore a broad class of baseline models predicated on: (i) converting multi-table datasets into graphs using various strategies equipped with efficient subsampling, while preserving tabular characteristics; and (ii) trainable models with well-matched inductive biases that output predictions based on these input subgraphs. Then, to address the dearth of suitable public benchmarks and reduce siloed comparisons, we assemble a diverse collection of (i) large-scale RDB datasets and (ii) coincident predictive tasks. From a delivery standpoint, we operationalize the above four dimensions (4D) of exploration within a unified, scalable open-source toolbox called 4DBInfer. We conclude by presenting evaluations using 4DBInfer, the results of which highlight the importance of considering each such dimension in the design of RDB predictive models, as well as the limitations of more naive approaches such as simply joining adjacent tables. Our source code is released at https://github.com/awslabs/multi-table-benchmark .