 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELF-Gym: Evaluating Large Language Models Generated Features for Tabular Prediction
Paper and Code
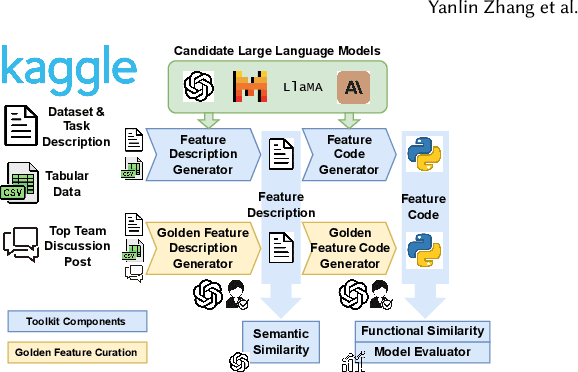
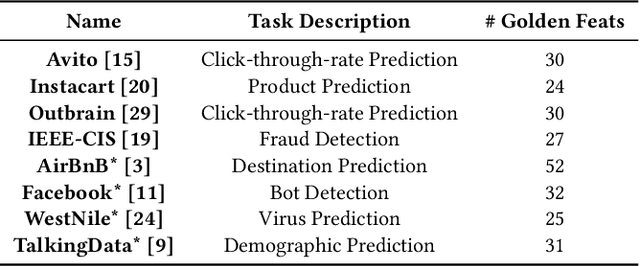
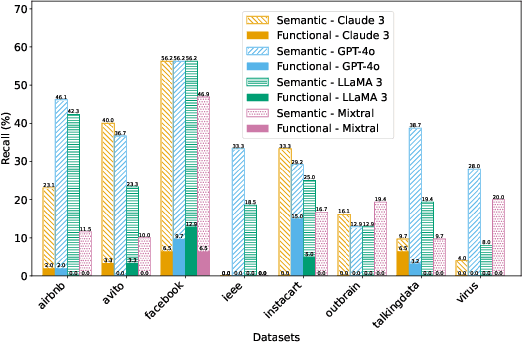
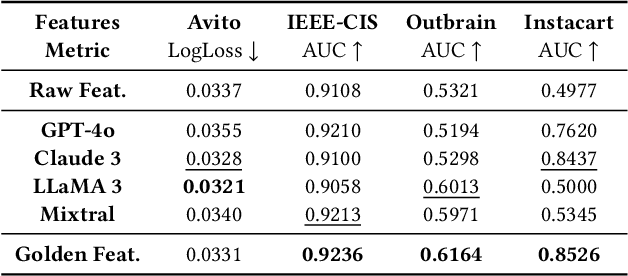
Crafting effective features is a crucial yet labor-intensive and domain-specific task within machine learning pipelines. Fortunately, recent advancements in Large Language Models (LLMs) have shown promise in automating various data science tasks, including feature engineering. But despite this potential, evaluations thus far are primarily based on the end performance of a complete ML pipeline, providing limited insight into precisely how LLMs behave relative to human experts in feature engineering. To address this gap, we propose ELF-Gym, a framework for Evaluating LLM-generated Features. We curated a new dataset from historical Kaggle competitions, including 251 "golden" features used by top-performing teams. ELF-Gym then quantitatively evaluates LLM-generated features by measuring their impact on downstream model performance as well as their alignment with expert-crafted features through semantic and functional similarity assessments. This approach provides a more comprehensive evaluation of disparities between LLMs and human experts, while offering valuable insights into specific areas where LLMs may have room for improvement. For example, using ELF-Gym we empirically demonstrate that, in the best-case scenario, LLMs can semantically capture approximately 56% of the golden features, but at the more demanding implementation level this overlap drops to 13%. Moreover, in other cases LLMs may fail completely, particularly on datasets that require complex features, indicating broad potential pathways for improvement.