 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025


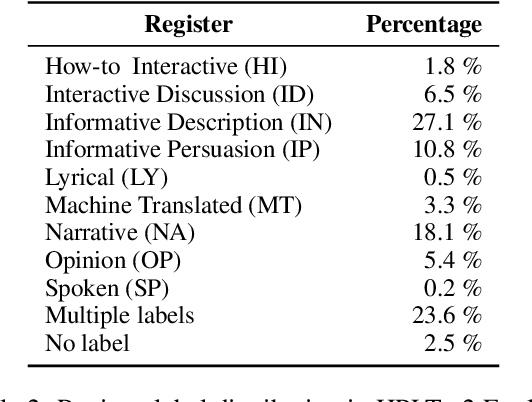
Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Pitfalls and Outlooks in Using COMET
Sep 02, 2024



Since its introduction, the COMET metric has blazed a trail in the machine translation community, given its strong correlation with human judgements of translation quality. Its success stems from being a modified pre-trained multilingual model finetuned for quality assessment. However, it being a machine learning model also gives rise to a new set of pitfalls that may not be widely known. We investigate these unexpected behaviours from three aspects: 1) technical: obsolete software versions and compute precision; 2) data: empty content, language mismatch, and translationese at test time as well as distribution and domain biases in training; 3) usage and reporting: multi-reference support and model referencing in the literature. All of these problems imply that COMET scores is not comparable between papers or even technical setups and we put forward our perspective on fixing each issue. Furthermore, we release the SacreCOMET package that can generate a signature for the software and model configuration as well as an appropriate citation. The goal of this work is to help the community make more sound use of the COMET metric.
Machine Translation Meta Evaluation through Translation Accuracy Challenge Sets
Jan 29, 2024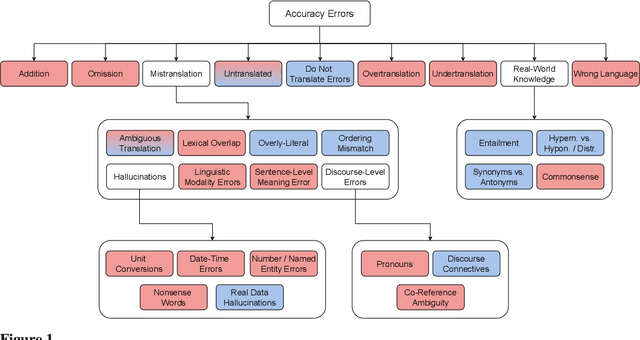

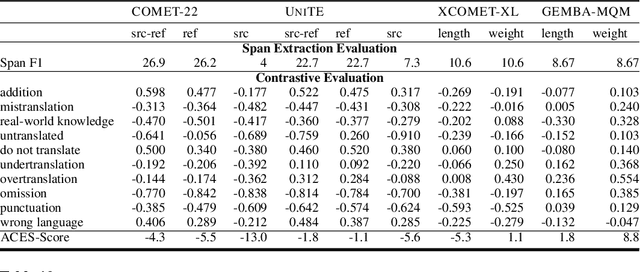
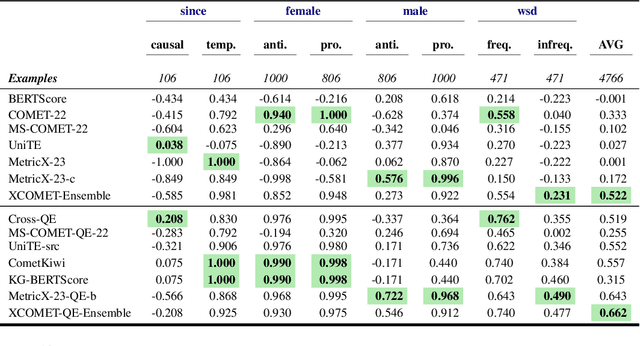
Recent machine translation (MT) metrics calibrate their effectiveness by correlating with human judgement but without any insights about their behaviour across different error types. Challenge sets are used to probe specific dimensions of metric behaviour but there are very few such datasets and they either focus on a limited number of phenomena or a limited number of language pairs. We introduce ACES, a contrastive challenge set spanning 146 language pairs, aimed at discovering whether metrics can identify 68 translation accuracy errors. These phenomena range from simple alterations at the word/character level to more complex errors based on discourse and real-world knowledge. We conduct a large-scale study by benchmarking ACES on 50 metrics submitted to the WMT 2022 and 2023 metrics shared tasks. We benchmark metric performance, assess their incremental performance over successive campaigns, and measure their sensitivity to a range of linguistic phenomena. We also investigate claims that Large Language Models (LLMs) are effective as MT evaluators by evaluating on ACES. Our results demonstrate that different metric families struggle with different phenomena and that LLM-based methods fail to demonstrate reliable performance. Our analyses indicate that most metrics ignore the source sentence, tend to prefer surface-level overlap and end up incorporating properties of base models which are not always beneficial. We expand ACES to include error span annotations, denoted as SPAN-ACES and we use this dataset to evaluate span-based error metrics showing these metrics also need considerable improvement. Finally, we provide a set of recommendations for building better MT metrics, including focusing on error labels instead of scores, ensembling, designing strategies to explicitly focus on the source sentence, focusing on semantic content and choosing the right base model for representations.
Interpreting User Requests in the Context of Natural Language Standing Instructions
Nov 16, 2023Users of natural language interfaces, generally powered by Large Language Models (LLMs),often must repeat their preferences each time they make a similar request. To alleviate this, we propose including some of a user's preferences and instructions in natural language -- collectively termed standing instructions -- as additional context for such interfaces. For example, when a user states I'm hungry, their previously expressed preference for Persian food will be automatically added to the LLM prompt, so as to influence the search for relevant restaurants. We develop NLSI, a language-to-program dataset consisting of over 2.4K dialogues spanning 17 domains, where each dialogue is paired with a user profile (a set of users specific standing instructions) and corresponding structured representations (API calls). A key challenge in NLSI is to identify which subset of the standing instructions is applicable to a given dialogue. NLSI contains diverse phenomena, from simple preferences to interdependent instructions such as triggering a hotel search whenever the user is booking tickets to an event. We conduct experiments on NLSI using prompting with large language models and various retrieval approaches, achieving a maximum of 44.7% exact match on API prediction. Our results demonstrate the challenges in identifying the relevant standing instructions and their interpretation into API calls.
ACES: Translation Accuracy Challenge Sets at WMT 2023
Nov 02, 2023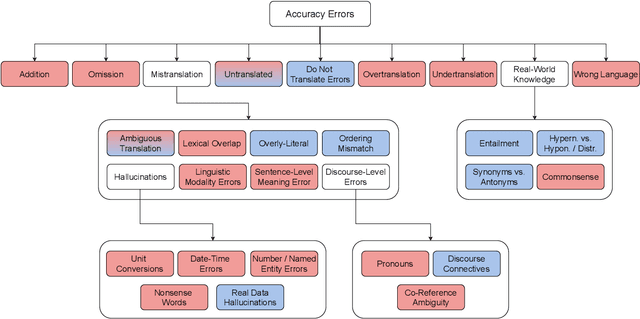


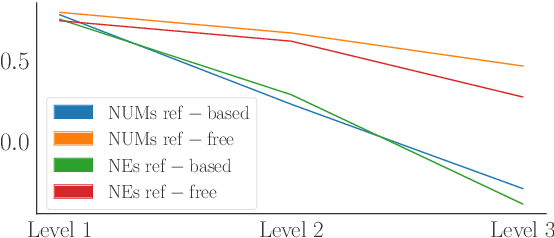
We benchmark the performance of segmentlevel metrics submitted to WMT 2023 using the ACES Challenge Set (Amrhein et al., 2022). The challenge set consists of 36K examples representing challenges from 68 phenomena and covering 146 language pairs. The phenomena range from simple perturbations at the word/character level to more complex errors based on discourse and real-world knowledge. For each metric, we provide a detailed profile of performance over a range of error categories as well as an overall ACES-Score for quick comparison. We also measure the incremental performance of the metrics submitted to both WMT 2023 and 2022. We find that 1) there is no clear winner among the metrics submitted to WMT 2023, and 2) performance change between the 2023 and 2022 versions of the metrics is highly variable. Our recommendations are similar to those from WMT 2022. Metric developers should focus on: building ensembles of metrics from different design families, developing metrics that pay more attention to the source and rely less on surface-level overlap, and carefully determining the influence of multilingual embeddings on MT evaluation.
MULTI3NLU++: A Multilingual, Multi-Intent, Multi-Domain Dataset for Natural Language Understanding in Task-Oriented Dialogue
Dec 20, 2022



Task-oriented dialogue (TOD) systems have been applied in a range of domains to support human users to achieve specific goals. Systems are typically constructed for a single domain or language and do not generalise well beyond this. Their extension to other languages in particular is restricted by the lack of available training data for many of the world's languages. To support work on Natural Language Understanding (NLU) in TOD across multiple languages and domains simultaneously, we constructed MULTI3NLU++, a multilingual, multi-intent, multi-domain dataset. MULTI3NLU++ extends the English-only NLU++ dataset to include manual translations into a range of high, medium and low resource languages (Spanish, Marathi, Turkish and Amharic), in two domains (banking and hotels). MULTI3NLU++ inherits the multi-intent property of NLU++, where an utterance may be labelled with multiple intents, providing a more realistic representation of a user's goals and aligning with the more complex tasks that commercial systems aim to model. We use MULTI3NLU++ to benchmark state-of-the-art multilingual language models as well as Machine Translation and Question Answering systems for the NLU task of intent detection for TOD systems in the multilingual setting. The results demonstrate the challenging nature of the dataset, particularly in the low-resource language setting.
Extrinsic Evaluation of Machine Translation Metrics
Dec 20, 2022



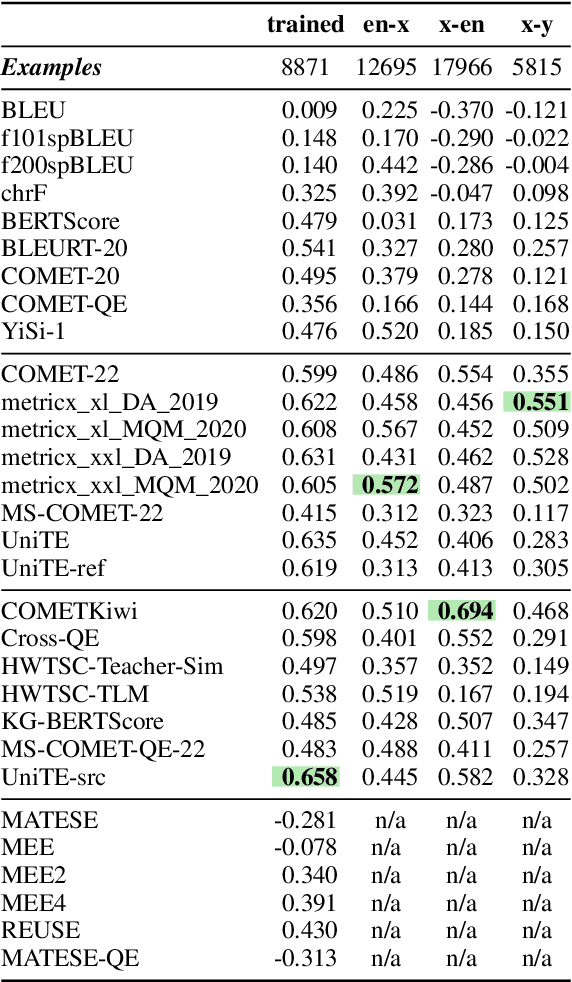
Automatic machine translation (MT) metrics are widely used to distinguish the translation qualities of machine translation systems across relatively large test sets (system-level evaluation). However, it is unclear if automatic metrics are reliable at distinguishing good translations from bad translations at the sentence level (segment-level evaluation). In this paper, we investigate how useful MT metrics are at detecting the success of a machine translation component when placed in a larger platform with a downstream task. We evaluate the segment-level performance of the most widely used MT metrics (chrF, COMET, BERTScore, etc.) on three downstream cross-lingual tasks (dialogue state tracking, question answering, and semantic parsing). For each task, we only have access to a monolingual task-specific model. We calculate the correlation between the metric's ability to predict a good/bad translation with the success/failure on the final task for the Translate-Test setup. Our experiments demonstrate that all metrics exhibit negligible correlation with the extrinsic evaluation of the downstream outcomes. We also find that the scores provided by neural metrics are not interpretable mostly because of undefined ranges. Our analysis suggests that future MT metrics be designed to produce error labels rather than scores to facilitate extrinsic evaluation.
ACES: Translation Accuracy Challenge Sets for Evaluating Machine Translation Metrics
Oct 27, 2022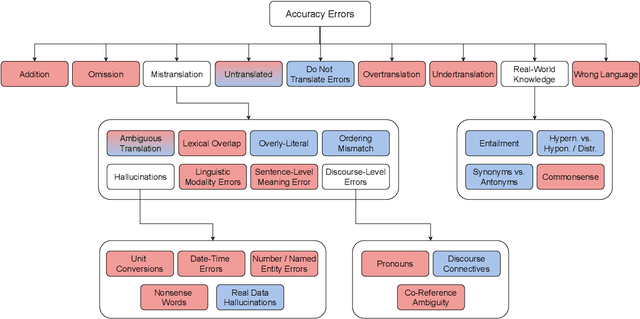
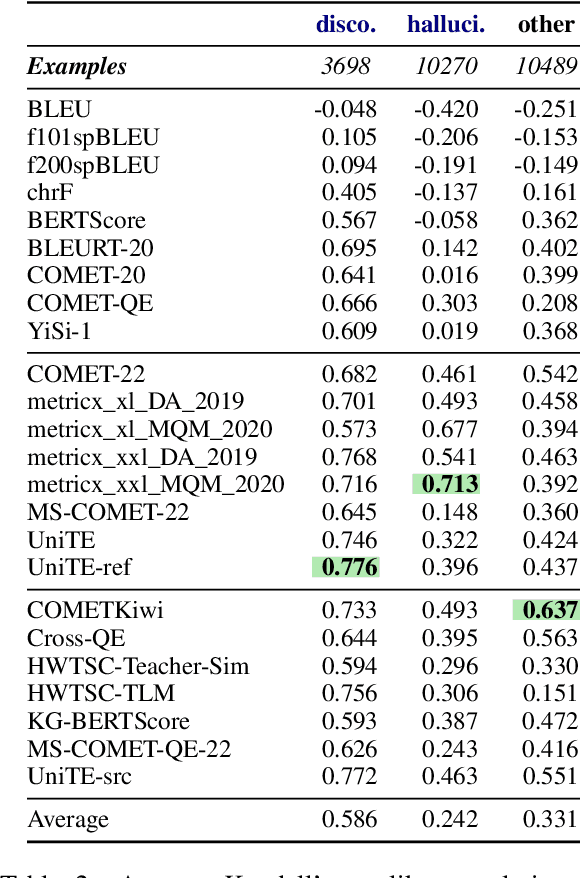
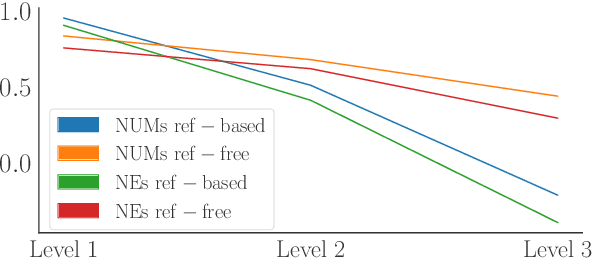
As machine translation (MT) metrics improve their correlation with human judgement every year, it is crucial to understand the limitations of such metrics at the segment level. Specifically, it is important to investigate metric behaviour when facing accuracy errors in MT because these can have dangerous consequences in certain contexts (e.g., legal, medical). We curate ACES, a translation accuracy challenge set, consisting of 68 phenomena ranging from simple perturbations at the word/character level to more complex errors based on discourse and real-world knowledge. We use ACES to evaluate a wide range of MT metrics including the submissions to the WMT 2022 metrics shared task and perform several analyses leading to general recommendations for metric developers. We recommend: a) combining metrics with different strengths, b) developing metrics that give more weight to the source and less to surface-level overlap with the reference and c) explicitly modelling additional language-specific information beyond what is available via multilingual embeddings.
Cross-lingual Intermediate Fine-tuning improves Dialogue State Tracking
Sep 28, 2021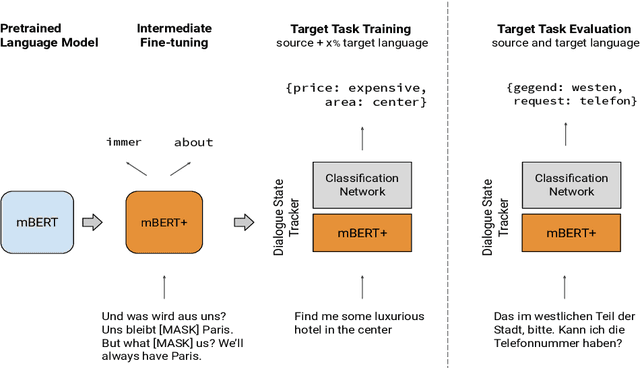

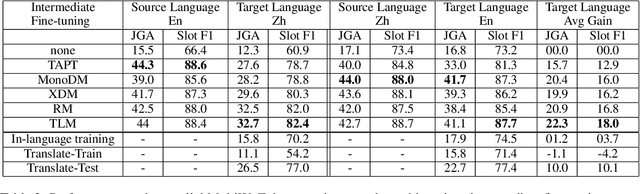
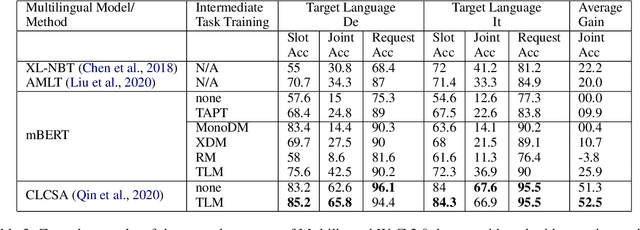
Recent progress in task-oriented neural dialogue systems is largely focused on a handful of languages, as annotation of training data is tedious and expensive. Machine translation has been used to make systems multilingual, but this can introduce a pipeline of errors. Another promising solution is using cross-lingual transfer learning through pretrained multilingual models. Existing methods train multilingual models with additional code-mixed task data or refine the cross-lingual representations through parallel ontologies. In this work, we enhance the transfer learning process by intermediate fine-tuning of pretrained multilingual models, where the multilingual models are fine-tuned with different but related data and/or tasks. Specifically, we use parallel and conversational movie subtitles datasets to design cross-lingual intermediate tasks suitable for downstream dialogue tasks. We use only 200K lines of parallel data for intermediate fine-tuning which is already available for 1782 language pairs. We test our approach on the cross-lingual dialogue state tracking task for the parallel MultiWoZ (English -> Chinese, Chinese -> English) and Multilingual WoZ (English -> German, English -> Italian) datasets. We achieve impressive improvements (> 20% on joint goal accuracy) on the parallel MultiWoZ dataset and the Multilingual WoZ dataset over the vanilla baseline with only 10% of the target language task data and zero-shot setup respectively.
On Incorporating Structural Information to improve Dialogue Response Generation
May 28, 2020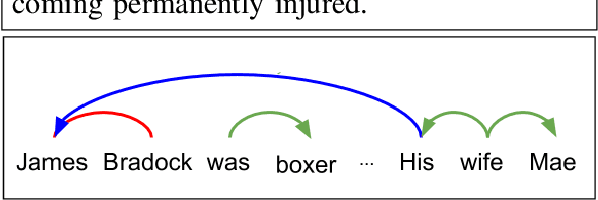
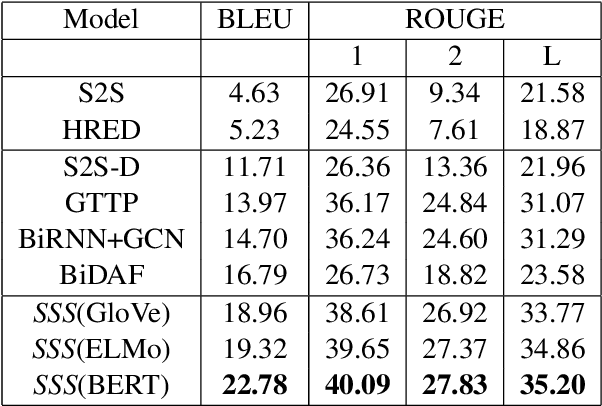
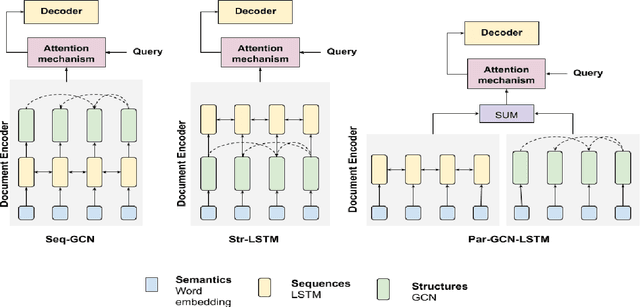
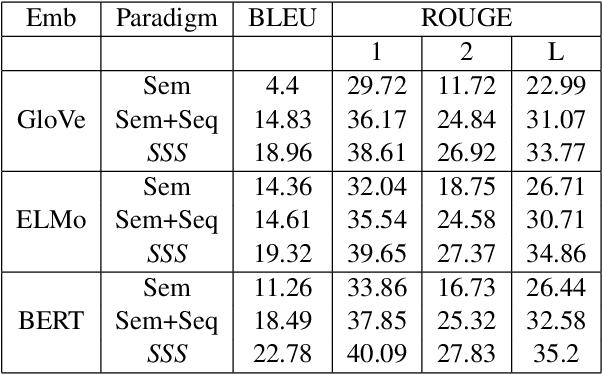
We consider the task of generating dialogue responses from background knowledge comprising of domain specific resources. Specifically, given a conversation around a movie, the task is to generate the next response based on background knowledge about the movie such as the plot, review, Reddit comments etc. This requires capturing structural, sequential and semantic information from the conversation context and the background resources. This is a new task and has not received much attention from the community. We propose a new architecture that uses the ability of BERT to capture deep contextualized representations in conjunction with explicit structure and sequence information. More specifically, we use (i) Graph Convolutional Networks (GCNs) to capture structural information, (ii) LSTMs to capture sequential information and (iii) BERT for the deep contextualized representations that capture semantic information. We analyze the proposed architecture extensively. To this end, we propose a plug-and-play Semantics-Sequences-Structures (SSS) framework which allows us to effectively combine such linguistic information. Through a series of experiments we make some interesting observations. First, we observe that the popular adaptation of the GCN model for NLP tasks where structural information (GCNs) was added on top of sequential information (LSTMs) performs poorly on our task. This leads us to explore interesting ways of combining semantic and structural information to improve the performance. Second, we observe that while BERT already outperforms other deep contextualized representations such as ELMo, it still benefits from the additional structural information explicitly added using GCNs. This is a bit surprising given the recent claims that BERT already captures structural information. Lastly, the proposed SSS framework gives an improvement of 7.95% over the baseline.